标签:方法 可迭代对象 level dict media last ref com 展示
分组统计groupby功能:
Dataframe在行(axis=0)或列(axis=1)上进行分组,将一个函数应用到各个分组并产生一个新值,然后函数执行结果被合并到最终的结果对象中。
df.groupby(by=None, axis=0, level=None, as_index=True, sort=True, group_keys=True, squeeze=False, **kwargs)import pandas as pd
import numpy as np
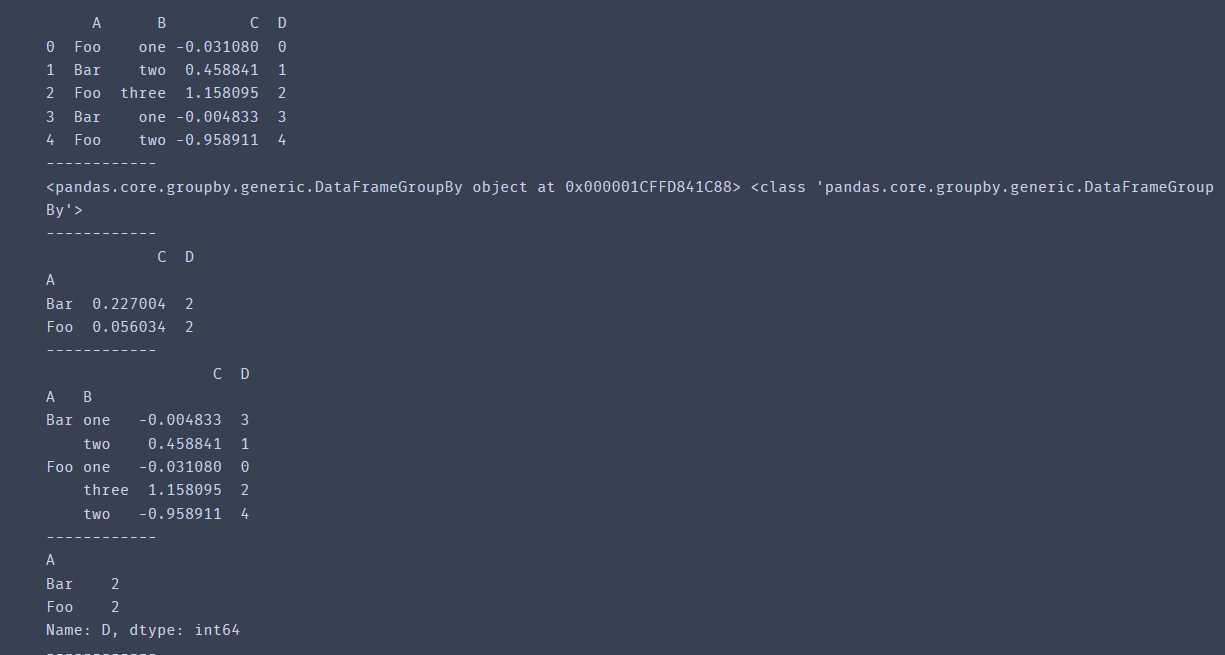
df = pd.DataFrame({'A':['Foo','Bar','Foo','Bar','Foo'],
'B':['one','two','three','one','two'],
'C':np.random.randn(5),
'D':range(5)
})
print(df)
print('------------')
print(df.groupby('A'),type(df.groupby('A'))) #此处得到的是一个groupby对象,并没有进行计算
print('------------')
# 对A分组
a = df.groupby('A').mean() # 按A列分组后并对C跟D列进行求平均
print(a)
print('------------')
# 先对A分组,再对B分组,然后计算其平均值
b = df.groupby(['A','B']).mean()
print(b)
# 对A分组,然后对D列求平均值
print('------------')
c = df.groupby(['A'])['D'].mean()
print(c)
print('------------')
# 默认axis=0,按行来分组输出结果:
import pandas as pd
# 分组,可迭代对象
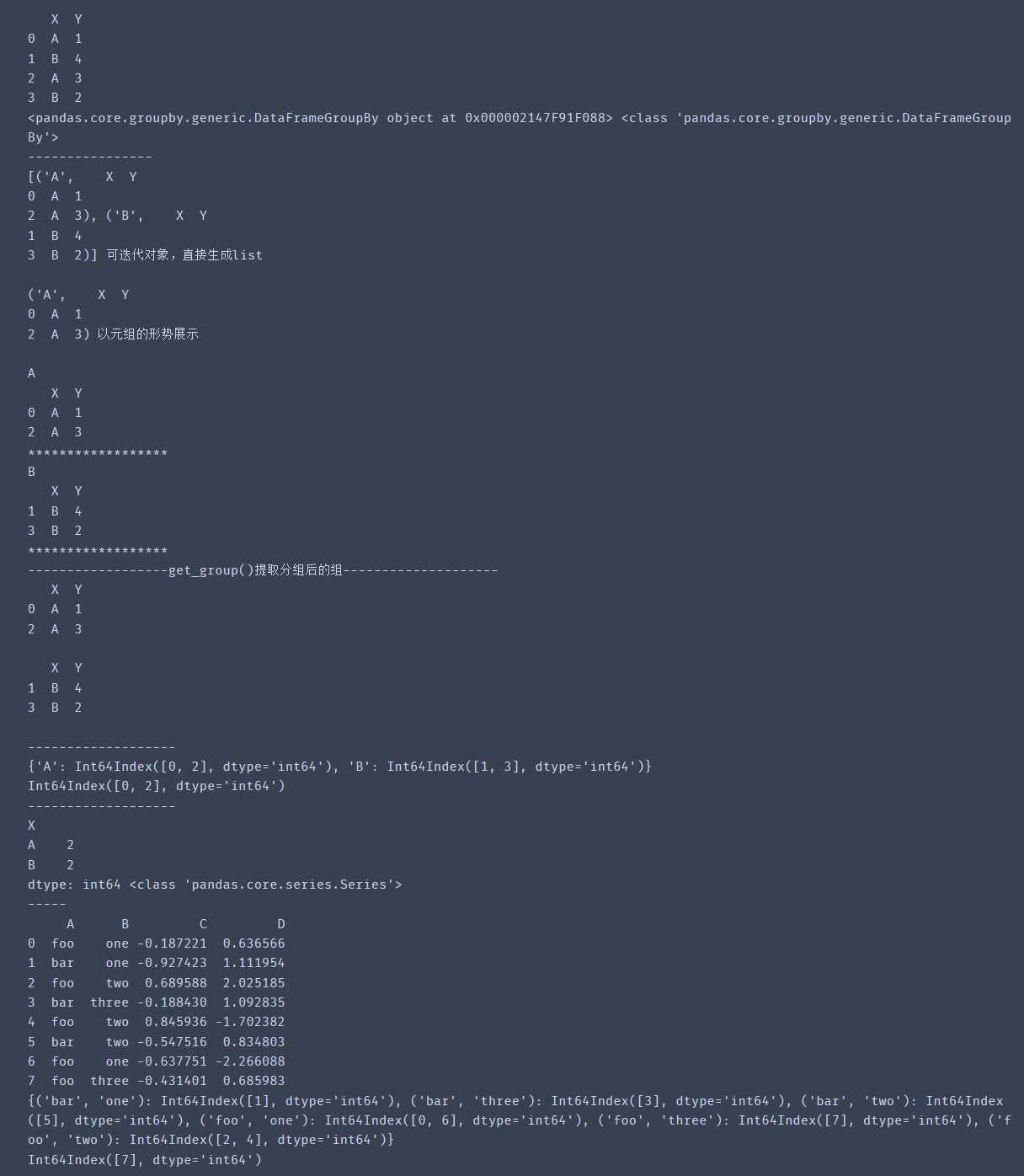
df = pd.DataFrame({'X':['A','B','A','B'],
'Y':[1,4,3,2]
})
print(df)
print(df.groupby('X'),type(df.groupby('X')))
