标签:ref pre 学习 小说 request logs dal 星空 获取
??在一节中,我们学习了如果通过正则表达式来获取HTML里面指点便签的内容, 那么我今天就来看看实际的效果.在抓取小说之前, 我们需要知道小说有哪些章节,以及这些章节的顺序.
??刚开始我是通过获取一个章节, 然后从这个章节获取下个章节的链接, 然后发现这个方法问题很大.
后来发现我发现可以直接通过目录来获取全部章节的目录.话不多说,开始我们今天的任务, 获取URLs
import requests
r = requests.get('http://www.biquger.com/biquge/12928/')
r.encoding = 'utf-8'
print(r.text)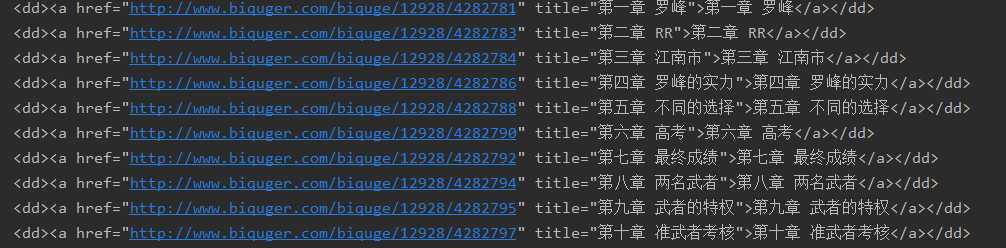
通过观察下载的html源码, 可以发现, 所有的URL都以:
<dd><a href="http://www.biquger.com/biquge/12928/4282781" title="第一章 罗峰">第一章 罗峰</a></dd>我们只需要获取所有和上述格式一样的内容即可
在第二节的学习中, 我们学习了获取全部链接应该使用re中的findall(p, text)来实现.
import re
res = re.findall('<dd><a href="(.*?)".*?>(.*?)</a></dd>', r.text)
for i in res:
print(i)上述正则表达式<dd><a href="(.*?)".*?>(.*?)</a></dd>中, 第一括号是为了提取网页的链接, 第二括号是为了提取标题., 这样一来我们就获得了, 所有章节的标题以及对应url, 下面我们将其输入为list, 以方便我们后面使用.
index, ans = 1, []
for i in res:
ans.append((i[0], str(index).zfill(4) + i[1]))
index = index + 1
print(ans[-1])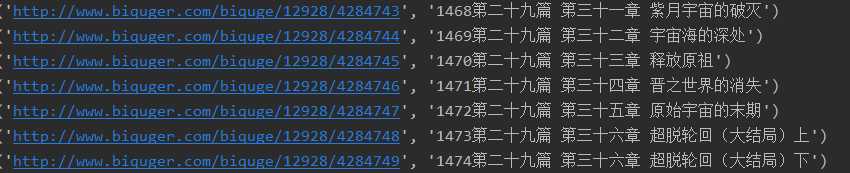
这样我们就获取到我们需要的url以及对应标题的列表了, 其中i[0]为url, i[1] 为标题.很多人可能会有疑问, 为什么在标题前要加序号?标题是我们保存章节的文件名, 我们必须保证其有序性, 而序号就是起到这个作用.
到这里,今天的内容就学习完毕了, 下面把我们今天学到内容,整理成一个函数, 方便后面继续使用.
def getContents(url):
r = requests.get(url)
r.encoding = 'utf-8'
res = re.findall('<dd><a href="(.*?)".*?>(.*?)</a></dd>', r.text)
index, ans = 1, []
for i in res:
ans.append((i[0], str(index).zfill(4) + i[1]))
index = index + 1
return ans标签:ref pre 学习 小说 request logs dal 星空 获取
原文地址:https://www.cnblogs.com/blogcyh/p/12283928.html