标签:unsigned input clearing 单元 细节 这不 inline 字段 nis
asmlinkage __visible void __sched schedule(void) { struct task_struct *tsk = current; sched_submit_work(tsk); do { preempt_disable(); __schedule(false); sched_preempt_enable_no_resched(); } while (need_resched()); }
static void __sched notrace __schedule(bool preempt) { struct task_struct *prev, *next; unsigned long *switch_count; struct rq_flags rf; struct rq *rq; int cpu; cpu = smp_processor_id(); rq = cpu_rq(cpu); prev = rq->curr; ......
}
1. 在当前的 CPU 上,我们取出任务队列 rq。task_struct *prev 指向这个 CPU 的任务队列上面正在运行的那个进程 curr。
为啥是 prev?因为一旦将来它被切换下来,那它就成了前任了
next = pick_next_task(rq, prev, &rf);
clear_tsk_need_resched(prev);
clear_preempt_need_resched();
2. 第二步,获取下一个任务,task_struct *next 指向下一个任务,这就是继任
pick_next_task 的实现如下:
static inline struct task_struct * pick_next_task(struct rq *rq, struct task_struct *prev, struct rq_flags *rf) { const struct sched_class *class; struct task_struct *p; /* * Optimization: we know that if all tasks are in the fair class we can call that function directly, but only if the @prev task wasn‘t of a higher scheduling class, because otherwise those loose the opportunity to pull in more work from other CPUs. */ if (likely((prev->sched_class == &idle_sched_class || prev->sched_class == &fair_sched_class) && rq->nr_running == rq->cfs.h_nr_running)) { p = fair_sched_class.pick_next_task(rq, prev, rf); if (unlikely(p == RETRY_TASK)) goto again; /* Assumes fair_sched_class->next == idle_sched_class */ if (unlikely(!p)) p = idle_sched_class.pick_next_task(rq, prev, rf); return p; } again: for_each_class(class) { p = class->pick_next_task(rq, prev, rf); if (p) { if (unlikely(p == RETRY_TASK)) goto again; return p; } } }
根据 fair_sched_class 的定义,它调用的是 pick_next_task_fair,代码如下
static struct task_struct * pick_next_task_fair(struct rq *rq, struct task_struct *prev, struct rq_flags *rf) { struct cfs_rq *cfs_rq = &rq->cfs; struct sched_entity *se; struct task_struct *p; int new_tasks;
对于 CFS 调度类,取出相应的队列 cfs_rq,这就是我们上一节讲的那棵红黑树
struct sched_entity *curr = cfs_rq->curr; if (curr) { if (curr->on_rq) update_curr(cfs_rq); else curr = NULL; ...... } se = pick_next_entity(cfs_rq, curr);
取出当前正在运行的任务 curr,如果依然是可运行的状态,也即处于进程就绪状态,则调用 update_curr 更新 vruntime。
3.pick_next_entity 从红黑树里面,取最左边的一个节点
p = task_of(se); if (prev != p) { struct sched_entity *pse = &prev->se; ...... put_prev_entity(cfs_rq, pse); set_next_entity(cfs_rq, se); } return p
task_of 得到下一个调度实体对应的 task_struct,如果发现继任和前任不一样,这就说明有一个更需要运行的进程了,就需要更新红黑树了。
前面前任的 vruntime 更新过了,put_prev_entity 放回红黑树,会找到相应的位置,然后 set_next_entity 将继任者设为当前任务。
4. 当选出的继任者和前任不同,就要进行上下文切换,继任者进程正式进入运行
if (likely(prev != next)) { rq->nr_switches++; rq->curr = next; ++*switch_count; ...... rq = context_switch(rq, prev, next, &rf);
上下文切换主要干两件事情:
一是切换进程空间,也即虚拟内存;
二是切换寄存器和 CPU 上下文
进程的上下文信息包括, 指向可执行文件的指针, 栈, 内存(数据段和堆), 进程状态, 优先级, 程序I/O的状态, 授予权限, 调度信息, 审计信息, 有关资源的信息(文件描述符和读/写指针), 关事件和信号的信息, 寄存器组(栈指针, 指令计数器)等等, 诸如此类.
处理器总处于以下三种状态之一
上下文切换可以认为是内核(操作系统的核心)在 CPU 上对于进程(包括线程)进行以下的活动:
linux中进程调度时, 内核在选择新进程之后进行抢占时, 通过context_switch完成进程上下文切换.
