标签:沟通 基础 入门 info 多个 开始 提示 文章 ignore

?写在前面:
欢迎加入纯干货技术交流群Disaster Army:317784952
接到5月25日之前要交稿的任务我就一门心思想写一篇爬虫入门的文章,可是我并不会。还好有将近一个月的时间去学习,于是我每天钻在书和视频教程里。其实并不难的,我只是想做到能够很好的理解它并用自己的语言较好的表达出来,也许你将看到的是史上最不专业的技术交流文章,没错这就是我想要的。我力求能让没有编程基础同我一样爱黑客技术却苦于看不到出路的同学们在24小时之内明白爬虫是怎么一回事。我想这才是我加入中国红客联盟太极实验室在红客精神的号召下做的有意义的事。学习技术一定要学会付出、开源、共享、互助,很多大牛似乎不愿意这么做了,我们入门小菜鸟只要够团结,乐于奉献就一定可以达到1+1>2的双赢效果。总之共同努力吧!
?第一章
0x00 python的认识、安装
官面上的话自行去百度,这里我只介绍我所掌握到的、最重要的信息。
特点:
(1)跨平台开发
(2)以语法简洁清晰著称
(3)缩进控制严格
至于说爬虫需不需要编程基础,不用多说,君不见本屌在这个月之前的n多个月里是多么苦苦的啃教程,对么下三赖的求指点。其实自学的进步速度太慢了,此文也希望看到的码阔多多提点!
更多信息:
安装也是极易的,只是有python2.7和python3需要纠结选一下。菜菜也不多做建议了,各有所长,python是任性的,不顾及老用户感受强行不兼容更代,足以见得其魄力和自信。2.7的用户较多一点,初学者想用大神的exp不得已会选择它,3的用户逐日增加,人家既然更代自然有好的原因。不必担心,到最后基本上差异在哪里都会知道的。
