标签:^c 完成 at命令 for循环 空格 结果 device elf doc
本篇是快速入门教程,后面的文章再对相关内容进行深入。Bash只支持单行注释,使用#开头的都被当作注释语句:
# 整行注释
echo hello world # 行尾注释通过Bash的一些特性,可以取巧实现多行注释:
: ‘
注释1
注释2
‘
: <<‘EOF‘
注释1
注释2
EOF
____=‘
注释1
注释2
‘但是,别闲的蛋疼去用取巧的多行注释,安心用#来注释。
Bash中基本数据类型只有字符串类型,连数值类型都没有(declare -i可强制声明数值类型)。
比如:
# 都会当作字符串
echo haha
echo 1234Bash中字符串的串联操作,直接将两段数据连接在一起即可,不需要任何操作符。
例如:
echo "junma""jinlong"
echo 1234 5678a=3
echo $a
a="www.junmajinlong.com"
echo $a
a=‘hello world‘
echo $aShell中可以引用未定义的变量:
echo $xyzdefabc可以定义空变量:
a=
echo $a变量替换是指在命令开始执行前,Shell会先将变量的值替换到引用变量的位置处。
例如:
a="hello"
echo $a world在echo命令开始执行前,Shell会取得变量a的值hello,并将它替换到命令行的$a处。于是,在echo命令开始执行时,命令行已经变成:
echo hello world除了变量替换,Shell还会做其它替换:
这些扩展和替换,都是Shell在调用命令之前就完成的,这和其它语言解析代码的方式不一样。
后面会详细解释Shell是如何做命令行解析的,如果不掌握命令行解析,当遇到命令行语法错误后很可能会花掉大量无谓的时间去调试命令。而掌握命令行解析后,就会对命令生命周期了如执掌,不敢说一次就能写对所有命令行,但能节省大量调试时间,对写命令行和写脚本的能力也会上升一个层次。
使用反引号或$()可以执行命令替换。
`cmd`
$(cmd)命令替换是指先执行cmd,将cmd的输出结果替换到$()或反引号位置处。
例如:
echo `id root`
echo $(id root)在echo命令执行前,会先执行id命令,id命令的执行结果:
$ id root
uid=0(root) gid=0(root) groups=0(root)所以会将结果uid=0(root) gid=0(root) groups=0(root)替换$(id root)。于是,echo命令开始执行时,命令行已经变成了:
echo uid=0(root) gid=0(root) groups=0(root)$[]或$(())或let命令可以做算术运算。
let是单独的命令,不能写在其它命令行中。
a=3
let a=a+1
echo $a$[]和$(())可以写在命令行内部,Shell在解析命令行的时候,会对它们做算术运算,然后将运算结果替换到命令行中。
a=33
echo $[a+3]
echo $((a+3))因为变量替换先于算术替换,所以,使用变量名或引用变量的方式都可以:
a=333
echo $[$a+3]
echo $(($a+3))每个命令执行后都会有对应的进程退出状态码,用来表示该进程是否是正常退出。
所以,在命令行中,在Shell脚本中,经常会使用特殊变量$?判断最近一个前台命令是否正常退出。
通常情况下,如果$?的值:
另外,在Shell脚本中,所有条件判断(比如if语句、while语句)都以0退出状态码表示True,以非0退出状态码为False。
exit命令可用于退出当前Shell进程,比如退出当前Shell终端、退出Shell脚本,等等。
exit [N]exit可指定退出状态码N,如果省略N,则默认退出状态码为0,即表示正确退出。
在命令的结尾使用&符号,可以将这个命令放入后台执行。
命令放入后台后,会立即回到Shell进程,Shell进程会立即执行下一条命令(如果有)或退出。
使用$!可以获取最近一个后台进程的PID。
sleep 20 &
echo $!使用wait命令可以等待后台进程(当前Shell进程的子进程)完成:
wait [n1 n2 n3 ...]不给定任何参数时,会等待所有子进程(即所有后台进程)完成。
sleep 5 &
wait
echo hahaShell中有多种组合多个命令的方式。
1.cmd1退出后,执行cmd2
cmd1;cmd22.cmd1正确退出(退出状态码为0)后,执行cmd2
cmd1 && cmd23.cmd1不正确退出后,执行cmd2
cmd1 || cmd24.逻辑结合:&&和||可以随意结合
# cmd1正确退出后执行cmd2,cmd2正确退出后执行cmd3
cmd1 && cmd2 && cmd3...