注意
进程调度与抢占的区别
进程调度不一定发生抢占, 但是抢占时却一定发生了调度
在进程发生调度时, 只有当前内核发生当前进程因为主动或者被动需要放弃CPU时, 内核才会选择一个与当前活动进程不同的进程来抢占CPU
context_switch其实是一个分配器, 他会调用所需的特定体系结构的方法
context_switch函数建立next进程的地址空间。进程描述符的active_mm字段指向进程所使用的内存描述符,而mm字段指向进程所拥有的内存描述符。对于一般的进程,这两个字段有相同的地址,但是,内核线程没有它自己的地址空间而且它的 mm字段总是被设置为 NULL
context_switch( )函数保证:如果next是一个内核线程, 它使用prev所使用的地址空间
由于不同架构下地址映射的机制有所区别, 而寄存器等信息弊病也是依赖于架构的, 因此switch_mm和switch_to两个函数均是体系结构相关的
/* * context_switch - switch to the new MM and the new thread‘s register state. */ static __always_inline struct rq * context_switch(struct rq *rq, struct task_struct *prev, struct task_struct *next) { struct mm_struct *mm, *oldmm; /* 完成进程切换的准备工作 */ prepare_task_switch(rq, prev, next); mm = next->mm; oldmm = prev->active_mm; /* * For paravirt, this is coupled with an exit in switch_to to * combine the page table reload and the switch backend into * one hypercall. */ arch_start_context_switch(prev); /* 如果next是内核线程,则线程使用prev所使用的地址空间 * schedule( )函数把该线程设置为懒惰TLB模式 * 内核线程并不拥有自己的页表集(task_struct->mm = NULL) * 它使用一个普通进程的页表集 * 不过,没有必要使一个用户态线性地址对应的TLB表项无效 * 因为内核线程不访问用户态地址空间。 */ if (!mm) /* 内核线程无虚拟地址空间, mm = NULL*/ { /* 内核线程的active_mm为上一个进程的mm * 注意此时如果prev也是内核线程, * 则oldmm为NULL, 即next->active_mm也为NULL */ next->active_mm = oldmm; /* 增加mm的引用计数 */ atomic_inc(&oldmm->mm_count); /* 通知底层体系结构不需要切换虚拟地址空间的用户部分 * 这种加速上下文切换的技术称为惰性TBL */ enter_lazy_tlb(oldmm, next); } else /* 不是内核线程, 则需要切切换虚拟地址空间 */ switch_mm(oldmm, mm, next); /* 如果prev是内核线程或正在退出的进程 * 就重新设置prev->active_mm * 然后把指向prev内存描述符的指针保存到运行队列的prev_mm字段中 */ if (!prev->mm) { /* 将prev的active_mm赋值和为空 */ prev->active_mm = NULL; /* 更新运行队列的prev_mm成员 */ rq->prev_mm = oldmm; } /* * Since the runqueue lock will be released by the next * task (which is an invalid locking op but in the case * of the scheduler it‘s an obvious special-case), so we * do an early lockdep release here: */ lockdep_unpin_lock(&rq->lock); spin_release(&rq->lock.dep_map, 1, _THIS_IP_); /* Here we just switch the register state and the stack. * 切换进程的执行环境, 包括堆栈和寄存器 * 同时返回上一个执行的程序 * 相当于prev = witch_to(prev, next) */ switch_to(prev, next, prev); /* switch_to之后的代码只有在 * 当前进程再次被选择运行(恢复执行)时才会运行 * 而此时当前进程恢复执行时的上一个进程可能跟参数传入时的prev不同 * 甚至可能是系统中任意一个随机的进程 * 因此switch_to通过第三个参数将此进程返回 */ /* 路障同步, 一般用编译器指令实现 * 确保了switch_to和finish_task_switch的执行顺序 * 不会因为任何可能的优化而改变 */ barrier(); /* 进程切换之后的处理工作 */ return finish_task_switch(prev); }
在进程切换之前, 首先执行调用每个体系结构都必须定义的prepare_task_switch挂钩, 这使得内核执行特定于体系结构的代码, 为切换做事先准备. 大多数支持的体系结构都不需要该选项
struct mm_struct *mm, *oldmm; prepare_task_switch(rq, prev, next); /* 完成进程切换的准备工作 */
/** * prepare_task_switch - prepare to switch tasks * @rq: the runqueue preparing to switch * @prev: the current task that is being switched out * @next: the task we are going to switch to. * * This is called with the rq lock held and interrupts off. It must * be paired with a subsequent finish_task_switch after the context * switch. * * prepare_task_switch sets up locking and calls architecture specific * hooks. */ static inline void prepare_task_switch(struct rq *rq, struct task_struct *prev, struct task_struct *next) { sched_info_switch(rq, prev, next); perf_event_task_sched_out(prev, next); fire_sched_out_preempt_notifiers(prev, next); prepare_lock_switch(rq, next); prepare_arch_switch(next); }
由于用户空间进程的寄存器内容在进入核心态时保存在内核栈中, 在上下文切换期间无需显式操作.
