标签:实现 add com 数值 inf 字典实现 多分支 lis VID
由于我刚开始学习Python时,被序列结构转晕了,所以写了这篇博客。
随便翻开一本英语单词书,你就会看到这样的画面:

我们能观察到,这页单词书的排版方式是左边一个单词,右边是它的意思,单词和意思是相互对应的,这种排版方式可以帮助我们很好地理解字典结构。
字典是一系列键——值对。每个键都与一个值相关联,你可以使用键来访问与之相关联的值。与键相关联的值可以是任意Python对象,包括数字、字符串、列表和字典。
字典用放在花括号“{ }”的一系列键——值对表示,每个元素都包含“键”和“值”,“键”和“值”之间用冒号分隔,相邻两个元素用逗号分隔。在字典中,你可以存储任意数量的键——值对。例如以我的期末考试成绩创建一个字典:
my_grade = {'C language': 39, 'English': 19,'math': 29 ,'modern history': 95}
print(my_grade)输出结果:
{'C language': 39, 'English': 19,'math': 29 ,'modern history': 95}*Pyhton的字典结构相当于Java或C++语言中的Map对象。
想要访问与键相对应的值,可依次指定字典名和放在方括号内的键,可以用列表的索引来类比,只不过这里的索引是“键”,例如:
my_grade = {'C language': 39, 'English': 19,'math': 29 ,'modern history': 95}
print(my_grade['C language'])Python将返回字典中与键相对应的值,输出结果为:
39和列表类似,字典是一个动态结构,我们可以随时在其中添加键——值对。添加键——值对时,需要依次指定字典名、用方括号括起来的键和对应的值。在实际应用当中经常需要先建立一个空字典,例如我们需要集成用户输入的数据,然后再依次把键——值对添加到字典当中,例如:
my_grade = {} #建立空字典
my_grade['C language'] = 39
my_grade['English'] = 19
my_grade['math'] = 29
my_grade['modern history'] = 95
print(my_grade)输出结果:
{'C language': 39, 'English': 19,'math': 29 ,'modern history': 95}修改字典中的值的写法与添加键值对的写法相同,也是需要依次指定字典名、用方括号括起来的键和对应的新值。例如:
my_grade = {'C language': 60, 'English': 19,'math': 29 ,'modern history': 95}
my_grade['C language'] = 39
print(my_grade)输出结果:
{'C language': 39, 'English': 19,'math': 29 ,'modern history': 95}使用del语句删除字典中的键——值对,使用时要指定字典名和要删除的键。例如:
my_grade = {'C language': 39, 'English': 19,'math': 29 ,'modern history': 95, 'PE' : 0}
del my_grade['PE']
print(my_grade)输出结果:
{'C language': 39, 'English': 19,'math': 29 ,'modern history': 95}当我们想要遍历键——值对时,由于键和值会被我们同时遍历,所以需要分别定义两个变量来存储。同时我们还需要使用“.items()”方法,该方法以列表返回可遍历的(键, 值) 元组数组,语法为:
dict.items()| 参数 | 说明 |
|---|---|
| dict | 需要被操作的字典 |
为了直观地看出.items()方法的作用,我们写一段代码来看看:
my_grade = {'C language': 39, 'English': 19,'math': 29 ,'modern history': 95}
print(my_grade.items())输出结果为:
my_grade([('C language', 39), ('English', 19), ('math', 29), ('modern history', 95)])我们还是使用for 循环结构来遍历字典:
my_grade = {'C language': 39, 'English': 19,'math': 29 ,'modern history': 95}