print('----------------')
print(list(df.groupby('X')),'可迭代对象,直接生成list \n')
print(list(df.groupby('X'))[0],'以元组的形势展示 \n')
for n,g in df.groupby('X'):
print(n) # 组名
print(g) # 组后跟的DataFrame
print('******************')
print('------------------get_group()提取分组后的组--------------------')
print(df.groupby(['X']).get_group('A'),'\n')
print(df.groupby(['X']).get_group('B'),'\n')
print('-------------------')
# groups:将分组后的groups转为dict,可以字典索引方法来查看groups里的元素
grouped = df.groupby(['X'])
print(grouped.groups)
print(grouped.groups['A']) # 也可写:df.groupby('X').groups['A']
print('-------------------')
# size():查看分组后的长度
sz = grouped.size()
print(sz,type(sz))
print('-----')
# 按照两个列进行分组
df = pd.DataFrame({'A' : ['foo', 'bar', 'foo', 'bar','foo', 'bar', 'foo', 'foo'],
'B' : ['one', 'one', 'two', 'three', 'two', 'two', 'one', 'three'],
'C' : np.random.randn(8),
'D' : np.random.randn(8)})
grouped = df.groupby(['A','B']).groups
print(df)
print(grouped)
print(grouped[('foo', 'three')])输出结果:
# 按照轴类型进行分组
import pandas as pd
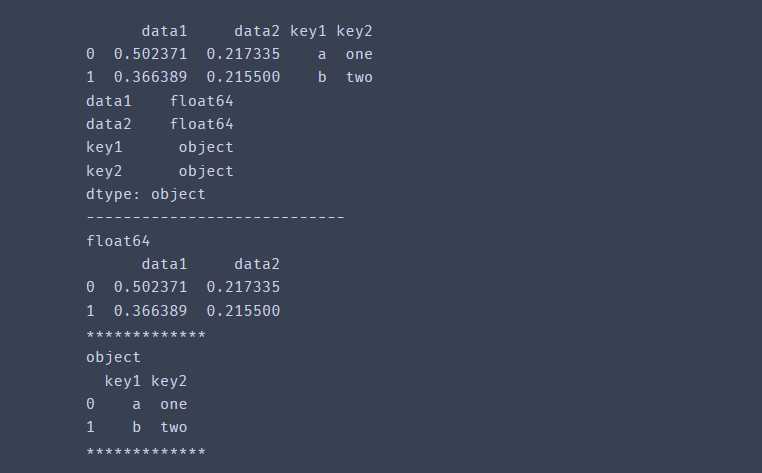