而因为每个进程首先都是从核心态开始执行(在调度期间控制权传递给新进程), 在返回用户空间时, 会使用内核栈上保存的值自动恢复寄存器数据.
/* 如果next是内核线程,则线程使用prev所使用的地址空间 * schedule( )函数把该线程设置为懒惰TLB模式 * 内核线程并不拥有自己的页表集(task_struct->mm = NULL) * 它使用一个普通进程的页表集 * 不过,没有必要使一个用户态线性地址对应的TLB表项无效 * 因为内核线程不访问用户态地址空间。 */ if (!mm) /* 内核线程无虚拟地址空间, mm = NULL*/ { /* 内核线程的active_mm为上一个进程的mm * 注意此时如果prev也是内核线程, * 则oldmm为NULL, 即next->active_mm也为NULL */ next->active_mm = oldmm; /* 增加mm的引用计数 */ atomic_inc(&oldmm->mm_count); /* 通知底层体系结构不需要切换虚拟地址空间的用户部分 * 这种加速上下文切换的技术称为惰性TBL */ enter_lazy_tlb(oldmm, next); } else /* 不是内核线程, 则需要切切换虚拟地址空间 */ switch_mm(oldmm, mm, next);
启动enter_lazy_tlb通知底层体系结构不需要切换虚拟地址空间的用户空间部分, 这种加速上下文切换的技术称之为惰性TLB
最后用switch_to完成了进程的切换, 该函数切换了寄存器状态和栈, 新进程在该调用后开始执行, 而switch_to之后的代码只有在当前进程下一次被选择运行时才会执行
执行环境的切换是在switch_to()中完成的, switch_to完成最终的进程切换,它保存原进程的所有寄存器信息,恢复新进程的所有寄存器信息,并执行新的进程
该函数往往通过宏来实现, 其原型声明如下
/* * Saving eflags is important. It switches not only IOPL between tasks, * it also protects other tasks from NT leaking through sysenter etc. */ #define switch_to(prev, next, last)
内核在switch_to中执行如下操作
调度过程可能选择了一个新的进程, 而清理工作则是针对此前的活动进程, 请注意, 这不是发起上下文切换的那个进程, 而是系统中随机的某个其他进程, 内核必须想办法使得进程能够与context_switch例程通信, 这就可以通过switch_to宏实现. 因此switch_to函数通过3个参数提供2个变量.
在新进程被选中时, 底层的进程切换冽程必须将此前执行的进程提供给context_switch, 由于控制流会回到陔函数的中间, 这无法用普通的函数返回值来做到, 因此提供了3个参数的宏
我们考虑这个样一个例子, 假定多个进程A, B, C…在系统上运行, 在某个时间点, 内核决定从进程A切换到进程B, 此时prev = A, next = B, 即执行了switch_to(A, B), 而后当被抢占的进程A再次被选择执行的时候, 系统可能进行了多次进程切换/抢占(至少会经历一次即再次从B到A),假设A再次被选择执行时时当前活动进程是C, 即此时prev = C. next = A.
在每个switch_to被调用的时候, prev和next指针位于各个进程的内核栈中, prev指向了当前运行的进程, 而next指向了将要运行的下一个进程, 那么为了执行从prev到next的切换, switcth_to使用前两个参数prev和next就够了.
在进程A被选中再次执行的时候, 会出现一个问题, 此时控制权即将回到A, switch_to函数返回, 内核开始执行switch_to之后的点, 此时内核栈准确的恢复到切换之前的状态, 即进程A上次被切换出去时的状态, prev = A, next = B. 此时, 内核无法知道实际上在进程A之前运行的是进程C.