# cmd1正确退出则执行cmd2,cmd1不正确退出会执行cmd3
# cmd1正确退出,但cmd2不正确退出,也会执行cmd3
cmd1 && cmd2 || cmd3
# cmd1正确退出会执行cmd3
# cmd1不正确退出会执行cmd2,cmd2正确退出会执行cmd3
cmd1 || cmd2 && cmd35.将多个命令分组:小括号或大括号可以组合多个命令
# 小括号组合的多个命令是在子Shell中执行
# 即会先创建一个新的Shell进程,在执行里面的命令
(cmd1;cmd2;cmd3)
# 大括号组合的多个命令是在当前Shell中执行
# 大括号语法特殊,要求:
# 1.开闭括号旁边都有空白,否则语法解析错误(解析成大括号扩展)
# 2.写在同一行时,每个cmd后都要加分号结尾
# 3.多个命令可分行书写,不要求分号结尾
{ cmd1;cmd2;cmd3; }
{
cmd1
cmd2
cmd3
}软件设计认为,程序应该有一个数据来源、数据出口和报告错误的地方。在Linux系统中,每个程序默认都会打开三个文件描述符(file descriptor,fd):
文件描述符,说白了就是系统为了跟踪打开的文件而分配给它的一个数字,这个数字和文件有对应关系:从文件描述符读取数据,即表示从对应的文件中读取数据,向文件描述符写数据,即表示向对应文件中写入数据。
Linux中万物皆文件,文件描述符也是文件。默认:
这些文件默认又是各个终端的软链接文件:
$ ls -l /dev/std*
lrwxrwxrwx 1 root root 15 Jan 8 20:26 /dev/stderr -> /proc/self/fd/2
lrwxrwxrwx 1 root root 15 Jan 8 20:26 /dev/stdin -> /proc/self/fd/0
lrwxrwxrwx 1 root root 15 Jan 8 20:26 /dev/stdout -> /proc/self/fd/1
$ ls -l /proc/self/fd/
lrwx------ 1 root root 64 Jan 16 10:40 0 -> /dev/pts/0
lrwx------ 1 root root 64 Jan 16 10:40 1 -> /dev/pts/0
lrwx------ 1 root root 64 Jan 16 10:40 2 -> /dev/pts/0
lr-x------ 1 root root 64 Jan 16 10:40 3 -> /proc/75220/fd所以,默认情况下读写数据都是终端,例如:
# 数据输出到终端
$ echo haha
$ cat /etc/fstab
# 从终端读取数据
$ cat
hello # 在终端输入
hello # 在终端输出
world # 在终端输入
world # 在终端输出
^C改变文件描述符对应的目标,可以改变数据的流向。比如标准输入fd=1默认流向是终端设备,若将其改为/tmp/a.log,便能让数据写入/tmp/a.log文件中而不再是终端设备中。
在Shell中,这种改变文件描述符目标的行为称为重定向,即重新确定数据的流向。
其实,文件描述符有很多类操作,包括fd的重定向、fd的分配(open,即打开文件)、fd复制(duplicate)、fd的移动(move)、fd的关闭(close)。现在只介绍基础重定向操作。
Shell中,基础重定向操作有以下几种方式:
另外,经常用于输出的一个特殊目标文件是/dev/null,它是空设备,可以直接丢掉所有写入它的数据。
echo www.junmajinlong.com >/dev/null
curl -I www.junmajinlong.com 2>/dev/null >/tmp/a.log
cat </etc/fstab一个经常用的技巧是清空文件的方式:
$ cat /dev/null >file
$ >filecat是一个命令,这个命令的源代码中写了一些代码用来处理选项和参数。
cat -n /etc/fstabcat命令开始执行后,会识别-n选项,该选项会让cat输出时同时输出行号,cat同时还会识别/etc/fstab参数,cat会读取参数指定的文件然后输出。
