标签:ati core type derby order 处理 datanode deb none
配置信息:
server: port: 56081 servlet: context-path: /sharding-jdbc-simple-demo spring: application: name: sharding-jdbc-simple-demo http: encoding: enabled: true charset: utf-8 force: true main: allow-bean-definition-overriding: true shardingsphere: datasource: #新增一个m2库 names: m1,m2 m1: type: com.alibaba.druid.pool.DruidDataSource driverClassName: com.mysql.jdbc.Driver url: jdbc:mysql://rm-xxxxxxxx.mysql.rds.aliyuncs.com:3306/order_db_1?useUnicode=true username: root password: 123456 m2: type: com.alibaba.druid.pool.DruidDataSource driverClassName: com.mysql.jdbc.Driver url: jdbc:mysql://rm-xxxxxxxx.mysql.rds.aliyuncs.com:3306/order_db_2?useUnicode=true username: root password: 123456 sharding: tables: t_order: # 分库策略,以user_id为分片键,分片策略为user_id % 2 + 1,user_id为偶数操作m1数据源,否则操作m2。 databaseStrategy: inline: shardingColumn: user_id algorithmExpression: m$->{user_id % 2 + 1} # 指定t_order表的数据分布情况,配置数据节点 actualDataNodes: m$->{1..2}.t_order_$->{1..2} tableStrategy: inline: shardingColumn: order_id algorithmExpression: t_order_$->{order_id % 2 + 1} # 指定t_order表的分片策略,分片策略包括分片键和分片算法 keyGenerator: type: SNOWFLAKE column: order_id props: sql: show: true mybatis: configuration: map-underscore-to-camel-case: true swagger: enable: true logging: level: root: info org.springframework.web: info com.topcheer.dbsharding: debug druid.sql: debug
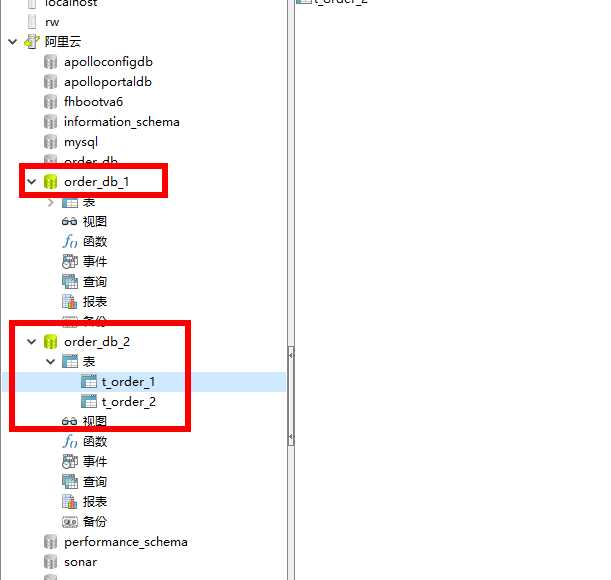
再mysql上建库建表:
Sharding-JDBC支持以下几种分片策略:
不管理分库还是分表,策略基本一样。
standard :标准分片策略,对应StandardShardingStrategy。提供对SQL语句中的=, IN和BETWEEN AND的
分片操作支持。StandardShardingStrategy只支持单分片键,提供PreciseShardingAlgorithm和
