标签:image eterm inf follow parameter div lua net zed
Repeat the process...
Supervised: Give feedback
Unsupervised: No feedback, find parttens
Reinforcement: Train the algorithm to works in a enviorment based on the rewords it receives. (Just like training your dog)
f(x) = x * w + b
x: input
w: coefficient / weight
b: intercept / bias
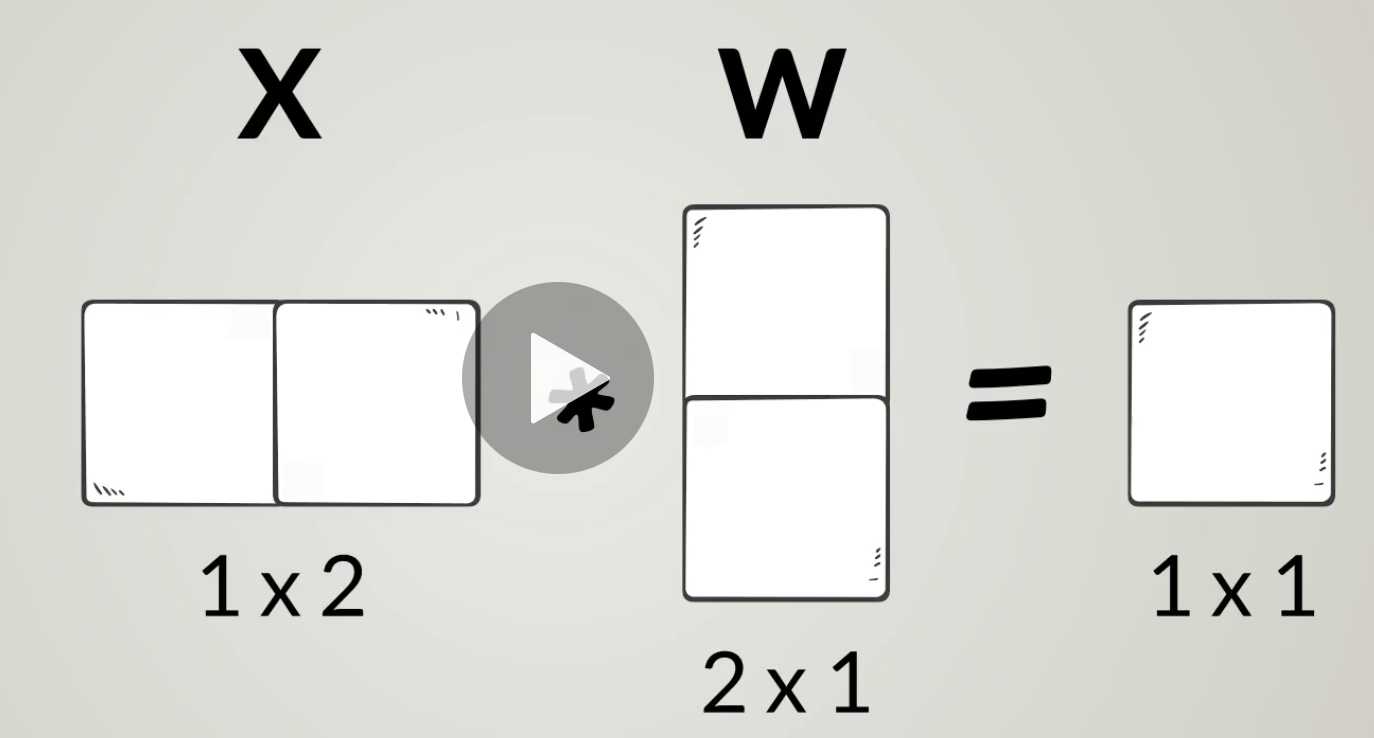
x, w are both vectors:
x: 1 * 2
w: 2 * 1
f(x): 1 * 1
Notice that the lienar model doesn‘t chage, it is still:
f(x) = x * w + b
Lienar Model: multi inputs and multi outputs:

For ‘W‘, the first index is always the same as X; the second index is always the same as ouput Y.
If there is K inputs and M outputs, the number of Weigths would be K * M
The number of bias is equal to the number of ouputs: M.
N * M = (N * K) * (K * M) + 1 * M
Each model is determined by its weights and biases.
Is the measure used to evaluate how well the model‘s output match the desired correct values.

Expect cross-entropy should be lower.



Until one point, the following value never update anymore.
The picture looks like this:
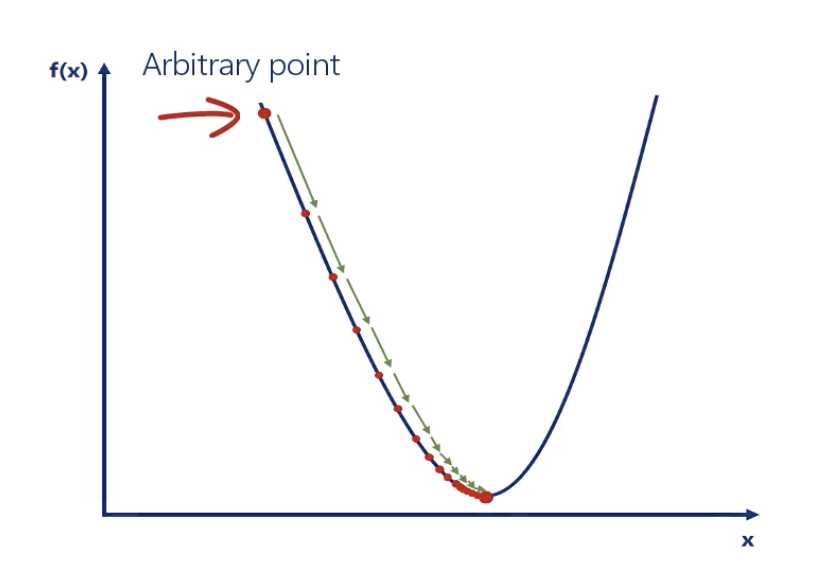
Generally, we want the learning rate to be:
High enough, so we can reach the closest minimum in a rational amount of time
Low enough, so we don‘t oscillate around the minimum

