标签:apach 目录 dota detail change nbsp channel -- article
Apache Flume是为有效收集聚合和移动大量来自不同源到中心数据存储而设计的可分布,可靠的,可用的系统。
Flume是一个分布式、可靠、和高可用的海量日志采集、聚合和传输的系统。
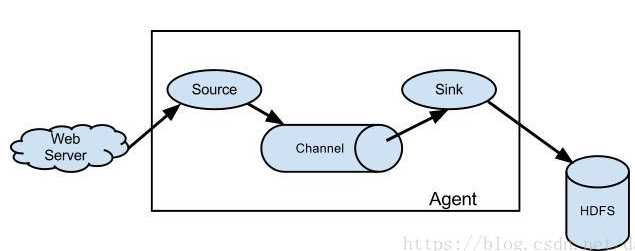
①client:客户端,运行agent的地方,每台机器只运行一个agent
②avro:文件序列化的一种方式
③Source:
数据源,负责接收数据
Source类型:Spooling Directory Source(监控目录)、监控文件、Netcat Source(监控端口)、exec(监控控制台)等
④Channel:
①Channel被设计为event中转暂存区,存储Source 收集并且没有被Sink消费的event ,为了平衡Source收集 和Sink读取数据的速度,可视为Flume内部的消息队列。
②Channel是线程安全的并且具有事务性,支持source写失 败重复写和sink读失败重复读等操作
③Channel类型有:Memory Channel、File Channel、Kafka Channel、JDBC Channel等
注:使用内存作为Channel,Memory Channel读写速度 快,但是存储数据量小,Flume进程挂掉、服务器停机或者重启都会 导致数据丢失
一般情况下,用MemoryChannel就好了
⑤sink:
从Channel消费event,输出到外部存储,或者输出到下一个阶段的agent
①一个Sink只能从一个Channel中消费event
②当Sink写出event成功后,就会向Channel提交事务。Sink事务提交成功,处理完成的event将会被Channel删除。否则Channel会等待Sink重新消费处理失败的event
③Flume提供了丰富的Sink组件,如Avro Sink、HDFS Sink、Kafka Sink、File Roll Sink、HTTP Sink
⑥event:
flume的事件,数据传输的基本单位,相当于一条数据,如果是文本文件,通常是一行记录
⑦agent:
flume的客户端,一个agent运行在一个jvm里,它是flume的最小的独立运行单元。每台机器运行一个agent,但是-个agent中可以包含多个channel和sinks
⑧interceptor:
拦截器,flume允许用户使用拦截器来拦截数据,它作用于source向Channel端传递数据的时候,flume还允许使用拦截器链。拦截器都可以进行转换或者删除这些事件。
时间拦截器:
在消息前面加上时间报头,
主机拦截器:
在消息前面加上IP报头
静态拦截器:
在消息前面加上自定义的(k,v)报头
正则过滤拦截器:
在日志采集的时候,可能有一些数据是我们不需要的,这样添加过滤拦截器,
可以过滤掉不需要的日志,也可以根据需要收集满足正则条件的日志
⑨selector:
选择器,由于一个source可以连接多个channel,Channel选择器用来解决source接收数据后写入到哪些channel。
replicating selector:
将消息复制,发送给多个channel
multiplexing selector:
根据报头上的(k,v),将Flume进行分流
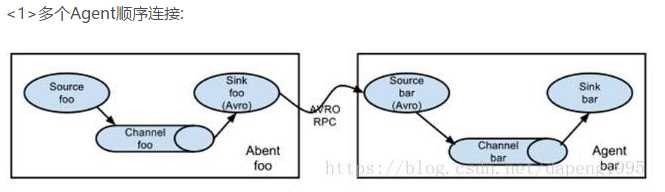
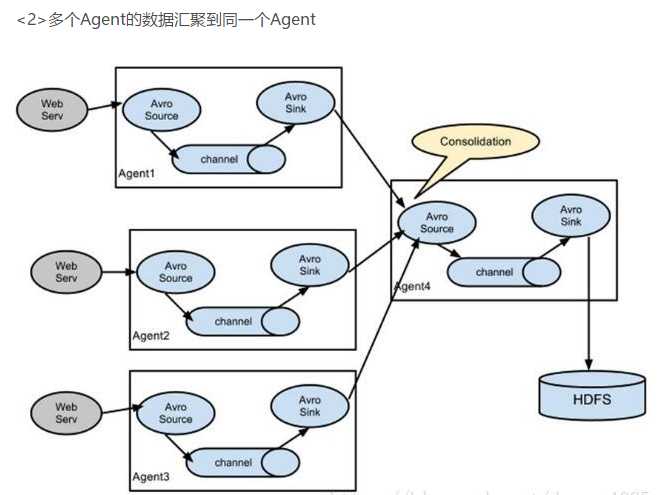
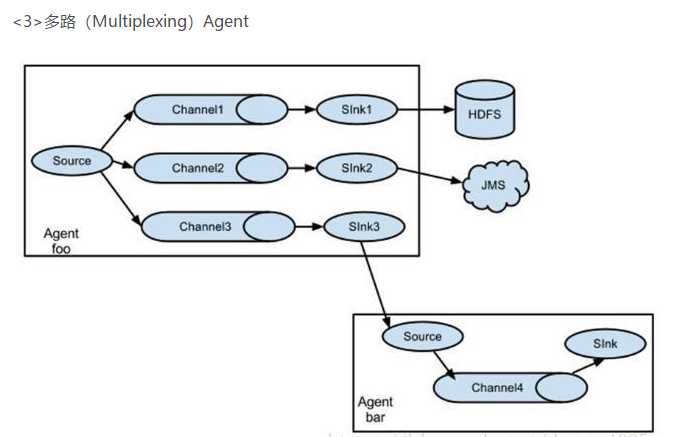
<4>Flume NG(高可用)
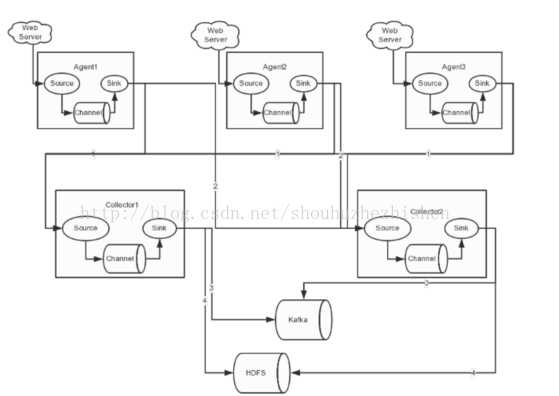
https://blog.csdn.net/m0_37739193/article/details/78779686
上面的博客主要思路:
agent1.sources.avro-source1.command = /usr/local/bin/tail ?-n +$(tail -n1 /home/storm/tmp/n) --max-unchanged-stats=600 -F ?/home/storm/tmp/id.txt | awk ‘ARNGIND==1{i=$0;next}{i++; if($0~/文件已截断/)i=0; print i >>
通过配置这个参数,合理利用tail记录所传数据的行号,那么下次接着这个行号传就行
Put事务可以分为以下阶段(从source到channel):
doPut:将批数据先写入临时缓冲区putList
doCommit:检查channel内存队列是否足够合并。
doRollback:channel内存队列空间不足,抛弃数据
