标签:分布式 直接 exception 博客 sql 贵州 https 还需 技术部
整理了一些Java方面的架构、面试资料(微服务、集群、分布式、中间件等),有需要的小伙伴可以关注公众号【程序员内点事】,无套路自行领取
本文作者:程序员内点事
更多精选
受疫情影响一直在家远程办公,公司业务进展的缓慢,老实讲活并没有那么多,每天吃饭、睡觉、逛技术社区、写博客,摸鱼摸得爽的很。早上本来还想在来个回笼觉,突然部门经理的语音消息就过来了,甩给我一个连接地址 http://www.stats.gov.cn/tjsj/tjbz/tjyqhdmhcxhfdm/2018/,要我把全国的省市名称和区域代码弄出来,建一个字典表,时限一上午。

要全国的省、市名称,建一张字典表进行存储,表结构设计相对容易,那么城市数据该怎么搞?
有两种解决办法:
辛苦点复制粘贴,说多了也就几百个而已
写个爬虫工具,一劳永逸
但作为一个程序员没有什么是不能用程序解决的,虽然工作Ctrl+C 、 Ctrl+V用的不少,像这种没有技术含量的复制粘贴还是挺丢面子的。
基于这个需求只想要城市名称,爬虫工具选的是Jsoup,Jsoup是一款Java 的HTML解析器,可直接解析某个URL地址、HTML文本内容。它提供了一套非常省力的API,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据。
Jsoup是根据HTML页面的<body>、<td>、<tr>等标签来获取文本内容的,所以先分析一下目标页面结构。打开F12查看页面结构发现,我们要的目标数据在第5个<tbody>标签 class 属性为provincetr 的 <tr> 标签里。
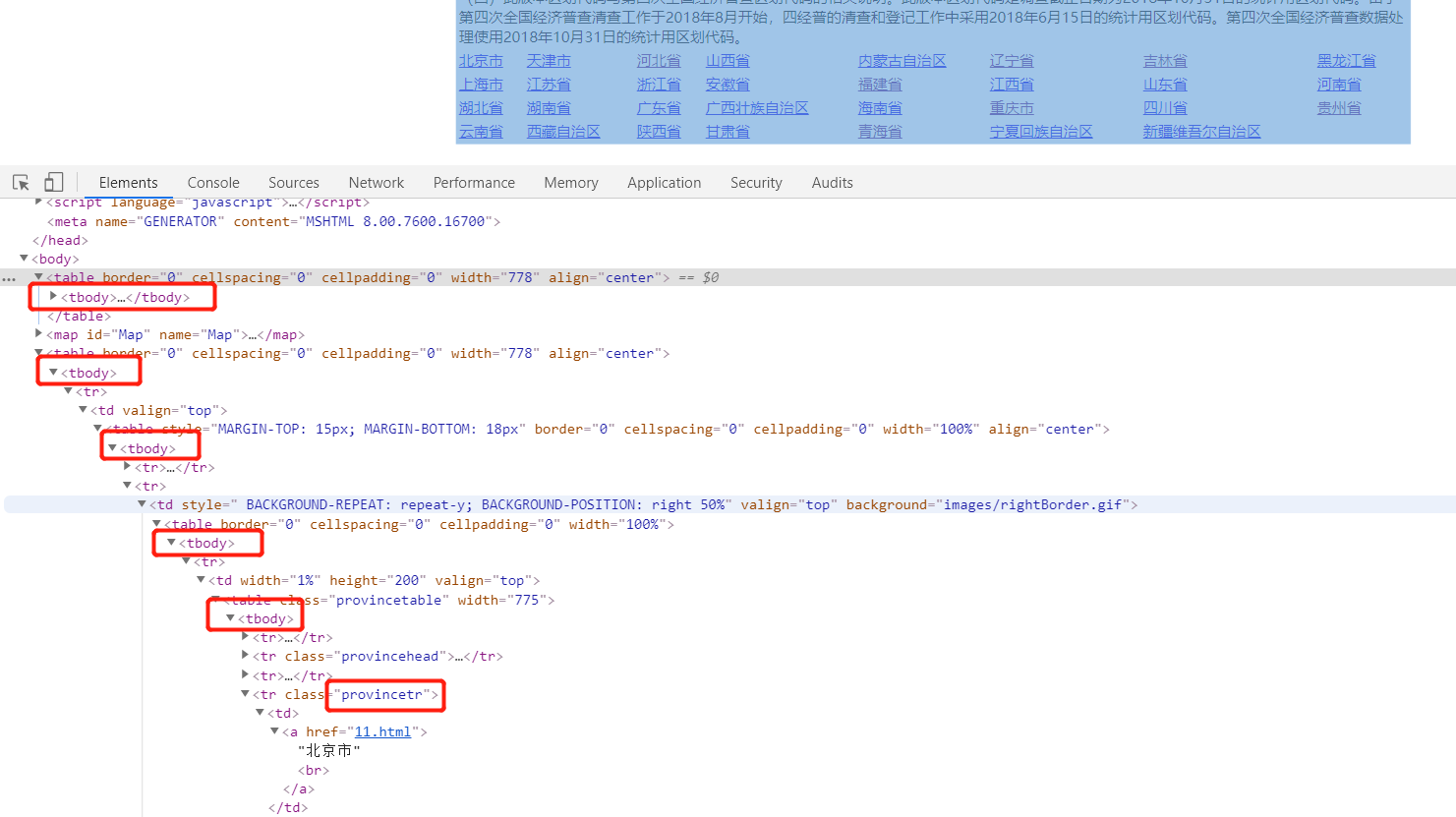
省份名称内容的页面结构如下:
<tr class="provincetr">
<td>
<a href="11.html">北京市<br></a>
</td>
<td>
<a href="12.html">天津市<br>
</td>
.........
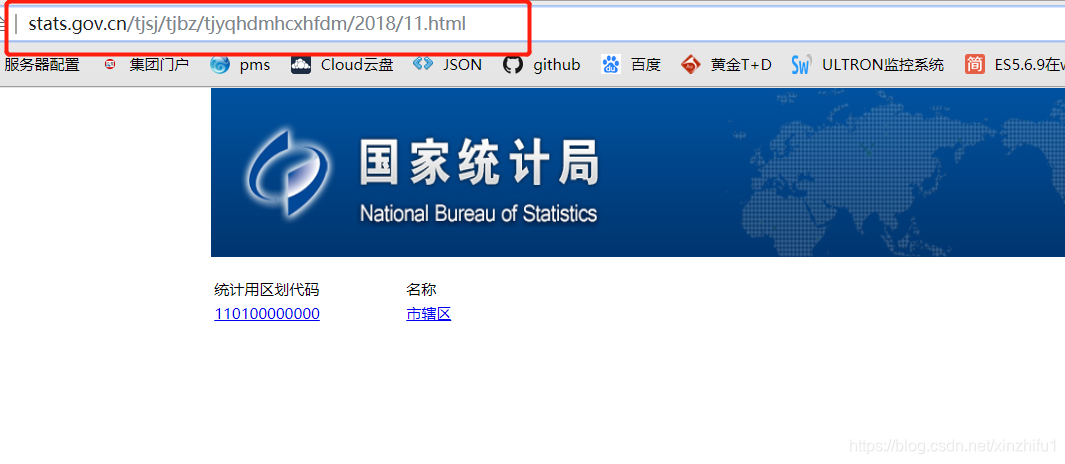
</tr>再拿到<td>标签中<a>标签属性就可以了,省份名称找到了,再看看省对应的城市名在哪里,属性href="11.html" 就是省份下对应的城市页面Url http://www.stats.gov.cn/tjsj/tjbz/tjyqhdmhcxhfdm/2018/11.html
找城市名称跟上边分析过程一样,这里就不再赘述了,既然数据位置已经确定了,那么就开始具体的爬取工作了。
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.7.3</version>
</dependency>代码的实现比较简单就两个方法而已,没有什么难度主要是得细心,捋清页面标签的嵌套结构就可以了。按照之前分析的逻辑一步一步走
/**
* @author xin
* @description 解析省份
* @date 2019/11/4 19:24
*/
public static void parseProvinceName(Map<String, Map<String, String>> map, String url) throws IOException {
/**
* 获取页面文档数据
*/
Document doc = Jsoup.connect(url).get();
/**
* 获取页面上所有的tbody标签
*/
Elements elements = doc.getElementsByTag("tbody");
/**
* 拿到第五个tbody标签
*/
Element element = elements.get(4);
/**
* 拿到tbody标签下所有的子标签
*/
Elements childrens = element.children();
/**
* 当前页面的URL
*/
String baseUri = element.baseUri();
for (Element element1 : childrens) {