如果没有指定cat的文件参数,则cat默认会从标准输入中读取数据。默认的标准输入是终端,所以在没有改变标准输入的流向时,会从终端读取数据,也就是用户输入什么字符,就读取什么字符,然后输出什么字符:
$ cat
junmajinlong # 在终端输入
junmajinlong # 在终端输出
junma # 在终端输入
junma # 在终端输出
^C但用户可以改变标准输入的来源。比如:
$ cat </etc/fstab表示将标准输入来源改为/etc/fstab文件,于是cat会从/etc/fstab中读取数据。
另外,约定俗成的,会使用一个-来表示标准输入或标准输出。
# 下面是等价的,都表示从标准输入中读取数据
cat -
cat /dev/stdin
cat注:这并非是一贯正确的,只是约定俗成的大多数程序的代码中都定义了-相关的代码处理。可参考相关命令的man手册。如man cat中有一行:
With no FILE, or when FILE is -, read standard input.输入重定向是<,除此之外还有<<、<<<。
<<符号表示here doc。也就是说,它后面跟的是一篇文档,就像一个文件一样,只不过这个文件的内容是临时定义在<<符号后的。here doc常用于指定多行数据输入。
既然是文档,就有文档起始符号表示文档从此开始和文档终止符号表示文档到此结束。起始符和终止符中间的内容全部是文档内容。文档内容会作为标准输入的数据被读取。
文档的起始符和终止符可以随意定义,但两者前后必须一样。常见的符号是:
例如:
# here doc作为标准输入被读取,然后被cat输出
cat <<EOF
hello
world
EOF
# here doc的内容还会被cat覆盖式输出到指定文件
cat <<eof >/tmp/file
hello
world
eof
# here doc的内容还会被cat追加式输出到指定文件
cat <<eof >>/tmp/file
hello
world
eof
# here doc和重定向符号的前后位置随意
cat >>/tmp/file<<eof
...
eof另外,如果将起始符用引号包围,则不会进行变量替换、命令替换、算术替换等。如果不用引号包围起始符,则会进行替换。
a=333
cat <<eof
$a
eof
cat <<"eof"
$a
eof输出结果:
333
$a<<<表示here string。也就是说该符号后面是一个字符串,这个字符串会作为标准输入的内容。
cat <<<"www.junmajinlong.com"使用单引号包围here string时,不会进行变量替换、命令替换等,使用双引号包围时会进行替换。
$ a=3333
$ cat <<<$a
3333
$ cat <<<"hello world$a"
hello world3333
$ cat <<<‘hello world$a‘
hello world$ahere string常可以替代管道前的echo命令echo xxx|。例如:
# 下面是等价的
echo hello world | grep "llo"
grep "llo" <<<"hello world"管道的用法:
cmd1 | cmd2 | cmd3...每个竖线代表一个管道。上面命令行表示cmd1的标准输出会放进管道,cmd2会从管道中读取进行处理,cmd2的标准输出会放入另一个管道,cmd3会从这个管道中读取数据进行处理。后面还可以接任意数量的管道。
Shell管道是Shell中最值得称赞的功能之一,它以非常简洁的形式实现了管道的进程间通信方式,我个人认为Shell处理文本数据的半壁江山都来自于竖线形式的管道。像其它编程语言,打开管道后还要区分哪个进程写管道、哪个进程读管道,为了安全,每个进程还要关闭不用的读端或写端,总之就是麻烦,而Shell的管道非常简洁,竖线左边的就是写管道的,竖线右边的就是读管道的。
例如:
ps aux | grep ‘sshd‘ps命令产生的数据(标准输出)会写进管道,只要管道内一有数据,grep命令就从中读取数据进行处理。
那下面的命令中,grep从哪读数据呢?
ps aux | grep ‘#‘ /etc/fstab那想要让grep既从/etc/fstab读取数据,也从管道中读取数据呢?
