标签:随机化 com heap 为什么 alt 其他 log 步骤 分布
在未排序的数组中找到第 k 个最大的元素。请注意,你需要找的是数组排序后的第 k 个最大的元素,而不是第 k 个不同的元素。
示例 1:
输入: [3,2,1,5,6,4] 和 k = 2
输出: 5
示例 2:
输入: [3,2,3,1,2,4,5,5,6] 和 k = 4
输出: 4
说明:
你可以假设 k 总是有效的,且 1 ≤ k ≤ 数组的长度。
这道题属于一个很经典的问题,即求数据集中的最大第k个或者最小的前k个之类。
常规方法有以下几种:
O(n logn)。
O(n log k)
用一个大小为k的堆,如果是求第k大,那么我们使用最小堆(为什么是最小堆看不懂没关系,这就说)。比如一个数据集有n个元素,假设我们(神奇的提前知道了!)最大的几个元素依次是x1,x2,x3,且x1、x2、x3都分布在数据集的后半部(假设n很大),而且k为3,即我们想求的就是x3。
我们定义一个长度3的容器heap,先放入前3个数据,建立最小堆。然后我们从第4个元素开始遍历,每次遍历到一个元素nums[i],如果nums[i]>heap.top(),那么我们就pop掉当前的堆顶,并放入nums[i],重新维护最小堆性质。遍历完毕之后,最小堆的堆顶就是我们要求的数。
重申一次,我们想找的TOP-K,在本问题中就是前3大的数字。由于最小堆的堆顶是整个堆里最小的数字,所以如果有其他数字比这个堆顶大,说明这个堆顶一定不在最终的前3大数字里,所以我们理所当然的用当前数字去替换当前堆顶。
由于我们已经知道了x1、x2、x3是最大的三个数,遍历到他们时一定都有x1/x2/x3大于当时各自的堆顶从而push进堆,并且不可能有第4个数字比他们三个大从而把他们三个踢出堆。故最终堆里的三个数字就是x1、x2、x3,而且堆顶是三个数中最小的那个(x3),也就是我们想要的第3大的数。
时间复杂度为n logk,遍历n个元素,每次调整堆需要logk时间,在k比n小的情况下,比第一种排序算法节省大量时间。
容易理解,如果求第k小,那么我们对应的使用最大堆,解法完全一样。
1 class Solution { 2 public: 3 int findKthLargest(vector<int>& nums, int k) 4 { 5 priority_queue<int,vector<int>,greater<int> >min_heap; 6 for(int num:nums) 7 { 8 min_heap.push(num); 9 if(min_heap.size()>k) 10 { 11 min_heap.pop(); 12 } 13 } 14 return min_heap.top(); 15 } 16 };
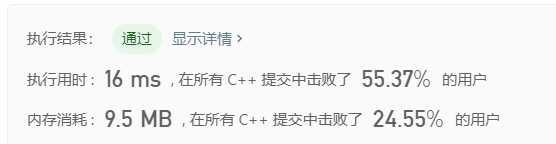
O(n),将数组划分为左右两部分,如果中枢轴右侧元素大于k个,那对右侧区间继续划分,否则对左侧区间进行划分。
和快排的区别在于,快排划分之后,分别对左右子区间递归划分,时间是n+2*n/2+4*n/4+...=O(n logn)
该算法只会对一侧子区间进行递归划分,时间为n+n/2+n/4+n/8+...=O(n)
注意在取基准数的时候一定要随机化处理,否则时间效率会大大增加!
1 class Solution { 2 public: 3 int findKthLargest(vector<int>& nums, int k) 4 { 5 srand(time(0)); 6 return partition(nums,0,nums.size()-1,k); 7 } 8 int partition(vector<int>& nums,int le,int ri,int k){ 9 if(le>=ri){ 10 return k==1?nums[le]:-1; 11 } 12 int random_pos=rand()%(ri-le); 13 swap(nums[le+random_pos],nums[ri]);//随机化基准数,基准数为nums[ri] 14 int i=le-1,j=le,stable=nums[ri]; 15 while(j<ri){ 16 if(nums[j]<stable){ 17 swap(nums[++i],nums[j]); 18 } 19 ++j; 20 } 21 swap(nums[i+1],nums[ri]); 22 //i+1为划分枢轴 23 if(ri-i==k){ 24 return nums[i+1]; 25 } 26 else if(ri-i>k){ 27 return partition(nums,i+2,ri,k); 28 } 29 else{ 30 return partition(nums,le,i,k-ri+i); 31 } 32 } 33 };
基准数不加随机化:
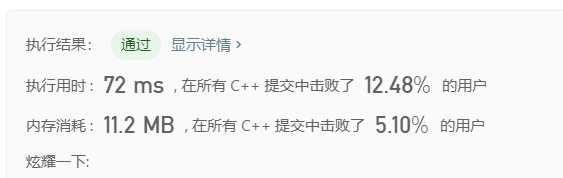
基准数加随机化:
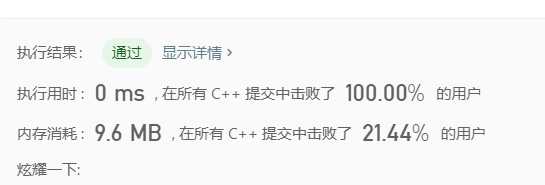
标签:随机化 com heap 为什么 alt 其他 log 步骤 分布
原文地址:https://www.cnblogs.com/FdWzy/p/12321325.html