Elements provincetrs = element1.getElementsByClass("provincetr");
for (Element provincetr : provincetrs) {
Elements tds = provincetr.getElementsByTag("td");
for (Element td : tds) {
String provinceName = td.getElementsByTag("a").text();
String href = td.getElementsByTag("a").attr("href");
System.out.println(provinceName + " " + baseUri + "/" + href);
map.put(provinceName, null);
/**
* 组装城市页面的URL,进入城市页面爬城市名称
*/
parseCityName(map, baseUri + "/" + href, provinceName);
}
}
}
}
在抓取城市名称的时候有一点要注意,直辖市城市的省份和城市名称是一样的
/**
* @author xin
* @description 解析城市名称
* @date 2019/11/4 19:26
*/
public static void parseCityName(Map<String, Map<String, String>> map, String url, String provinceName) throws IOException {
Document doc = Jsoup.connect(url).get();
Elements elements = doc.getElementsByTag("tbody");
Element element = elements.get(4);
Elements childrens = element.children();
/**
*
*/
String baseUri = element.baseUri();
Map<String, String> cityMap = new HashMap<>();
for (Element element1 : childrens) {
Elements citytrs = element1.getElementsByClass("citytr");
for (Element cityTag : citytrs) {
Elements tds = cityTag.getElementsByTag("td");
/**
* 直辖市,城市名就是本身
*/
String cityName = tds.get(1).getElementsByTag("a").text();
if (cityName.equals("市辖区")) {
cityName = provinceName;
}
String href1 = tds.get(1).getElementsByTag("a").attr("href");
System.out.println(cityName + " " + href1);
cityMap.put(cityName, href1);
}
}
map.put(provinceName, cityMap);
}
public class test2 {
public static void main(String[] args) throws IOException {
Map<String, Map<String, String>> map = new HashMap<>();
parseProvinceName(map, "http://www.stats.gov.cn/tjsj/tjbz/tjyqhdmhcxhfdm/2018");
System.out.println(JSON.toJSONString(map));
}
}
当前只要省份和城市名称,爬虫没有什么深度,如果还需要区县等信息,可以根据市后边的url 35/3508.html 继续往下爬取
{
"福建省": {