df = pd.DataFrame({'data1':np.random.rand(2),
'data2':np.random.rand(2),
'key1':['a','b'],
'key2':['one','two'],
})
print(df)
print(df.dtypes)
print('----------------------------')
for n,p in df.groupby(df.dtypes,axis=1):
print(n)
print(p)
print('*************')输出结果:
import pandas as pd
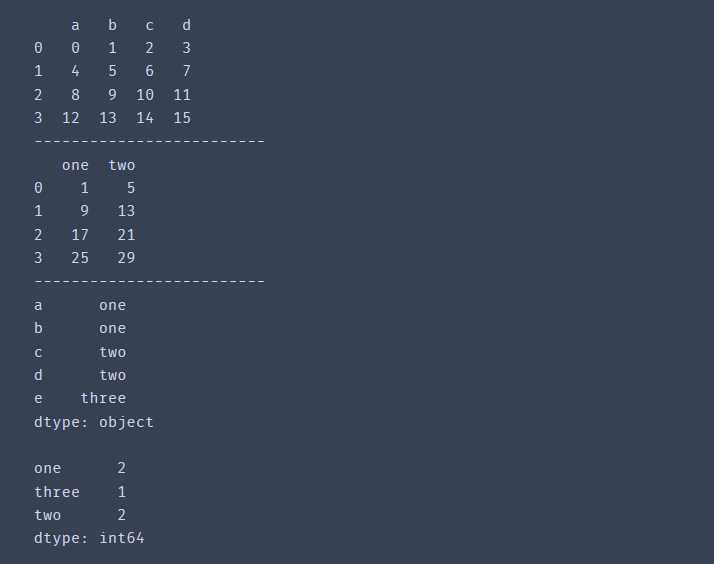
df = pd.DataFrame(np.arange(16).reshape(4,4), columns = ['a','b','c','d'])
print(df)
print('-------------------------')
# mapping中,a、b列对应的为one,c、d列对应的为two,以字典来分组
mapping = {'a':'one','b':'one','c':'two','d':'two','e':'three'}
by_column = df.groupby(mapping, axis = 1)
print(by_column.sum())
print('-------------------------')
# s中,index中a、b对应的为one,c、d对应的为two,以Series来分组
s = pd.Series(mapping)
print(s,'\n')
print(s.groupby(s).count())输出结果:
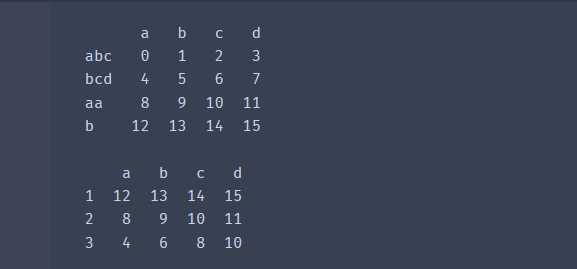
import pandas as pd
df = pd.DataFrame(np.arange(16).reshape(4,4),
columns = ['a', 'b', 'c', 'd'],
index = ['abc', 'bcd', 'aa', 'b']
)
print(df,'\n')
# 按照字母长度分组,分组后求和
print(df.groupby(len).sum())输出结果:
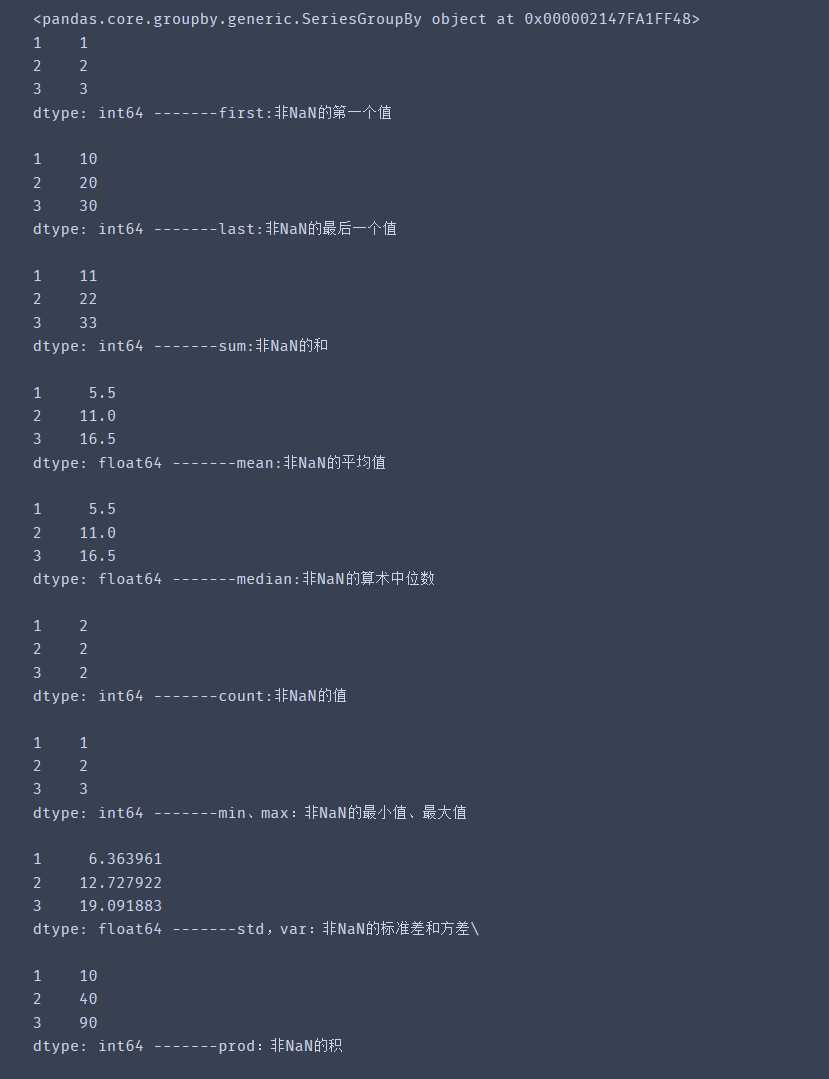
