标签:ref lis mys 过程 地理 机制 聚合 技术 blocks
目录
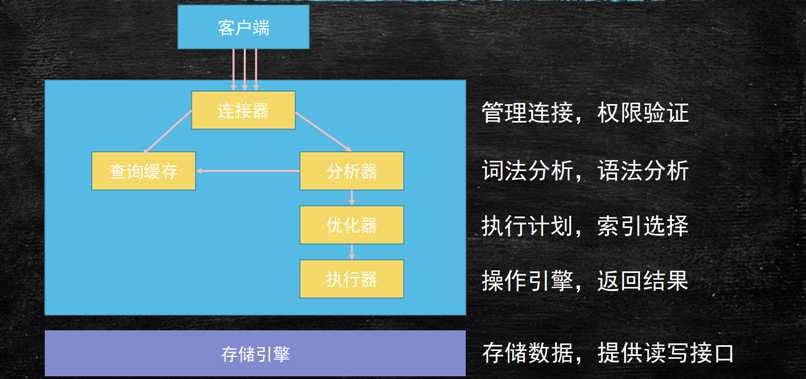
执行查询语句的时候会先在查询缓存中找是否之前有之前查询过的,是以sql和结果构成键值对,如果有之前的记录就使用缓存,没有继续向下执行。
但是不推荐使用,mysql8已经会去掉查询缓存了,而且只要表更新缓存就失效,更新频繁的数据表缓存的命中很低
#查看查询缓存情况:
mysql> show variables like '%query_cache%';
+------------------------------+---------+
| Variable_name | Value |
+------------------------------+---------+
| have_query_cache | YES |
| query_cache_limit | 1048576 |
| query_cache_min_res_unit | 4096 |
| query_cache_size | 1048576 |
| query_cache_type | OFF |
| query_cache_wlock_invalidate | OFF |
+------------------------------+---------+
6 rows in set (0.01 sec)
如果不是ON,修改配置文件以开启查询缓存:
> vi /usr/local/mysql/bin/my.cnf
[mysqld]中添加:
query_cache_size = 20M
query_cache_type = ON
重启mysql服务:
> service mysql restart
查看缓存使用情况:
mysql> show status like 'qcache%';
+-------------------------+---------+
| Variable_name | Value |
+-------------------------+---------+
| Qcache_free_blocks | 1 |
| Qcache_free_memory | 1031832 |
| Qcache_hits | 0 |
| Qcache_inserts | 0 |
| Qcache_lowmem_prunes | 0 |
| Qcache_not_cached | 0 |
| Qcache_queries_in_cache | 0 |
| Qcache_total_blocks | 1 |
+-------------------------+---------+
8 rows in set (0.00 sec)
其中各个参数的意义如下:
Qcache_free_blocks:缓存中相邻内存块的个数。数目大说明可能有碎片。FLUSH QUERY CACHE会对缓存中的碎片进行整理,从而得到一个空闲块。
Qcache_free_memory:缓存中的空闲内存。
Qcache_hits:每次查询在缓存中命中时就增大
Qcache_inserts:每次插入一个查询时就增大。命中次数除以插入次数就是不中比率。
Qcache_lowmem_prunes:缓存出现内存不足并且必须要进行清理以便为更多查询提供空间的次数。这个数字最好长时间来看;如果这个 数字在不断增长,就表示可能碎片非常严重,或者内存很少。(上面的 free_blocks和free_memory可以告诉您属于哪种情况)
Qcache_not_cached:不适合进行缓存的查询的数量,通常是由于这些查询不是 SELECT 语句或者用了now()之类的函数。
Qcache_queries_in_cache:当前缓存的查询(和响应)的数量。
Qcache_total_blocks:缓存中块的数量。
对于某些不想使用缓存的语句,可以这样使用:
select SQL_NO_CACHE count(*) from users where email = 'hello';将关键字,列名,比较符号等从sql字符串中解析出来
将上述的解析过的sql进行语法检查,语法错误则会报你的sql语法有问题
当发生数据修改的时候innodb存储引擎会先将记录写到redo日志,然后更新内存,innodb会在一个合适的时间将记录写入磁盘
redolog是固定大小的,循环记录的过程
redolog保证了数据库数据的安全,即使数据库重启之前的记录也不会丢失,叫做crash-safe。

太深奥不懂先记着


| 功能 | InnoDB | MyISAM | Memory | Archive | NDB |
|---|---|---|---|---|---|
| b -树索引 | 是的 | 是的 | 是的 | 没有 | 没有 |
| 备份/恢复时间点(注1) | 是的 | 是的 | 是的 | 是的 | 是的 |
| 集群数据库支持 | 没有 | 没有 | 没有 | 没有 | 是的 |
| 聚集索引 | 是的 | 没有 | 没有 | 没有 | 没有 |
| 压缩数据 | 是的 | 是的(注2) | 没有 | 是的 | 没有 |
| 数据缓存 | 是的 | 没有 | N /A | 没有 | 是的 |
| 加密的数据 | 是的(注4) | 是的(注3) | 是的(注3) | 是的(注3) | 是的(注3) |
| 外键的支持 | 是的 | 没有 | 没有 | 没有 | 是的(注5) |
| 全文搜索索引 | 是的(注6) | 是的 | 没有 | 没有 | 没有 |
| 地理空间数据类型支持 | 是的 | 是的 | 没有 | 是的 | 是的 |
| 地理空间索引支持 | 是的(注7) | 是的 | 没有 | 没有 | 没有 |