"龙岩市": "35/3508.html",
"南平市": "35/3507.html",
"莆田市": "35/3503.html",
"福州市": "35/3501.html",
"泉州市": "35/3505.html",
"漳州市": "35/3506.html",
"厦门市": "35/3502.html",
"三明市": "35/3504.html",
"宁德市": "35/3509.html"
},
"西藏自治区": {
"拉萨市": "54/5401.html",
"昌都市": "54/5403.html",
"日喀则市": "54/5402.html",
"那曲市": "54/5406.html",
"林芝市": "54/5404.html",
"山南市": "54/5405.html",
"阿里地区": "54/5425.html"
},
"贵州省": {
"贵阳市": "52/5201.html",
"毕节市": "52/5205.html",
"铜仁市": "52/5206.html",
"六盘水市": "52/5202.html",
"遵义市": "52/5203.html",
"黔西南布依族苗族自治州": "52/5223.html",
"安顺市": "52/5204.html",
"黔东南苗族侗族自治州": "52/5226.html",
"黔南布依族苗族自治州": "52/5227.html"
},
"上海市": {
"上海市": "31/3101.html"
},
"湖北省": {
"黄冈市": "42/4211.html",
"孝感市": "42/4209.html",
"恩施土家族苗族自治州": "42/4228.html",
"省直辖县级行政区划": "42/4290.html",
"襄阳市": "42/4206.html",
"鄂州市": "42/4207.html",
"十堰市": "42/4203.html",
"咸宁市": "42/4212.html",
"黄石市": "42/4202.html",
"荆州市": "42/4210.html",
"随州市": "42/4213.html",
"宜昌市": "42/4205.html",
"武汉市": "42/4201.html",
"荆门市": "42/4208.html"
},
"湖南省": {
"湘潭市": "43/4303.html",
"衡阳市": "43/4304.html",
"张家界市": "43/4308.html",
"益阳市": "43/4309.html",
"岳阳市": "43/4306.html",
"娄底市": "43/4313.html",
"株洲市": "43/4302.html",
"常德市": "43/4307.html",
"湘西土家族苗族自治州": "43/4331.html",
"郴州市": "43/4310.html",
"邵阳市": "43/4305.html",
"长沙市": "43/4301.html",
"永州市": "43/4311.html",
"怀化市": "43/4312.html"
},
"广东省": {
"河源市": "44/4416.html",
"韶关市": "44/4402.html",
"茂名市": "44/4409.html",
"汕头市": "44/4405.html",
"清远市": "44/4418.html",
"深圳市": "44/4403.html",
"珠海市": "44/4404.html",
"广州市": "44/4401.html",
"肇庆市": "44/4412.html",
"中山市": "44/4420.html",
"江门市": "44/4407.html",
"云浮市": "44/4453.html",
"惠州市": "44/4413.html",
"湛江市": "44/4408.html",
"东莞市": "44/4419.html",
"揭阳市": "44/4452.html",
"阳江市": "44/4417.html",
"佛山市": "44/4406.html",
"汕尾市": "44/4415.html",