for key, value in my_grade.items():
print("Key: " + key)
print("Value: ",value,"\n")遍历时,“.items()”方法返回的键——值对列表,会被依次存储进我们定义分别用来存储键和值的变量中。输出结果为:
Key: C language
Value: 39
Key: English
Value: 19
Key: math
Value: 29
Key: modern history
Value: 95 在不需要使用字典的值的时候,我们使用“.key()”方法,该方法返回一个可迭代对象,可以使用 list() 来转换为列表。语法为:
dict.keys()| 参数 | 说明 |
|---|---|
| dict | 需要被操作的字典 |
为了直观地看出.key()方法的作用,我们写一段代码来看看:
my_grade = {'C language': 39, 'English': 19,'math': 29 ,'modern history': 95}
print(list(my_grade.keys()) )输出结果为:
['C language', 'English', 'math', 'modern history']我们还是使用for 循环结构来遍历字典:
my_grade = {'C language': 39, 'English': 19,'math': 29 ,'modern history': 95}
for key in my_grade.keys():
print("Key: " + key)输出结果:
Key: C language
Key: English
Key: math
Key: modern history其实当我们遍历字典时,会默认遍历字典中的所有键,所以你把代码写成这样子,输出的内容是一样的:
my_grade = {'C language': 39, 'English': 19,'math': 29 ,'modern history': 95}
for key in my_grade:
print("Key: " + key)使用“.values()”方法,该方法返回一个迭代器,可以使用 list() 来转换为列表,列表为字典中的所有值,语法为:
dict.values()| 参数 | 说明 |
|---|---|
| dict | 需要被操作的字典 |
为了直观地看出.key()方法的作用,我们写一段代码来看看:
my_grade = {'C language': 39, 'English': 19,'math': 29 ,'modern history': 95}
print(list(my_grade.values()) )输出结果为:
[39, 19, 29, 95]我们还是使用for 循环结构来遍历字典:
my_grade = {'C language': 39, 'English': 19,'math': 29 ,'modern history': 95}
for value in my_grade.values():
print("Values: ",value)输出结果为:
Values: 39
Values: 19
Values: 29
Values: 95首先我们认识一下zip()函数,,该函数用于将可迭代的对象作为参数,例如多个列表或元组,将对象中对应的元素组合为元组,然后返回组成的列表。如果各个迭代器的元素个数不一致,则返回列表长度与最短的对象相同,利用 * 号操作符,可以将元组解压为列表。语法为:
zip([iterable, ...])| 参数 | 说明 |
|---|---|
| iterable | 一个或多个迭代器 |
利用zip()函数创建字典的语法为:
dictionary = dict(zip(list1,list2))| 参数 | 说明 |
|---|---|
| dictionary | 要创建的字典名称 |
| list1 | 表示一个用于指定要生成字典的键的列表 |
| list2 | 表示一个用于指定要生成字典的值的列表 |
我们试着用这种写法创建一个字典:
subject = ['C language', 'English','math' ,'modern history']
grade = [39, 19, 29, 95]
my_grade = dict(zip(subject, grade))
print(my_grade)输出结果为:
{'C language': 39, 'English': 19, 'math': 29, 'modern history': 95}看到“集合”这两个字,你是否会想起高中被数学支配的恐惧?