注:batchSize参数决定Source一次批量传输到Channel的event条数,适当调大这个参数可以提高Source搬运Event到Channel时的性能。
Take事务分为以下阶段(sink):
doTake:先将channel数据取到临时缓冲区takeList,然后将数据发送到下一个节点
doCommit:如果数据全部发送成功,则清除临时缓冲区takeList
doRollback:数据发送过程中如果出现异常,rollback将临时缓冲区takeList中的数据归还给channel内存queue队列顶部。 (在顶部!!)
注:batchSize参数决定Sink一次批量从Channel读取的event条数,适当调大这个参数可以提高Sink从Channel搬出event的性能。
1、Flume的停止
使用kill停止Flume进程,不可使用kill -9,因为Flume内部注册了很多钩子函数执行善后工作,如果使用kill -9会导致钩子函数不执行,
使用kill时,Flume内部进程会监控到用户的操作,然后调用钩子函数,执行一些善后操作,正常退出。
2、Flume数据丢失问题
Flume可能丢失数据的情况是Channel采用memoryChannel,agent宕机导致数据丢失,或者Channel存储数据已满,导致Source不再写入,未写入的数据丢失。
3、Flume数据重复sink问题
例如数据已经成功由Sink发出,但是没有接收到响应,Sink会再次发送数据,此时可能会导致数据的重复。
4、CPU占用过高的问题
若程序运行出现CPU占用过高的现象,则可以在代码中加入休眠sleep,这样的话,就可以释放CPU资源,注意,内存资源不会释放,因为线程还未结束,是可用状态。
①下载:http://mirrors.tuna.tsinghua.edu.cn/apache/flume/1.8.0/apache-flume-1.8.0-bin.tar.gz
②解压:tar –zxvf apache-flume-1.8.0-bin.tar.gz -C /opt/app
③该权限:chown -R hadoop:hadoop /opt/app/apache-flume-1.6.0-bin
④配置环境变量:FLUME_HOME = /opt/app/apache-flume-1.6.0-bin 追加bin目录到PATH中
⑤source /etc/profile
⑥cp flume-env.sh.template flume-env.sh //conf目录下
⑦vim flume-env.sh
export JAVA_HOME=....... //添加这句话和jdk路劲
⑧判断是否成功
bin/flume-ng version
①在conf下新建avro.conf touch avro.conf ②将一下内容复制到avro.conf a1.sources = r1 a1.channels = c1 a1.sinks = s1 #describe the sources a1.sources.r1.type=avro a1.sources.r1.bind=s10 //在s10上44444上进行监控,如果有数据发送过来就进行收集 a1.sources.r1.port=44444 #describe the channel a1.channels.c1.type=memory #describe the sink a1.sinks.s1.type=logger a1.sources.r1.channels=c1 a1.sinks.s1.channel=c1 ③在xshell上开启两个s10,cd $FLUME_HOME 其中一个s10: bin/flume-ng agent -c ./conf -f /opt/app/apache-flume-1.8.0-bin/conf/avro.conf -n a1 -Dflume.root.logger=INFO,console //这是agent端,基本配置文件在./conf下面,这个采集任务的配置文件在.../avro.conf,这个采集任务的名字叫a1,以INFO的方式在console将接受的信息打印出来 另外一个s10: 1、新建一个1.txt,并在其中输入内容 2、bin/flume-ng avro-client -c ./conf -H s10 -p 44444 -F /home/hadoop/1.txt //这是client端,配置文件在./conf下面,将文件/home/hadoop/1.txt 通过端口44444发送给s10
标签:apach 目录 dota detail change nbsp channel -- article
原文地址:https://www.cnblogs.com/lihaozong2013/p/12306387.html