ps aux | grep ‘#‘ /etc/fstab /etc/stdin
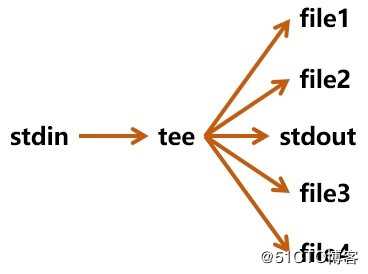
ps aux | grep ‘#‘ /etc/fstab -tee命令可将一份标准输入原样拷贝到标准输出和0或多个文件中。换句话说,tee的作用是数据多重定向。
NAME
tee - read from standard input and write to standard output and files
SYNOPSIS
tee [OPTION]... [FILE]...
DESCRIPTION
Copy standard input to each FILE, and also to standard output.
-a, --append
ppend to the given FILEs, do not overwrite如图:
例如:
$ echo hello world | tee /tmp/file1 /tmp/file2 | cat
$ echo hello world | tee -a /tmp/file3 >/dev/nullBash还支持进程替换(注:有些Shell不支持进程替换)。
进程替换的语法:
<(cmd)
>(cmd)进程替换和命令替换类似,都是让cmd命令先执行,因为它们都是在Shell解析命令行的阶段执行的。
进程替换先让cmd放入后台异步执行,并且不会等待cmd执行完。
其实,每个进程替换都是一个虚拟文件,只不过这个文件的内容是由cmd命令产生的(<(cmd))或被cmd命令读取的(>(cmd))。
$ echo <(echo www.junmajinlong.com)
/dev/fd/63既然进程替换是文件,那么它就可以像文件一样被操作。比如被读取、被当作标准输入重定向的数据源等等:
# cmd做数据产生者
$ cat <(echo www.junmajinlong.com) # 等价于cat /dev/fd/63
$ cat < <(echo www.junmajinlong.com) # 等价于cat </dev/fd/63
# cmd做数据接收者
$ echo hello world > >(grep ‘llo‘)
$ echo hello world | tee >(grep ‘llo‘) >(grep ‘rld‘) >/dev/nulltest命令或功能等价的Bash内置命令[ ]可以做条件测试,如果测试的结果为True,则退出状态码为0。
此外,还可以使用[[]]来做条件测试,甚至let、$[]、$(())也可以做条件测试,但这里暂不介绍。
这些条件测试常用在if、while语句中,也常用在cmd1 && cmd2 || cmd3格式的命令行中。
用法示例:
sh_file=test.sh
[ -x "$sh_file" ] && ./$sh_file || { echo "can‘t execute,exit...";exit 1; }
test -x "$sh_file" && ./$sh_file || { echo "can‘t execute,exit...";exit 1; }[]中的条件测试需要和开闭中括号使用空格隔开,否则语法解析错误。
[ ]
test没有任何测试内容时,直接返回false。
true命令直接返回true,即退出状态码为0。
false命令直接返回false,即退出状态码非0。
$ true
$ echo $? # 0
$ false
$ echo $? # 1| 条件表达式 | 含义 |
|---|---|
| -e file | 文件是否存在(exist) |
| -f file | 文件是否存在且为普通文件(file) |
| -d file | 文件是否存在且为目录(directory) |
| -b file | 文件是否存在且为块设备block device |
| -c file | 文件是否存在且为字符设备character device |
| -S file | 文件是否存在且为套接字文件Socket |
| -p file | 文件是否存在且为命名管道文件FIFO(pipe) |
| -L file | 文件是否存在且是一个链接文件(Link) |
| 条件表达式 | 含义 |
|---|---|
| -r file | 文件是否存在且当前用户可读 |
| -w file | 文件是否存在且当前用户可写 |
| -x file | 文件是否存在且当前用户可执行 |
| -s file | 文件是否存在且大小大于0字节,即检测文件是否非空文件 |
| -N file | 文件是否存在,且自上次read后是否被modify |
| 条件表达式 | 含义 |
|---|---|
| file1 -nt file2 | (newer than)判断file1是否比file2新 |
| file1 -ot file2 | (older than)判断file1是否比file2旧 |
| file1 -ef file2 | (equal file)判断file1与file2是否为同一文件 |
| 条件表达式 | 含义 |
|---|---|