| 散列索引 | 没有(注8) | 没有 | 是的 | 没有 | 是的 |
| 索引缓存 | 是的 | 是的 | N /A | 没有 | 是的 |
| 锁的粒度 | 行 | 表 | 表 | 行 | 行 |
| MVCC | 是的 | 没有 | 没有 | 没有 | 没有 |
| 复制支持 (注1) | 是的 | 是的 | Limited | 是的 | 是的 |
| 存储限制 | 64TB | 256TB | 内存 | NONE | 384EB |
| -树索引 | 没有 | 没有 | 没有 | 没有 | 是的 |
| 交易 | 是的 | 没有 | 没有 | 没有 | 是的 |
| 更新统计数据的数据字典 | 是的 | 是的 | 是的 | 是的 | 是的 |
innodb引擎:默认行级锁,无索引退化成表级锁,有索引走行级锁
表级锁:开销小,加锁快;不会出现死锁;锁定粒度大,发生锁冲突的概率最高,并发度最低。
行级锁:开销大,加锁慢;会出现死锁;锁定粒度最小,发生锁冲突的概率最低,并发度也最高。
共享读锁(S)之间是兼容的,但共享读锁(S)与排他写锁(X)之间,以及排他写锁(X)之间是互斥的,也就是说读和写是串行的
表共享读锁(Table Read Lock)
| 当前session | 其他session |
|---|---|
| 可读当前锁的表,不可修改 | 可查询当前锁的表 |
| 不能查询没有锁定的表 | 可以查询或者更新未锁定的表 |
表独占写锁(Table Write Lock)
| 当前session | 其他session |
|---|---|
| 对表的查询,插入,更新操作都可以执行 | 不能进行读、写表 |
MyISAM在执行查询语句之前,会自动给涉及的所有表加读锁,在执行更新操作前,会自动给涉及的表加写锁,这个过程并不需要用户干预,因此用户一般不需要使用命令来显式加锁,上例中的加锁时为了演示效果。
MyISAM的并发插入问题
? 共享锁(s):又称读锁。允许一个事务去读一行,阻止其他事务获得相同数据集的排他锁。若事务T对数据对象A加上S锁,则事务T可以读A但不能修改A,其他事务只能再对A加S锁,而不能加X锁,直到T释放A上的S锁。这保证了其他事务可以读A,但在T释放A上的S锁之前不能对A做任何修改。
? 排他锁(x):又称写锁。允许获取排他锁的事务更新数据,阻止其他事务取得相同的数据集共享读锁和排他写锁。若事务T对数据对象A加上X锁,事务T可以读A也可以修改A,其他事务不能再对A加任何锁,直到T释放A上的锁。
? mysql InnoDB引擎默认的修改数据语句:update,delete,insert都会自动给涉及到的数据加上排他锁,select语句默认不会加任何锁类型,如果加排他锁可以使用select …for update语句,加共享锁可以使用select … lock in share mode语句。所以加过排他锁的数据行在其他事务种是不能修改数据的,也不能通过for update和lock in share mode锁的方式查询数据,但可以直接通过select …from…查询数据,因为普通查询没有任何锁机制。
? innoDB行级锁是对索引加锁的,只要用到索引需要考虑索引行是否被加锁了
表分区和分库分表和在用途上不一样,分表是为了承接超大规模的表,单机放不下那种。分区的话则一般都是放在单机里的,用的比较多的是时间范围分区,方便归档,减少io量。性能稳定上的话都是一个个子表,差不多,区别应该是分区表是mysql内部实现的,会比分表方案少一点数据交互。
关键字:partion
适用于较大的数据量,可解决热点且有一定规律的数据,按规律分区;
null值导致分区过滤无效。
分区列和索引列不匹配,导致分区过滤失效:索引列和分区列不匹配是指你的sql语句where条件的包含带有索引的列但不包含分区列的情况,这时候不管分区列有没有索引都不会进行分区过滤。扫描列B上的索引应该是打印错误,扫描A上的索引才需要检索所有分区内A的索引。
https://dev.mysql.com/doc/refman/5.7/en/partitioning.html
事物属性中的自然唯一标识
与业务无关的,无意义的数字序列
==推荐使用代理主键==
推荐使用utf8-mb4,utf-8只能存2个字节的汉字,三个字节的汉字会出现问题
DQL
? 数据查询语言
DDL
? 数据定义语言
DML
? 数据操做语言
TCL
? 事务控制语言
set @a=值、sql中需要:=赋值,sql中一般需要一个子查询来配合使用变量
SELECT @k := 0, @i := 0, @score := 0--求出工资最高员工编号最低的员工,工资和编号权重一样
SELECT
a.rank + b.rank '排名之和',
a.ename,
a.sal,
a.empno,
a.rank '工资排名',
b.rank '员工编号排名'
FROM
(
SELECT
@i := @i + 1 rank,
ename,
sal,
empno
FROM
emp,(SELECT @i := 0 ) c ORDER BY sal DESC ) a
JOIN ( SELECT @c := @c + 1 rank, ename FROM emp,( SELECT @c := 0 ) c ORDER BY empno ) b ON a.ename = b.ename
GROUP BY
a.ename,
a.sal,
a.empno,
a.rank,
b.rank;@@变量名取的是系统变量
标签:ref lis mys 过程 地理 机制 聚合 技术 blocks
原文地址:https://www.cnblogs.com/zpyu521/p/12304558.html