"潮州市": "44/4451.html",
"梅州市": "44/4414.html"
}
.......
}Jsoup爬取页面数据对网络的依赖比较高,像我500块一年50M的方正宽带快要卡出翔了,平均执行三次才有一次成功,我太难了!
Exception in thread "main" java.net.SocketTimeoutException: Read timed out
at java.net.SocketInputStream.socketRead0(Native Method)
at java.net.SocketInputStream.socketRead(SocketInputStream.java:116)
at java.net.SocketInputStream.read(SocketInputStream.java:171)
at java.net.SocketInputStream.read(SocketInputStream.java:141)
at java.io.BufferedInputStream.fill(BufferedInputStream.java:246)
at java.io.BufferedInputStream.read1(BufferedInputStream.java:286)
at java.io.BufferedInputStream.read(BufferedInputStream.java:345)
at sun.net.www.http.HttpClient.parseHTTPHeader(HttpClient.java:735)
at sun.net.www.http.HttpClient.parseHTTP(HttpClient.java:678)
at sun.net.www.protocol.http.HttpURLConnection.getInputStream0(HttpURLConnection.java:1569)
at sun.net.www.protocol.http.HttpURLConnection.getInputStream(HttpURLConnection.java:1474)
at java.net.HttpURLConnection.getResponseCode(HttpURLConnection.java:480)
at org.jsoup.helper.HttpConnection$Response.execute(HttpConnection.java:443)
at org.jsoup.helper.HttpConnection$Response.execute(HttpConnection.java:465)
at org.jsoup.helper.HttpConnection$Response.execute(HttpConnection.java:424)
at org.jsoup.helper.HttpConnection.execute(HttpConnection.java:178)
at org.jsoup.helper.HttpConnection.get(HttpConnection.java:167)
at com.xinzf.project.jsoup.test2.parseProvinceName(test2.java:32)
at com.xinzf.project.jsoup.test2.main(test2.java:17)
从分析页面到编写代码花费的时间,可能要比简单的复制粘贴还要长,但我依然选择用程序解决问题,并不是因为我有多勤快,反而是因为我很懒,你品,你细品!
今天就说这么多,如果本文对您有一点帮助,希望能得到您一个点赞??哦
您的认可才是我写作的动力!
整理了一些Java方面的架构、面试资料(微服务、集群、分布式、中间件等),有需要的小伙伴可以关注公众号【程序员内点事】,无套路自行领取
标签:分布式 直接 exception 博客 sql 贵州 https 还需 技术部
原文地址:https://www.cnblogs.com/chengxy-nds/p/12307701.html