标签:orm 数据字典 dao evel ted config img std bsp
前面已经介绍过,垂直分库是指按照业务将表进行分类,分布到不同的数据库上面,每个库可以放在不同的服务器
上,它的核心理念是专库专用。接下来看一下如何使用Sharding-JDBC实现垂直分库。
(1)创建数据库
创建数据库user_db 的t_user表中
CREATE TABLE`t_user`( `user_id` bigint(20)NOT NULL COMMENT ‘用户id‘, `fullname` varchar(255)CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT ‘用户姓名‘, `user_type` char(1) DEFAULT NULL COMMENT‘用户类型‘, PRIMARY KEY(`user_id`) USING BTREE )ENGINE=InnoDB CHARACTER SET=utf8 COLLATE=utf8_general_ci ROW_FORMAT=Dynamic;
修改配置信息
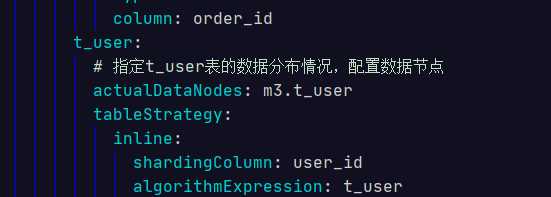
server: port: 56081 servlet: context-path: /sharding-jdbc-simple-demo spring: application: name: sharding-jdbc-simple-demo http: encoding: enabled: true charset: utf-8 force: true main: allow-bean-definition-overriding: true shardingsphere: datasource: #新增一个m2库 names: m2,m3,m1 m1: type: com.alibaba.druid.pool.DruidDataSource driverClassName: com.mysql.jdbc.Driver url: jdbc:mysql://rm-xxxxxx.mysql.rds.aliyuncs.com:3306/order_db_1?useUnicode=true username: root password: 123456 m2: type: com.alibaba.druid.pool.DruidDataSource driverClassName: com.mysql.jdbc.Driver url: jdbc:mysql://rm-xxxxxxxxx.mysql.rds.aliyuncs.com:3306/order_db_2?useUnicode=true username: root password: 123456 m3: type: com.alibaba.druid.pool.DruidDataSource driverClassName: com.mysql.jdbc.Driver url: jdbc:mysql://rm-xxxxxxx.mysql.rds.aliyuncs.com:3306/user_db?useUnicode=true username: root password: 123456 sharding: tables: t_order: # 分库策略,以user_id为分片键,分片策略为user_id % 2 + 1,user_id为偶数操作m1数据源,否则操作m2。 databaseStrategy: inline: shardingColumn: user_id algorithmExpression: m$->{user_id % 2 + 1} # 指定t_order表的数据分布情况,配置数据节点 actualDataNodes: m$->{1..2}.t_order_$->{1..2} tableStrategy: inline: shardingColumn: order_id algorithmExpression: t_order_$->{order_id % 2 + 1} # 指定t_order表的分片策略,分片策略包括分片键和分片算法 