还是那句话,官面上可以查到的就不多聊,交流文章多写作者的看法,意见不统一的喷过来就是。很多教程会建议一开始的时候用python自带的IDLE写代码,简洁没有代码补全提示,适合初学者!我差点就信了!你会觉得怎么打都有一种好TM业余的感觉有没有?我的观点是:不是武功练到什么程度用什么剑,而是有适合自己的绝世好剑就绝对不用绝世第二剑。所以用了一段时间的IDLE我就决定换一款炫酷的编译器,于是我选择了Atom(这个时候有一个认识上的错误。)然后一个字都没写就安装activate-power-mode插件,开始震屏,冒泡,好不炫酷。
?
安装好了python,有了编译器,我们开始编程了,打开编译器输入
print (“Hello Word”),保存文件名为1.py,就把它保存在桌面上。然后cmd
cd /d C:\\Users\Administrator\Desktop
python 1.py如果打印:Hello word,那么恭喜你,你学会编程了!(我的天!)如果打印失败,那么你和兄弟我起初时犯了一样的错误:没有设置环境变量。
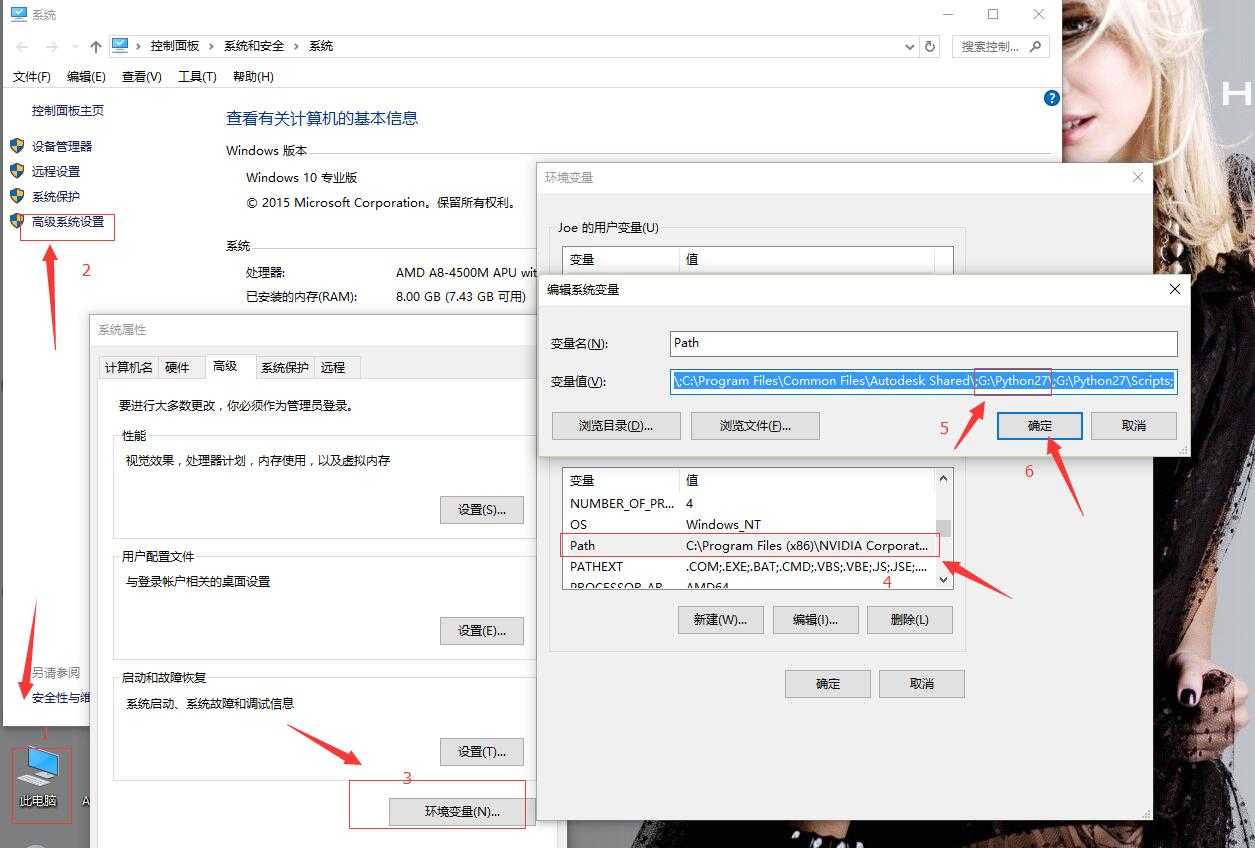
这张图应该可以说明问题了,我的电脑>属性>高级系统设置>环境变量>pach>最后面加;G:\python27(根据自己安装路径来改)。
这回就可以打印了,好吧你也学会编程了!(我天哪!)
?
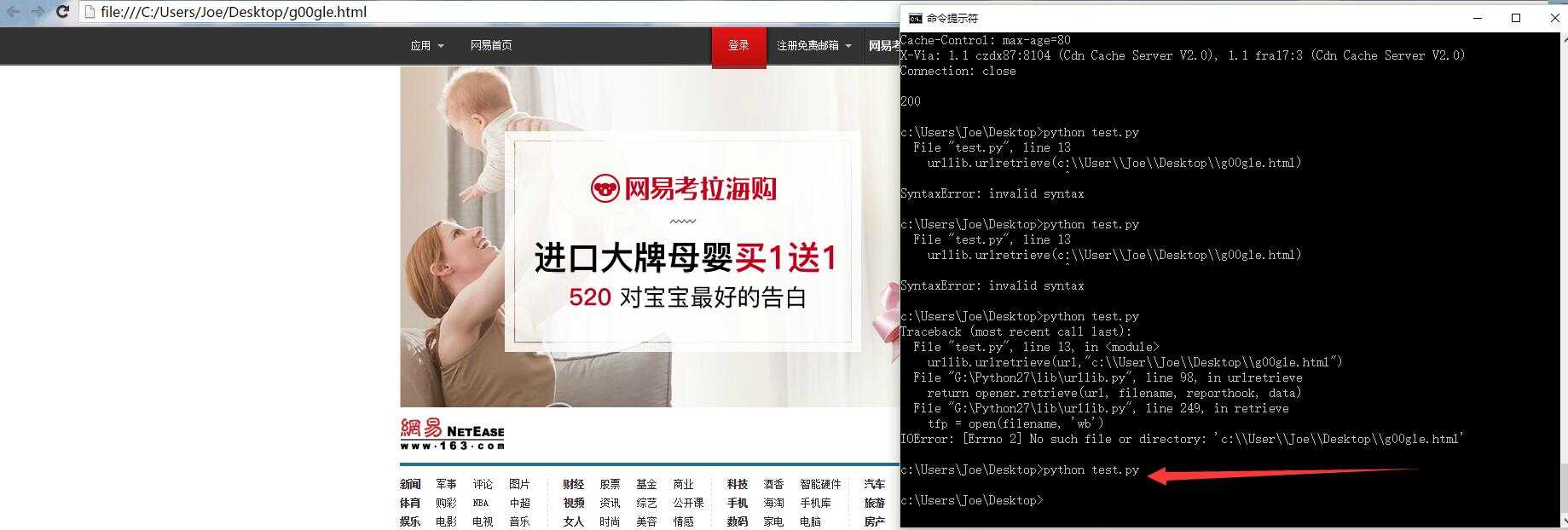
0x001 将网页下载到本地
我们要用到python的标准模块urllib,具体下面的多种方法可以dir打开查看的,代码如下,供您消遣。大多数同学都会觉得太小儿科的,不太懂得不必细究,只需知道用这么个模块,这么个方法可以干这么个事情!