你猜的没错,Python中的集合与高中的集合概念相类似,是用于保存不重复的元素的序列结构。
集合是一个无序的不重复元素序列,集合是可变序列,可以使用大括号 { } 或者 set() 函数创建集合,如果想要创建一个空集合,则必须用 set(),因为 { } 会被认为是创建一个空字典例如:
Subject = {'Chinese', 'Mathematics', 'English', 'Physics', 'Chemistry', 'Biology'}
print(Subject)输出结果为:
{'Chemistry', 'Biology', 'Physics', 'Mathematics', 'Chinese', 'English'}Subject = {'Chinese', 'Mathematics', 'English', 'Chinese', 'Mathematics', 'English'}
print(Subject)输出结果为:
{'English', 'Chinese', 'Mathematics'}由此可见,Python对于集合中重复的元素只会保留一个。
set() 函数创建一个无序不重复元素集,返回值为新的集合对象。语法为:
a_set = set([iterable])| 参数 | 说明 |
|---|---|
| a_set | 要创建的集合名称 |
| iterable | 可迭代对象对象 |
例如:
Subject = set(['Chinese', 'Mathematics', 'English', 'Physics', 'Chemistry', 'Biology'])使用len()函数,该函数将返回对象(字符、列表、元组等)长度或项目个数。语法为:
len( s )| 参数 | 说明 |
|---|---|
| s | 对象 |
使用“.add()”方法,该方法用于给集合添加元素,无返回值,如果添加的元素在集合中已存在,则不执行任何操作。语法为:
set.add(elmnt)| 参数 | 说明 |
|---|---|
| set | 要创建的集合名称 |
| elmnt | 要添加的元素 |
例如:
Subject = {'Chinese', 'Mathematics', 'English', 'Physics', 'Chemistry'}
Subject.add('Biology')
print(Subject)
Subject.add('Biology') #该语句不产生任何操作
print(Subject)输出结果为:
{'Mathematics', 'Chinese', 'Biology', 'English', 'Chemistry', 'Physics'}
{'Mathematics', 'Chinese', 'Biology', 'English', 'Chemistry', 'Physics'}使用pop()方法,该方法用于随机移除一个元素,返回值为移除的元素。语法为:
set.pop()| 参数 | 说明 |
|---|---|
| set | 要操作的集合 |
例如:
Subject = {'Chinese', 'Mathematics', 'English', 'Physics', 'Chemistry', 'Biology'}
x = Subject.pop()
print(Subject,x)输出结果为:
{'Physics', 'Mathematics', 'Biology', 'English', 'Chemistry'} Chineseremove() 方法或discard() 方法,这两种方法都用于移除集合中的指定元素。不同点在于remove()方法在移除一个不存在的元素时会发生错误,且会返回被删除的元素,而discard()方法不会。语法为:
set.discard(value)
set.remove(value)| 参数 | 说明 |
|---|---|
| set | 要操作的集合 |
| value | 要移除的元素 |
例如:
Subject = {'Chinese', 'Mathematics', 'English', 'Physics', 'Chemistry'}
Subject.discard('Physics')
Subject.remove('Chemistry')
print(Subject)输出结果为:
{'Mathematics', 'Chinese', 'English'}使用del语句删除整个集合,语法为:
Subject = {'Chinese', 'Mathematics', 'English', 'Physics', 'Chemistry', 'Biology'}
del Subject使用clear()方法,该方法用于移除集合中的所有元素。语法为:
set.clear()| 参数 | 说明 |
|---|---|
| set | 要操作的集合 |
例如:
Subject = {'Chinese', 'Mathematics', 'English', 'Physics', 'Chemistry', 'Biology'}
Subject.clear()
print(Subject)输出结果为:
set()集合进行交集运算时使用“&”符号,进行并集运算时使用“|”符号:进行差集运算时使用“-”符号,进行对称差集运算时使用“^”符号。例如:
Subject1 = {'Chinese', 'Mathematics', 'English', 'Physics', 'Chemistry', 'Biology'}
Subject2 = {'Chinese', 'Mathematics', 'English', 'History', 'geography', 'Politics'}
print(Subject1 & Subject2) #交集运算
print(Subject1 | Subject2) #并集运算
print(Subject1 - Subject2) #差集运算
print(Subject1 ^ Subject2) #对称差集运算输出结果为:
{'English', 'Chinese', 'Mathematics'}
{'Chinese', 'Chemistry', 'Politics', 'geography', 'Biology', 'Physics', 'Mathematics', 'English', 'History'}
{'Biology', 'Chemistry', 'Physics'}
{'Biology', 'Chemistry', 'Physics', 'Politics', 'History', 'geography'}| 函数 | 功能 |
|---|---|
| intersection() | 返回集合的交集 |
| difference() | 返回多个集合的差集 |
| union() | 返回两个集合的并集 |
《Python从入门到精通》————明日科技,清华大学出版社
《Python编程从入门到实践》————[美]Eric Matthes 著,袁国忠 译,人民邮电出版社
菜鸟教程
题目选择于PTA题库。