keyGenerator: type: SNOWFLAKE column: order_id t_user: # 指定t_user表的数据分布情况,配置数据节点 actualDataNodes: m3.t_user tableStrategy: inline: shardingColumn: user_id algorithmExpression: t_user broadcast-tables: t_dict props: sql: show: true mybatis: configuration: map-underscore-to-camel-case: true swagger: enable: true logging: level: root: info org.springframework.web: info com.topcheer.dbsharding: debug druid.sql: debug
/** * Created by Administrator. */ @Mapper @Component public interface UserDao { /** * 新增用户 * @param userId 用户id * @param fullname 用户姓名 * @return */ @Insert("insert into t_user(user_id, fullname) value(#{userId},#{fullname})") int insertUser(@Param("userId") Long userId, @Param("fullname") String fullname); /** * 根据id列表查询多个用户 * @param userIds 用户id列表 * @return */ @Select({"<script>", " select", " * ", " from t_user t ", " where t.user_id in", "<foreach collection=‘userIds‘ item=‘id‘ open=‘(‘ separator=‘,‘ close=‘)‘>", "#{id}", "</foreach>", "</script>" }) List<Map> selectUserbyIds(@Param("userIds") List<Long> userIds); /** * 根据id列表查询多个用户 * @param userIds 用户id列表 * @return */ @Select({"<script>", " select", " * ", " from t_user t ,t_dict b", " where t.user_type = b.code and t.user_id in", "<foreach collection=‘userIds‘ item=‘id‘ open=‘(‘ separator=‘,‘ close=‘)‘>", "#{id}", "</foreach>", "</script>" }) List<Map> selectUserInfobyIds(@Param("userIds") List<Long> userIds); }
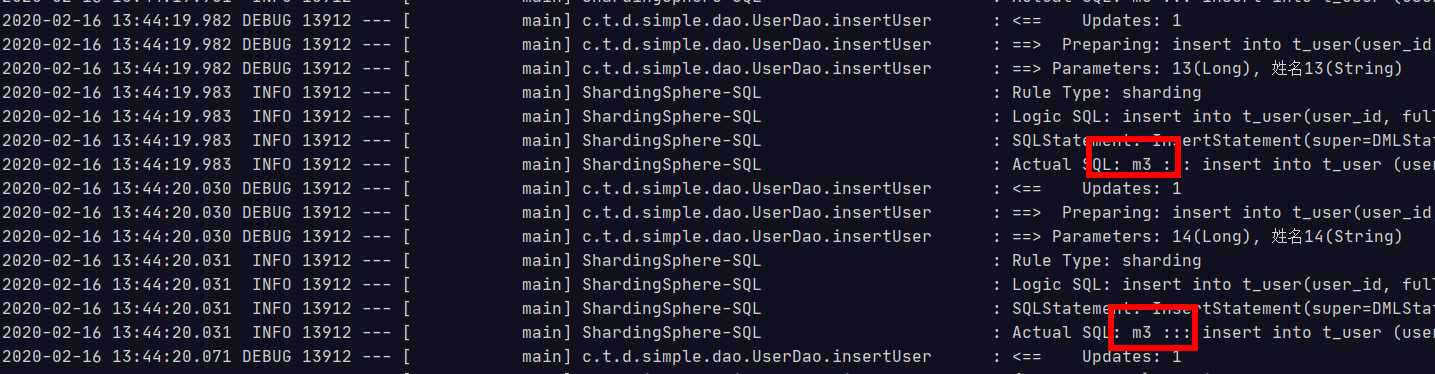
测试插入方法
@Test public void testInsertUser(){ for (int i = 10 ; i<14; i++){ Long id = i + 1L; userDao.insertUser(id,"姓名"+ id ); } }
测试查询方法:
@Test public void testSelectUserbyIds(){ List<Long> userIds = new ArrayList<>(); userIds.add(1L); userIds.add(2L); List<Map> users = userDao.selectUserbyIds(userIds); System.out.println(users); }

公共表
公共表属于系统中数据量较小,变动少,而且属于高频联合查询的依赖表。参数表、数据字典表等属于此类型。可