# -*-coding:utf-8 -*-
# 首先进行编码申明
import urllib
# 导入urllib模块
url = "http://www.xxoo.com/"
# 变量赋值
urllib.urlretrieve(url, "C:\\Users\\用户名\\Desktop\\g00gle.txt")
# urlretrieve方法下载到本地这样就将网页下载到本地了

0x002 判断网页是否可以抓取以及抓取进度
思路是这样的:我们针对一个网页首先要看它是否可以爬取,如果可以我们抓取他的什么?抓取它的内容、头部信息、状态码、传入网址等,代码如下:
# -*-coding:utf-8 -*-
import urllib
url = "http://www.163.com/"
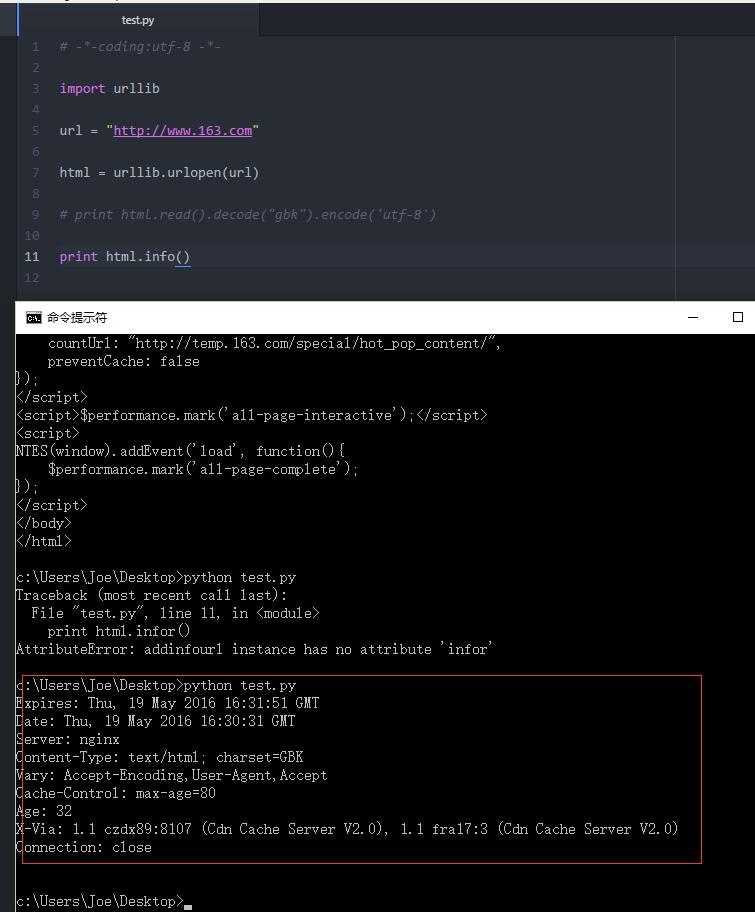
html = urllib.urlopen(url)
# content = html.read().decode('gbk','ignore').encode(''utf-8)
# print(content)
code = html.getcode()
# 网页状态码,变量code是一个整形
if code == 200:
print html.read()
print html.info()
else:
print "不明飞行物."
