标签:class rev 文本编辑器 code 字符 导入 编译器 col 编码问题
首先,要想打印汉字,必须考虑到编码问题。在windows下,由于系统使用GBK编码,而GCC解析时使用UTF-8而会导致以下代码运行时出现乱码:
#include <stdio.h> int main() { char *str = "你好,世界!"; printf("%s\n", str); return 0; }

解决方法为:使用“-fexec-charset=gbk”命令
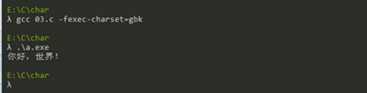
解决了编码问题,我们还需要了解几点:
根据这几点,我们可以打印出汉字以及它们的编码:
#include <stdio.h> #include <string.h> int main() { // str为字符指针,指向一个字符字面量,这个字符字面量由‘\0‘结尾 char *str = "你好,世界!Hello, world!"; // chr为字符指针,指向str所指向的字符字面量的第一个字符的地址,即‘你‘字符的两个char中的第一个 char *chr = str; printf("%zu %s\n", strlen(str), str); // 如果遇到‘\0‘,说明字符串结束了 while (*chr != ‘\0‘) { // 如果chr的编码为负数,则说明遇到了一个汉字 if (*chr < 0) { // 打印汉字及汉字的编码 // 注意两个char必须紧紧跟着打印(%c%c),否则会打印出 ?? printf("%c%c: %d%d\n", *chr, *(chr+1), *(chr), *(chr+1)); // chr自增两个字节(因为每个汉字都由两个char组成) chr += 2; } else { // 打印英文字符 printf("%c: %d\n", *chr, *chr); // chr自增一个字节 ++chr; } } return 0; }
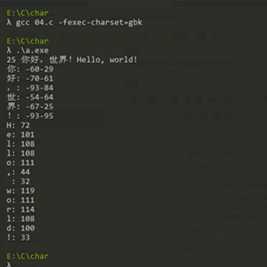
从上图,我们可以看出,这个字符串占据了25个字节,4个汉字加2个全角符号占据了12个字节,再加上23个英文字符,总共25个字节。我们可以从下图更清晰地看出str的构造:
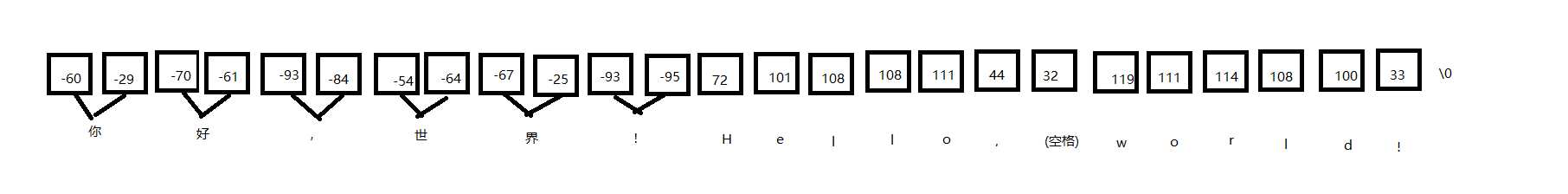
但是,根据我们在网上查询的结果,汉字‘你’的GBK编码应为:C4E3,但是在这里,却打印出了:-60-29,这是为什么呢?

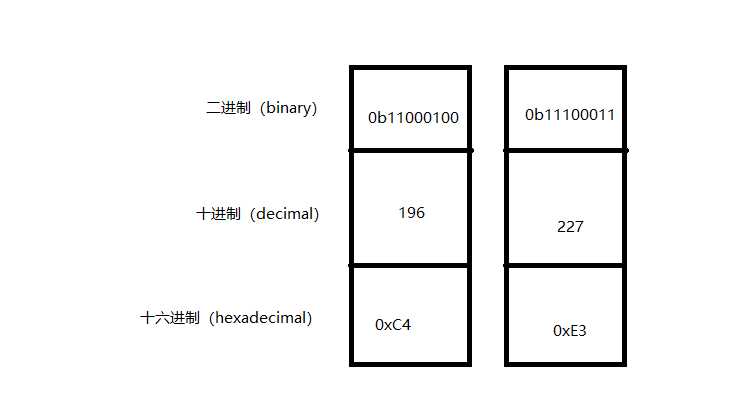
这里涉及到进制的问题,可能-60-29是十六进制数C4E3的十进制数?
首先,我们先通过Python看看C4E3的二进制数以及十进制数。这好像跟-60-29根本不沾边。
我们先看看下面的代码,导入<limits.h>头文件,看看char类型的取值范围为多少:
#include <stdio.h> #include <limits.h> int main() { printf("[%d ~ %d]\n", CHAR_MIN, CHAR_MAX); printf("%c%c\n", 0xC4, 0xE3);return 0; }

我们可以看到:char类型的取值范围为[-128 ~ 127],但是我们却可以打印出汉字”你“。这是为什么呢?明明char的取值范围最多127,而汉字“你”的两个字符分别为:196和227,都超过了这个值。其实这是因为,C语言将这两个数字的二进制数作为负数处理。C中的char类型有1个字节,占8位,而它的最高位为符号位,当它为0时为正,1时则为负。C通过对正数做补码操作得到负数。补码,即对一个二进制数取反,然后再加1。比如,0xC4的二进制数为0b11000100,我们可以看到最高位1,在C中这个数就是负数。我们可以通过对这个二进制数做补码操作,得到0b00111100,即60。所以0b11000100在C中表示为-60。
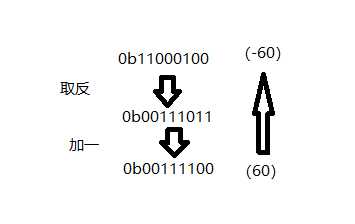
从以上,我们可以发现,GBK编码中,一个汉字占两字节。因为C中char类型只占一个字节,所以需要使用两个char类型来表示汉字。一个字节能够表示的范围为[0 ~ 256],因为C中char为有符号类型,char的表示范围为[-128 ~ 127],所以在遇到大于127的数字时,会被char表示为负数。
标签:class rev 文本编辑器 code 字符 导入 编译器 col 编码问题
原文地址:https://www.cnblogs.com/noonjuan/p/12319727.html