| int1 -eq int2 | 两数值相等(equal) |
| int1 -ne int2 | 两数值不等(not equal) |
| int1 -gt int2 | n1大于n2(greater than) |
| int1 -lt int2 | n1小于n2(less than) |
| int1 -ge int2 | n1大于等于n2(greater than or equal) |
| int1 -le int2 | n1小于等于n2(less than or equal) |
| 条件表达式 | 含义 |
|---|---|
| -z str | (zero)判定字符串是否为空?str为空串,则true |
| str <br>-n str | 判定字符串是否非空?str为串,则false。注:-n可省略 |
| str1 = str2 <br>str1 == str2 | str1和str2是否相同,相同则返回true。"=="和"="等价 |
| str1 != str2 | str1是否不等于str2,若不等,则返回true |
| str1 > str2 | str1字母顺序是否大于str2,若大于则返回true |
| str1 < str2 | str1字母顺序是否小于str2,若小于则返回true |
| 条件表达式 | 含义 |
|---|---|
| -a或&& | (and)两表达式同时为true时才为true。<br>"-a"只能在test或[]中使用,&&只能在[[]]中使用 |
| -o或|| | (or)两表达式任何一个true则为true。<br/>"-o"只能在test或[]中使用,||只能在[[]]中使用 |
| ! | 对表达式取反 |
| ( ) | 改变表达式的优先级,为了防止被shell解析,应加上反斜线转义( ) |
if test-commands; then
consequent-commands;
[elif more-test-commands; then
more-consequents;]
[else alternate-consequents;]
fitest-commands既可以是test测试或[]、[[]]测试,也可以是任何其它命令,test-commands用于条件测试,它只判断命令的退出状态码是否为0,为0则为true。
例如:
if [ "$a" ];then echo ‘$a‘ is not none;else echo ‘$a‘ undefined or empty;fi
if [ ! -d ~/.ssh ];then
mkdir ~/.ssh
chown -R $USER.$USER ~/.ssh
chmod 700 ~/.ssh
fi
if grep ‘junmajinlong‘ /etc/passwd &>/dev/null;then
echo ‘User "junmajinlong" already exists...‘
elif grep ‘malongshuai‘ /etc/passwd &>/dev/null;then
echo ‘User "malongshuai" already exists...‘
else
echo ‘you should create user,exit...‘
exit 1
ficase常用于确定的分支判断。比如:
while [ ${#@} -gt 0 ];do
case "$1" in
start)
echo start;;
stop)
echo stop
;;
restart)
echo restart
;;
reload | force-reload)
echo reload;;
status)
echo status;;
*)
echo $"Usage: $0 {start|stop|status|restart|reload|force-reload}"
exit 2
esac
donecase用法基本要求:
;;结尾,否则出现分支穿透(所以;;不是必须的) *) 下面是为ping命令自定义设计选项的脚本:
#!/bin/bash
while [ $1 ];do
case "$1" in
-c|--count)
count=$2
shift 2
;;
-t|--timeout)
timeout=$2
shift 2
;;
-h|--host)
host=$2
shift 2
;;
*)
echo "wrong options or arguments"
exit 1
esac
done
ping -c $count -W timeout $host执行:
$ chmod +x ping.sh
$ ./ping.sh -c 5 -t 2 有两种for循环结构:
# 成员测试类语法
for i in word1 word2 ...;do cmd_list;done
# C语言for语法
for (( expr1;expr2;expr3 ));do cmd_list;done成员测试类的for循环中,in关键字后是使用空格分隔的一个或多个元素,for循环时,每次从in关键字后面取一个元素并赋值给i变量。
例如:
$ for i in 1 2 3 4;do echo $i;done
