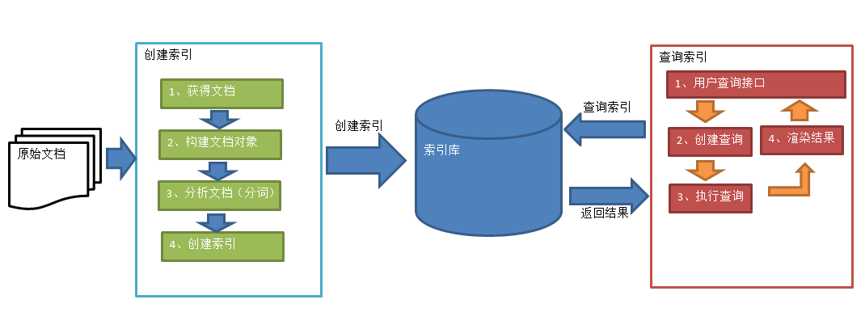
标签:apache alt 搜索 结构 索引 系统 取出 分词 bsp
Lucene
原文地址:https://www.cnblogs.com/xuweiweiwoaini/p/12336135.html