N-parameter gradient descent
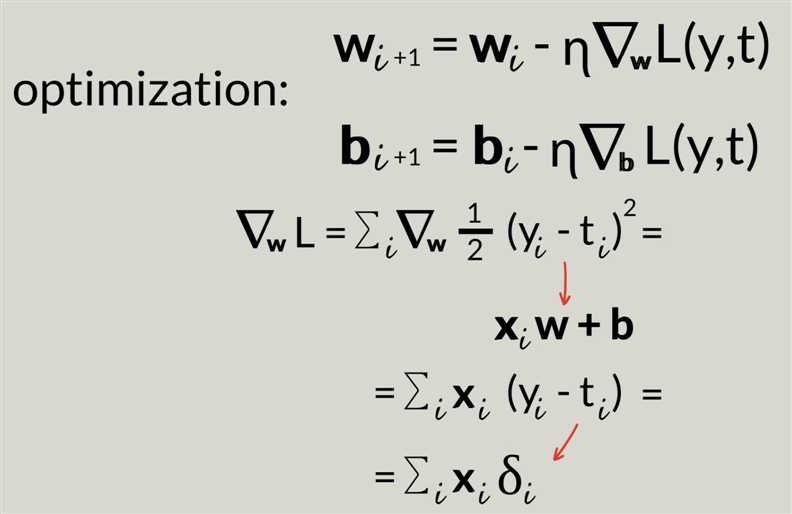
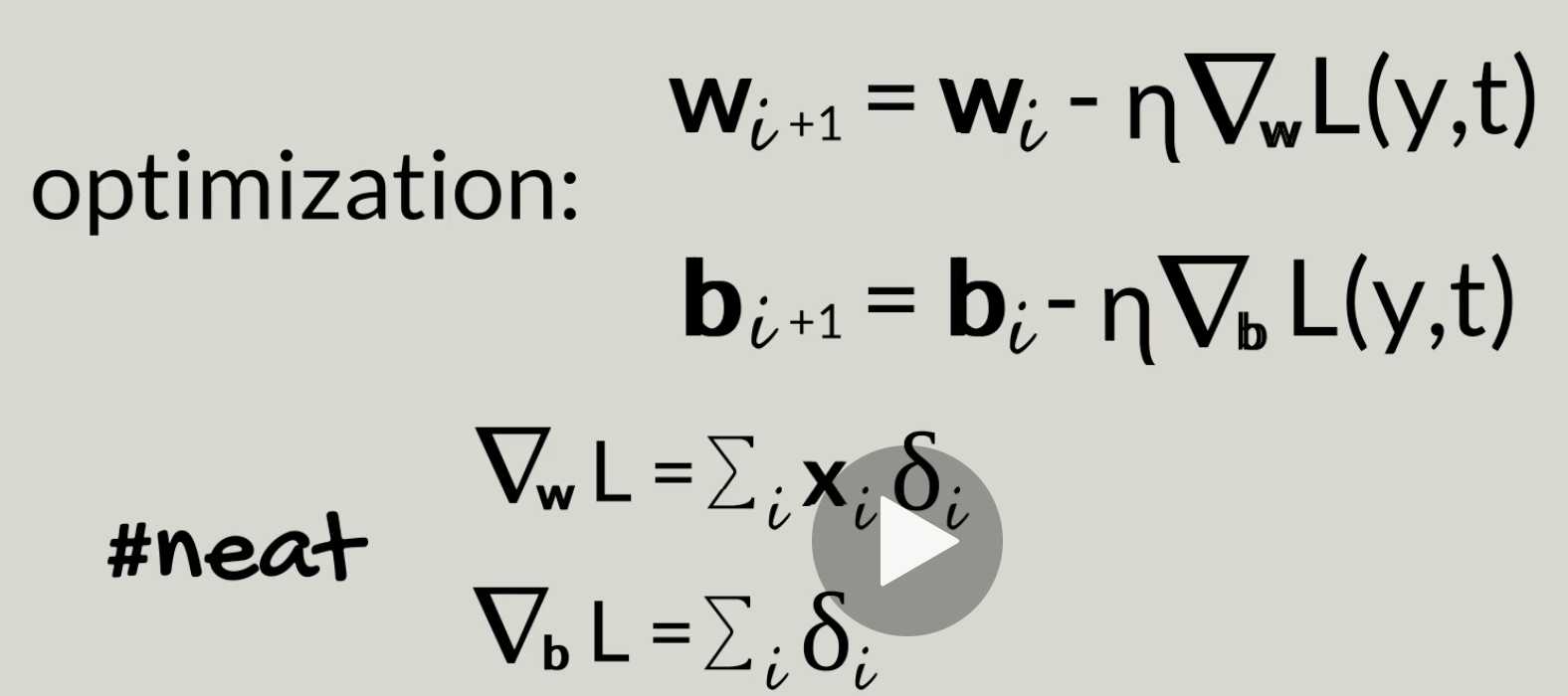
[ML] 2. Introduction to neural networks
标签:image eterm inf follow parameter div lua net zed
原文地址:https://www.cnblogs.com/Answer1215/p/12324642.html