1
2
3
4
$ for i in 1 2 "3 4";do echo $i;done
1
2
3 4C语言型的for语法中,expr1是初始化语句,expr2是循环终点条件判断语句,expr3是每轮循环后执行的语句,一般用来更改条件判断相关的变量。
for ((i=1;i<=3;++i));do echo $i;done
1
2
3while test_cmd_list;do cmd_list;donewhile循环,开始时会测试test_cmd_list,如果测试的退出状态码为0,则执行一次循环体语句cmd_list,然后再测试test_cmd_list,一直循环,直到测试退出状态码非0,循环退出。
例如:
let i=1,sum=0;
while [ $i -le 10 ];do
let sum=sum+i
let ++i
done还有until循环语句,但在Shell中用的很少。
while循环经常会和read命令一起使用,read是Bash的内置命令,可用来读取文件,通常会按行读取:每次读一行。
例如:
cat /etc/fstab | while read line;do
let num+=1
echo $num: $line
done上面的命令行中,首先cat进程和while结构开始运行,while结构中的read命令从标准输入中读取,也就是从管道中读取数据,每次读取一行,因为管道中最初没有数据,所以read命令被阻塞处于数据等待状态。当cat命令读完文件所有数据后,将数据放入到管道中,于是read命令从管道中每次读取一行并将所读行赋值给变量line,然后执行循环体,然后继续循环,直到read读完所有数据,循环退出。
但注意,管道两边的命令默认是在子Shell中执行的,所以其设置的变量在命令执行完成后就消失。换句话说,在父Shell中无法访问这些变量。比如上面的num变量是在管道的while结构中设置的,除了在while中能访问该变量,其它任何地方都无法访问它。
如果想要访问while中赋值的变量,就不能使用管道。如果是直接从文件读取,可使用输入重定向,如果是读取命令产生的数据,可使用进程替换。
while read line;do
let num1+=1
echo $num1: $line
done </etc/fstab
echo $num1
while read line;do
let num2+=1
echo $num2: $line
done < <(grep ‘UUID‘ /etc/fstab)Shell函数可以当作命令一样执行,它是一个或多个命令的组合结构体。通常,可以为每个功能定义一个函数,该函数中包含实现这个功能相关的所有命令和逻辑。
因为可以组合多个命令,并且定义之后就可以直接在当前Shell中调用,所以函数具有一次定义多次调用且代码复用的功能。
Shell函数的定义风格有下面几种:
function func_name {CMD_LIST}
func_name() {CMD_LIST}
function func_name() {CMD_LIST}函数定义后,可以直接使用函数名来调用函数,同时还可以向函数传递零个或多个参数。
# 不传递参数
func_name
# 传递多个参数
func_name arg1 arg2 arg3在函数中,那些位置变量将有特殊的意义:
$1、$2、$3...:传递给函数的第一个参数保存在$1中,第二个参数保存在$2中...$@和$*:保存了所有参数,各参数使用空格分隔
$@的各个元素都被双引号包围,$*的所有元素一次性被双引号包围 例如,定义一个函数专门用来设置和代理相关的变量:
proxy_addr=127.0.0.1:8118
function proxy_set {
local p_addr=$1
export http_proxy=$p_addr
export https_proxy=$p_addr
export ftp_proxy=$p_addr
}
# 调用函数
proxy_set $proxy_addr
# 各代理变量已设置
echo $http_proxy
echo $https_proxy
echo $ftp_proxy上面在函数定义的代码中使用了local,它可以用在函数内部表示定义一个局部变量,局部变量在函数执行完毕后就消失,不会影响函数外部的环境。
另外,函数中可以使用return语句来定义函数的返回值,每当执行到函数内的return时,函数就会终止执行,直接退出函数。在Shell中,函数的返回值其实就是退出状态码。
return [N]如果不指定N,则默认退出状态码为0。
例如:
function sayhello {
[ "$1" ] || { echo "give me a name please!"; return 1; }
echo hello $1
}
sayhello "junma" ; echo $?
sayhello "jinlong" ; echo $?
sayhello ; echo $?标签:^c 完成 at命令 for循环 空格 结果 device elf doc
原文地址:https://blog.51cto.com/8155185/2470463