import pandas as pd
s = pd.Series([1,2,3,10,20,30], index = [1,2,3,1,2,3])
grouped = s.groupby(level=0) # groupby(level=0) 将同一个index的分为一组
print(grouped)
print(grouped.first(),'-------first:非NaN的第一个值 \n')
print(grouped.last(),'-------last:非NaN的最后一个值 \n')
print(grouped.sum(),'-------sum:非NaN的和 \n')
print(grouped.mean(),'-------mean:非NaN的平均值 \n')
print(grouped.median(),'-------median:非NaN的算术中位数 \n')
print(grouped.count(),'-------count:非NaN的值 \n')
print(grouped.min(),'-------min、max:非NaN的最小值、最大值 \n')
print(grouped.std(),'-------std,var:非NaN的标准差和方差\ \n')
print(grouped.prod(),'-------prod:非NaN的积\n')输出结果:
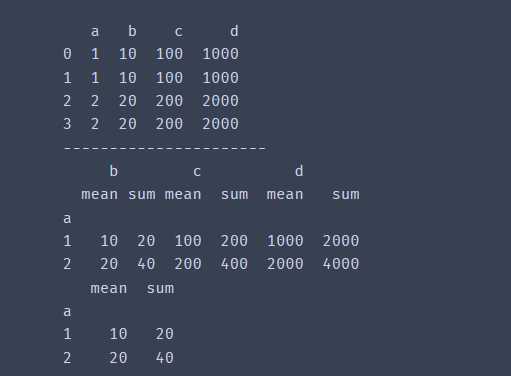
import pandas as pd
df = pd.DataFrame({'a':[1,1,2,2],
'b':[10,10,20,20],
'c':[100,100,200,200],
'd':[1000,1000,2000,2000]
})
print(df)
print('----------------------')
print(df.groupby('a').agg(['mean',np.sum])) # 即可以求平均数,也可以求和
print(df.groupby('a')['b'].agg({"mean","sum"}))输出结果:
标签:方法 可迭代对象 level dict media last ref com 展示
原文地址:https://www.cnblogs.com/OliverQin/p/12341696.html