# if判断语句判断网页返回是否正常,如果正常返回他的内容、头部信息、状态码、传入网址等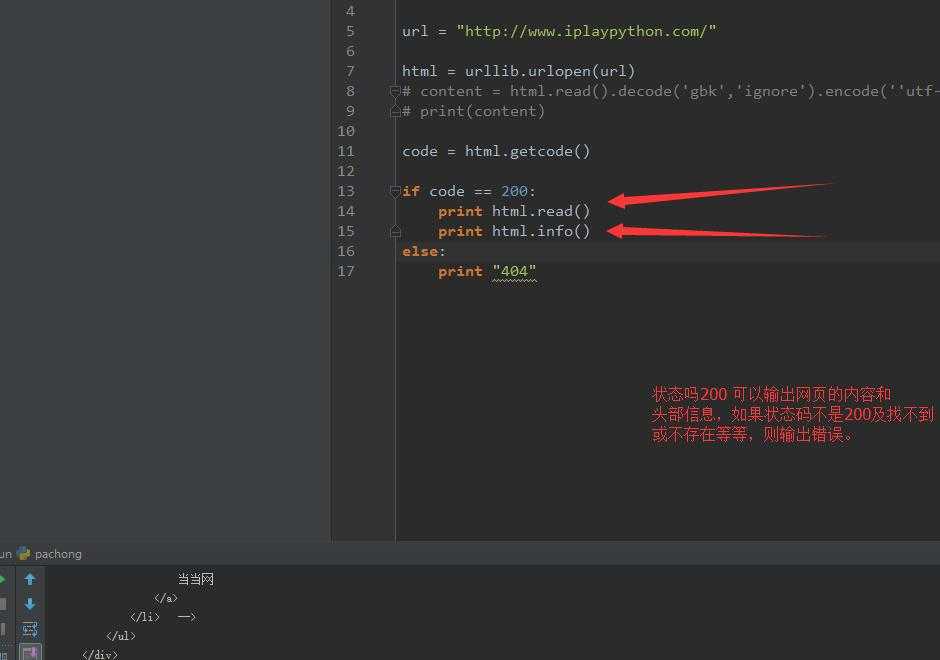
这里,urllib中用的的方法:
# urlopen()
#获取类文件对象
# read()
#读取文件内容
# infor
# 获取头部信息Header
#Getcode
#获取网页状态码
#geturl
#传入网址举一个例子:
这是某站的Header、Sever、Content-Type、Last-Modified
用上面代码抓取打印的结果:
然后我们用回调函数的方法写一段有读取进度的抓取网页的代码。
# -*-coding:utf-8 -*-
import urllib
def callback(a,b,c):
# 回调函数
# @a:xxx
# @b:xxx
# @c:xxx
down_program = 100.0 * a * b / c
if down_program >100:
down_program =100
print "%.1f%%"% down_program
# 字符串拼接%.4f让输出小数点后1位
print ">>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>100%"
url = "http://tieba.baidu.com/"
local = "C:\\Users\\Joe\\Desktop\\papa2.html"
urllib.urlretrieve(url,local,callback)
# 调用了上面封装的callback函数技术有限,本来想让它
>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>100%这样读取的,懒得弄了,没再深究。
?
0x003 你发现换了编译器
对的,至于是为什么呢?因为到后来我才明白编译器、文本编译器、IDE之间的区别,真是愚笨!我是这样理解的,就像大保健一样,IDE小姐可以提供陪吃、推拿、跳舞、刮痧、n推背等服务,编译器呢晚上进屋白天走人,文本编译器……类似于什么呢?充气娃娃?它们不能对比各有所长。Atom严格上来说属于文本编译器,本身不能断点测试,但加载插件后可以。还有,Atom想Chrorme一样任性,自动强制装在系统盘,其实之前忍了它……现在找到我的绝世好剑了,不能忍,Pycharm取而代之。Sublimetext,人气之高,自然也不错。
?
0x004 本章小结
本章我们安装了Python环境,配置了环境变量,浅尝了编程,抓取了网页内容,并有进度条的下载到了本地。其实都是一些简单的事情。简单区分了一下编译器、文本编译器、IDE之间的区别。这个过程中我肯定有认识上和方法上不当的地方,欢迎大家批过来!预知后事如何,咱们下回分解!
?
—————— 
未经沟通转载,将追究法律责任,请尊重原创劳动成果!
标签:沟通 基础 入门 info 多个 开始 提示 文章 ignore
原文地址:https://www.cnblogs.com/g00gle/p/12297292.html