输入样例:
7
/
3输出样例:
2.33拿到这道题,我们的第一反应应该是来个多分支结构,然后根据运算符的不同进入不同的分支。这么做当然可以,但是题目要求用字典实现,这就很令人苦恼了。
类比C语言的“switch”多分支结构,我们可以通过常量表达式,直接进入不同的分支,这与字典有所相同之处。字典的键就与“switch”结构的常量表达式有相同的地方,我们访问字典中的值都是通过键来访问的,针对这道题,我们只需要让字典中访问的值是一个运算式,即可实现题目的要求。别忘了这道题要异常处理,要try一下。


输入样例:
[4,7,5,6,8,6,9,5] 输出样例:
4 7 5 6 8 9如果这题是出在C语言的题集,那我们得花上好一会才能解决。然而我们现在用的是Python,思路是很明确的,我们直接把这个列表转成集合,直接一步到位。
但是此时解题还没有结束,因为题目要求按原来次序输出,大家可以试试看,转换成集合之后输出的顺序是随机的,就算我们转回了列表,里面元素的顺序已经不是原来的顺序了。解决方法是在列表去重之前,先保存一个副本,然后将去重后的列表按照去重前的列表为规则排序,再输出。
所以这道题真正的难点是按原来的次序给列表排序(笑)!
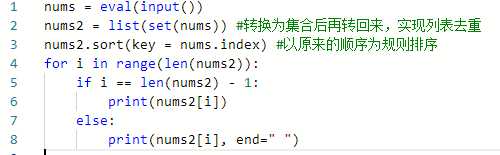

输入样例
学校 城市 邮编
集美大学 厦门 361021输出样例
[('城市', '厦门'), ('学校', '集美大学'), ('邮编', '361021')]思路是很自然的,我们给输入的两行数据分割一下,转成列表,然后用映射函数建立字典即可。如果你用一个for循环结构来建立也可以。


输入样例
5
1 2 3 4 5
1 3 2 5 4
1 2 3 6 1
1 2 3 2 1
1 1 1 1 1输出样例
True=3, False=2如果这道题拿到C语言里面的话,那又是一件很麻烦的事情了,我们会用循环一个一个比较。但是在Python我们有集合结构,思路是很自然的,我们拷贝一份输入的列表,然后转换成集合,把这两个的长度进行比较,即可得知是否含有重复的元素了。
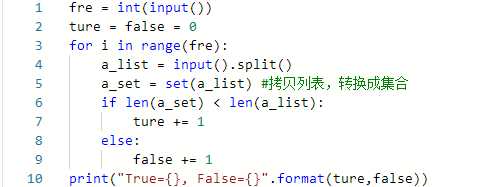

输入样例:
3
Mike Alan Lucy
Mike Lily Meg
Lily Mike Meg Lily输出样例
[('Mike', 3), ('Lily', 2), ('Meg', 2), ('Lucy', 1), ('Alan', 1)]我们要统计每个人的投票数,那么每个候选人和得票数是一个对应关系,因此我们优先选择字典结构来解决这个问题。我们先建立一个空字典,字典的键是候选人,值是得票数,然后遍历单个投票名单,如果候选人出现过就让对应的值加1,如果没有出现过,就添加一个新的键,对应的值为数值1。
由于一行候选人可能会有重复出现的情况,因此输入的数据应该转成集合,过滤一下重复的候选人。输出的时候以得票数为规则降序排序一下字典即可。

输入样例
failure is probably the fortification in your pole
it is like a peek your wallet as the thief when you
are thinking how to spend several hard-won lepta
when you are wondering whether new money it has laid
background because of you then at the heart of the
most lax alert and most low awareness and left it
godsend failed
!!!!!输出样例
46
the=4
it=3
you=3
and=2
are=2
is=2
most=2
of=2
when=2
your=2这道题表面上很难,其实是唬人的,一个单词和它的出现次数是一个对应的关系,因此我们优先考虑使用字典结构。先建立一个空字典,然后以单词作为键,出现此处作为值,单词没多出现一次值就加1即可完成。
因此这道题的难点其实是在于文段的准确读入,我们先建立一个空字符串,每次读入一行文字,然后把标点符号用“replace()”方法替换为空格,把所有单词转换为小写。读取完毕后以空格为分隔符分割字符串,在进行统计操作即可。别忘了输出的时候要以“次数按照降序排序,如果次数相同,则按照键值的字母升序排序”为规则排序。

标签:实现 add com 数值 inf 字典实现 多分支 lis VID
原文地址:https://www.cnblogs.com/linfangnan/p/12283778.html