RangeShardingAlgorithm两个分片算法。PreciseShardingAlgorithm是必选的,用于处理=和IN的分片。
RangeShardingAlgorithm是可选的,用于处理BETWEEN AND分片,如果不配置
RangeShardingAlgorithm,SQL中的BETWEEN AND将按照全库路由处理。
complex:符合分片策略,对应ComplexShardingStrategy。复合分片策略。提供对SQL语句中的=, IN和
BETWEEN AND的分片操作支持。ComplexShardingStrategy支持多分片键,由于多分片键之间的关系复
杂,因此并未进行过多的封装,而是直接将分片键值组合以及分片操作符透传至分片算法,完全由应用开发
者实现,提供最大的灵活度。
inline :行表达式分片策略,对应InlineShardingStrategy。使用Groovy的表达式,提供对SQL语句中的=和
IN的分片操作支持,只支持单分片键。对于简单的分片算法,可以通过简单的配置使用,从而避免繁琐的Java
代码开发,如: t_user_$ ->{u_id % 8} 表示t_user表根据u_id模8,而分成8张表,表名称为 t_user_0 到t_user_7 。
hint :Hint分片策略,对应HintShardingStrategy。通过Hint而非SQL解析的方式分片的策略。对于分片字段
非SQL决定,而由其他外置条件决定的场景,可使用SQL Hint灵活的注入分片字段。例:内部系统,按照员工
登录主键分库,而数据库中并无此字段。SQL Hint支持通过Java API和SQL注释(待实现)两种方式使用。
none :不分片策略,对应NoneShardingStrategy。不分片的策略。
目前例子中都使用inline分片策略,若对其他分片策略细节若感兴趣,请查阅官方文档:
https://shardingsphere.apache.org
进行测试:
@Test public void testInsertOrder(){ for(int i=1;i<20;i++){ orderDao.insertOrder(new BigDecimal(i),2L,"SUCCESS"); } }
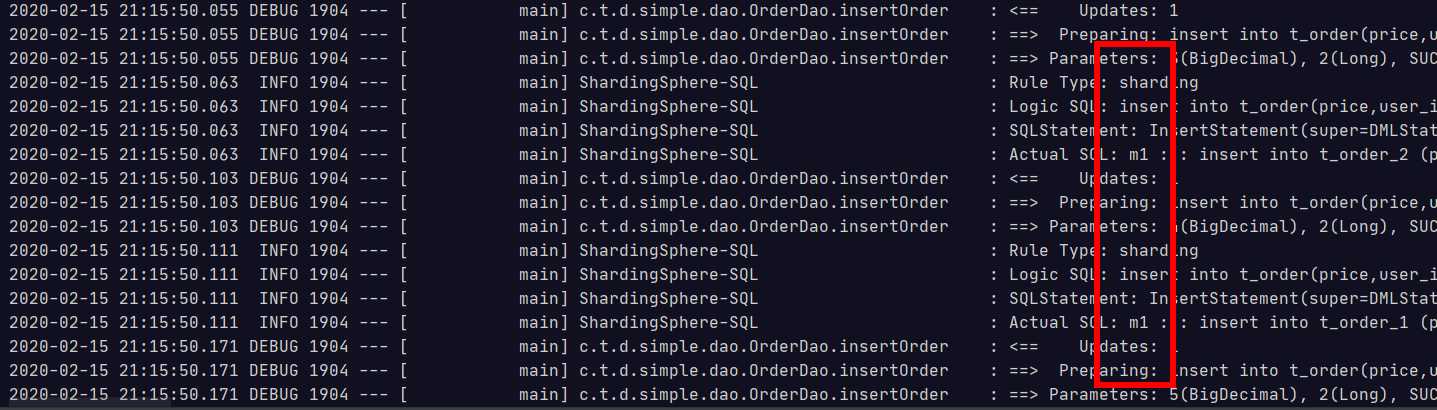
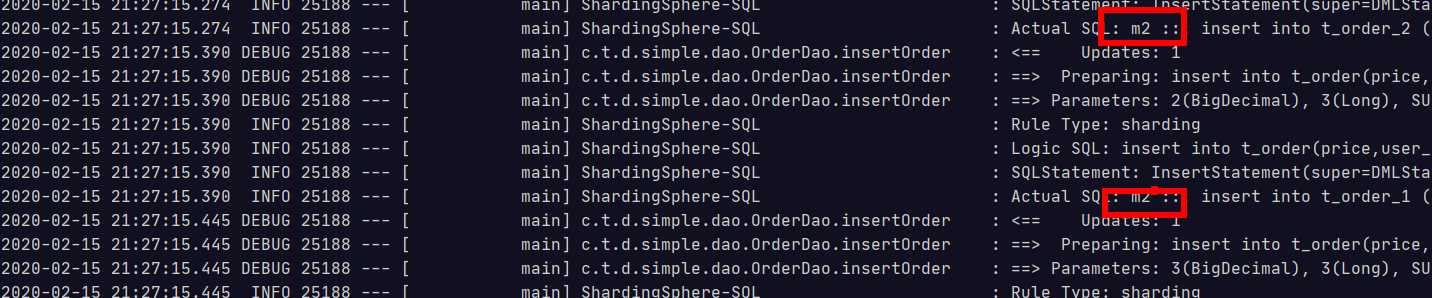
当把user_id改成奇数的时候
@Test public void testInsertOrder(){ for(int i=1;i<20;i++){ orderDao.insertOrder(new BigDecimal(i),3L,"SUCCESS"); } }
进行查询测试:
@Test public void testSelectOrderbyIds(){ List<Long> ids = new ArrayList<>(); ids.add(435548833548599296L); ids.add(435548901945114624L); List<Map> maps = orderDao.selectOrderbyIds(ids); System.out.println(maps); }
再没有ID的情况下,因为都是偶数,因为只会差条数据
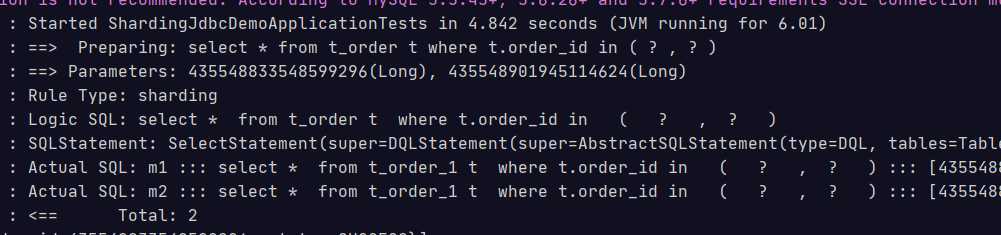
假如改成一奇一偶,则会查4条SQL
标签:ati core type derby order 处理 datanode deb none
原文地址:https://www.cnblogs.com/dalianpai/p/12313830.html