以将这类表在每个数据库都保存一份,所有更新操作都同时发送到所有分库执行。接下来看一下如何使用
Sharding-JDBC实现公共表。
(1)创建数据库
分别在user_db、order_db_1、order_db_2中创建t_dict表:
CREATE TABLE `t_dict`( `dict_id` bigint(20) NOT NULL COMMENT ‘字典id‘, `type` varchar(50) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT ‘字典类型‘, `code` varchar(50) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT ‘字典编码‘, `value` varchar(50)CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT ‘字典值‘, PRIMARY KEY(`dict_id`) USING BTREE )ENGINE=InnoDB CHARACTER SET=utf8 COLLATE=utf8_general_ci ROW_FORMAT=Dynamic;
@Mapper @Component public interface DictDao { /** * 新增字典 * @param type 字典类型 * @param code 字典编码 * @param value 字典值 * @return */ @Insert("insert into t_dict(dict_id,type,code,value) value(#{dictId},#{type},#{code},#{value})") int insertDict(@Param("dictId") Long dictId, @Param("type") String type, @Param("code") String code, @Param("value") String value); /** * 删除字典 * @param dictId 字典id * @return */ @Delete("delete from t_dict where dict_id = #{dictId}") int deleteDict(@Param("dictId") Long dictId); }
测试方法:
@Test public void testInsertDict(){ dictDao.insertDict(3L,"user_type","2","超级管理员"); dictDao.insertDict(4L,"user_type","3","二级管理员"); }

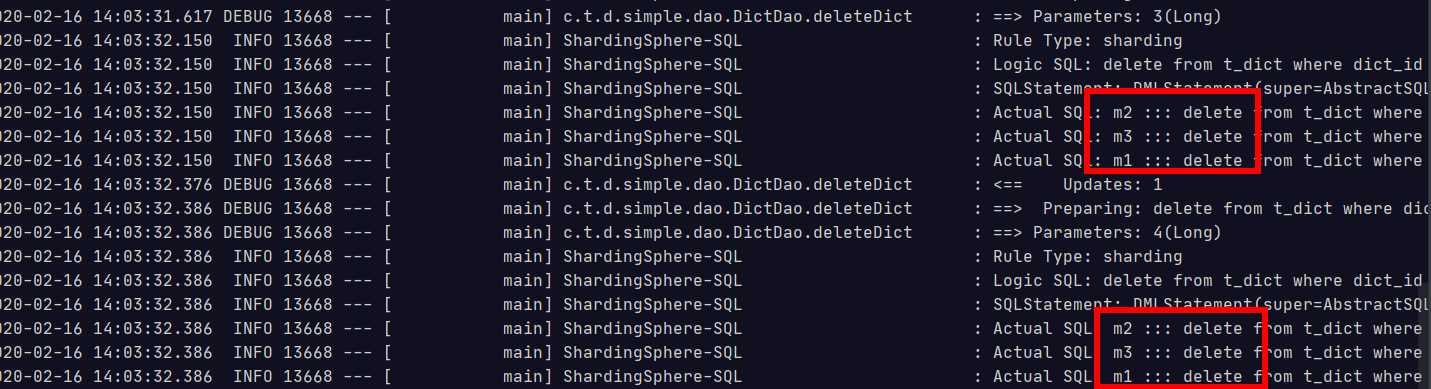
测试删除
@Test public void testDeleteDict(){ dictDao.deleteDict(3L); dictDao.deleteDict(4L); }
测试关联:
@Test public void testSelectUserInfobyIds(){ List<Long> userIds = new ArrayList<>(); userIds.add(1L); userIds.add(2L); List<Map> users = userDao.selectUserInfobyIds(userIds); System.out.println(users); }

补充:
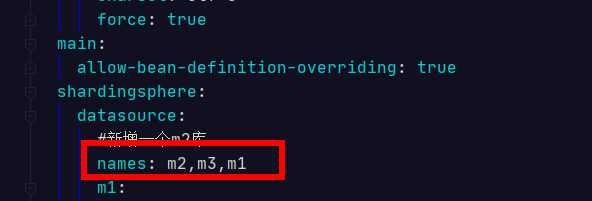
假如有些表没有分库也没有分表,而且有很多的话,应该怎么配置,就开始测试了一下。
在随便的一个库中建了一个表,没有指定节点,也没有配置别的信息,运行接口直接报错,说不到表。
个人猜想是不是和前面的库的配置顺序有关系,把表所在的库放在最后面,最后即可查询成功。
标签:orm 数据字典 dao evel ted config img std bsp
原文地址:https://www.cnblogs.com/dalianpai/p/12316719.html