标签:信息 info code 中国 python爬虫 架构 str 部分 顺序
内容整理自中国大学MOOC——北京理工大学-蒿天-基于bs4库的HTML页面遍历方法
我们使用如下链接作为实验对象
https://python123.io/ws/demo.html
页面信息如下

利用requests库爬取出网页的HTML完整代码
1 import requests 2 r = requests.get("http://python123.io/ws/demo.html") 3 demo = r.text 4 print(demo)
网页内容如下

熟悉HTML页面架构的都知道,HTML页面中有两大类标签,<head>和<body>,这两类标签在当前HTML信息中都有展现。
然后我们就可以根据HTML的格式架构,产生三种遍历HTML标签的方法:从HTML根标签向子标签的向下遍历,从子标签向根标签的向上遍历,同级标签间的平行遍历。
1.下行遍历
1 import requests 2 from bs4 import BeautifulSoup 3 r = requests.get("http://python123.io/ws/demo.html") 4 demo = r.text 5 soup = BeautifulSoup(demo,"html.parser") 6 print(soup.head) #获取HTML网页的head标签部分
首先我们获取HTML中head部分的信息
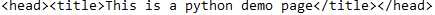
然后我们利用contents属性,取当前head中所有子标签的信息
print(soup.head.contents)
内容如下
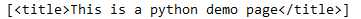
当前head标签中仅有一组<title></title>标签,<title>标签内容被放入列表中
contents会将当前部分的所有标签存入列表(返回结果为一个列表形式)
同理,<body>标签中的全部内容也可用contents进行获取
print(soup.body.contents)

应该注意到,不是只有被标签标记的内容才被视为子标签信息,像当前<body>中的‘\n‘等内容同样被视为子标签节点。
验证统计的当前<body>标签内子标签节点的个数
print(len(soup.body.contents))
结果为5
(通过观察也不难发现,body.contents这个list中,list(0),list(2),list(4)均为换行符,list(1),list(3)分别为一个<p>)
读取body.contents列表中第2个元素也不难
print(soup.body.contents[1])

用.children属性迭代遍历<body>标签下的各子节点
for child in soup.body.children: print(child)
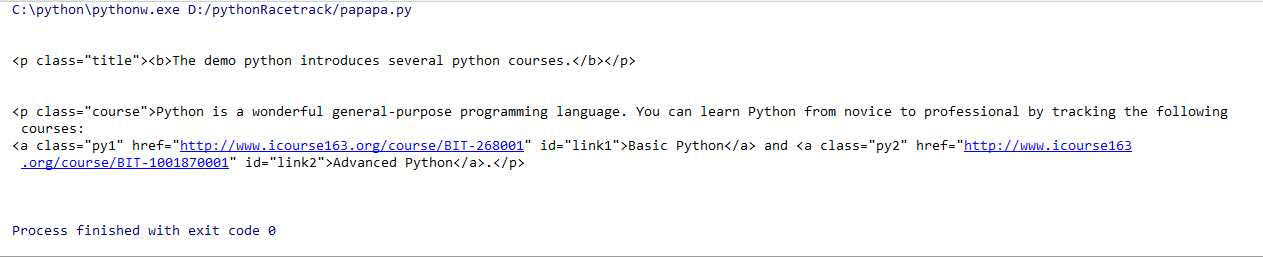
2.上行遍历
利用.parent属性遍历节点的父亲标签
利用.parents属性遍历节点的所有先辈标签,返回迭代类型
print(soup.title.parent)
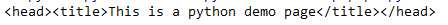
<title>的父辈节点是<head>标签
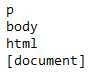
print(soup.html.parent)

<html>作为一级标签,它的父辈节点就是它本身
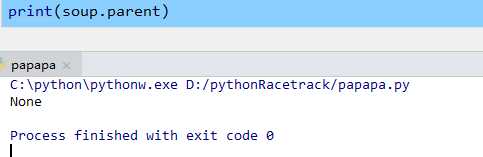
而soup的父辈节点为空
一次性完成当前页面上行遍历
1 import requests 2 from bs4 import BeautifulSoup 3 r = requests.get("http://python123.io/ws/demo.html") 4 demo = r.text 5 soup = BeautifulSoup(demo,"html.parser") 6 for parent in soup.a.parents: 7 if parent is None: 8 print(parent) 9 else: 10 print(parent.name)
3.平行遍历
.next_sibling 返回按照HTML文本顺序的下一个平行节点
.previous_sibling 返回按照HTML文本顺序的上一个平行节点
.next_siblings 迭代返回HTML文本顺序的后续所有平行节点
.previous_siblings 迭代返回返回HTML文本顺序的先前所有平行节点
所有平行遍历必须发生自同一个父节点下
比如<head>与<body>下的不同标签不能通过平行节点进行跨越遍历
单次遍历
print(soup.a.next_sibling)
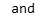
平行遍历获得的下一个节点未必一定是标签类型
迭代遍历
for siblilng in soup.a.next_siblings: print(siblilng)

Python爬虫入门——利用bs4库对HTML页面信息进行遍历读取
标签:信息 info code 中国 python爬虫 架构 str 部分 顺序
原文地址:https://www.cnblogs.com/fcbyoung/p/12291258.html