因此, 在新进程被选中执行时, 内核恢复到进程被切换出去的点继续执行, 此时内核只知道谁之前将新进程抢占了, 但是却不知道新进程再次执行是抢占了谁, 因此底层的进程切换机制必须将此前执行的进程(即新进程抢占的那个进程)提供给context_switch. 由于控制流会回到函数的该中间, 因此无法通过普通函数的返回值来完成. 因此使用了一个3个参数, 但是逻辑效果是相同的, 仿佛是switch_to是带有两个参数的函数, 而且返回了一个指向此前运行的进程的指针.
switch_to(prev, next, last);
即
prev = last = switch_to(prev, next);
其中返回的prev值并不是做参数的prev值, 而是prev被再次调度的时候抢占掉的那个进程last.
在上个例子中, 进程A提供给switch_to的参数是prev = A, next = B, 然后控制权从A交给了B, 但是恢复执行的时候是通过prev = C, next = A完成了再次调度, 而后内核恢复了进程A被切换之前的内核栈信息, 即prev = A, next = B. 内核为了通知调度机制A抢占了C的处理器, 就通过last参数传递回来, prev = last = C.
内核实现该行为特性的方式依赖于底层的体系结构, 但内核显然可以通过考虑两个进程的内核栈来重建所需要的信息
switch_mm()进行用户空间的切换, 更确切地说, 是切换地址转换表(pgd), 由于pgd包括内核虚拟地址空间和用户虚拟地址空间地址映射, linux内核把进程的整个虚拟地址空间分成两个部分, 一部分是内核虚拟地址空间, 另外一部分是内核虚拟地址空间, 各个进程的虚拟地址空间各不相同, 但是却共用了同样的内核地址空间, 这样在进程切换的时候, 就只需要切换虚拟地址空间的用户空间部分.
每个进程都有其自身的页目录表pgd
进程本身尚未切换, 而存储管理机制的页目录指针cr3却已经切换了,这样不会造成问题吗?不会的,因为这个时候CPU在系统空间运行,而所有进程的页目录表中与系统空间对应的目录项都指向相同的页表,所以,不管切换到哪一个进程的页目录表都一样,受影响的只是用户空间,系统空间的映射则永远不变
我们下面来分析一下子, x86_32位下的switch_to函数, 其定义在arch/x86/include/asm/switch_to.h, line 27
先对flags寄存器和ebp压入旧进程内核栈,并将确定旧进程恢复执行的下一跳地址,并将旧进程ip,esp保存到task_struct->thread_info中,这样旧进程保存完毕;然后用新进程的thread_info->esp恢复新进程的内核堆栈,用thread->info的ip恢复新进程地址执行。
关键点:内核寄存器[eflags、ebp保存到内核栈;内核栈esp地址、ip地址保存到thread_info中,task_struct在生命期中始终是全局的,所以肯定能根据该结构恢复出其所有执行场景来]
/* * Saving eflags is important. It switches not only IOPL between tasks, * it also protects other tasks from NT leaking through sysenter etc. */ #define switch_to(prev, next, last) do { /* * Context-switching clobbers all registers, so we clobber * them explicitly, via unused output variables. * (EAX and EBP is not listed because EBP is saved/restored * explicitly for wchan access and EAX is the return value of * __switch_to()) */ unsigned long ebx, ecx, edx, esi, edi; asm volatile("pushfl\n\t" /* save flags 保存就的ebp、和flags寄存器到旧进程的内核栈中*/ "pushl %%ebp\n\t" /* save EBP */ "movl %%esp,%[prev_sp]\n\t" /* save ESP 将旧进程esp保存到thread_info结构中 */ "movl %[next_sp],%%esp\n\t" /* restore ESP 用新进程esp填写esp寄存器,此时内核栈已切换 */ "movl $1f,%[prev_ip]\n\t" /* save EIP 将该进程恢复执行时的下条地址保存到旧进程的thread中*/ "pushl %[next_ip]\n\t" /* restore EIP 将新进程的ip值压入到新进程的内核栈中 */ __switch_canary "jmp __switch_to\n" /* regparm call */ "1:\t" "popl %%ebp\n\t" /* restore EBP 该进程执行,恢复ebp寄存器*/ "popfl\n" /* restore flags 恢复flags寄存器*/ /* output parameters */ : [prev_sp] "=m" (prev->thread.sp), [prev_ip] "=m" (prev->thread.ip), "=a" (last), /* clobbered output registers: */ "=b" (ebx), "=c" (ecx), "=d" (edx), "=S" (esi), "=D" (edi) __switch_canary_oparam /* input parameters: */ : [next_sp] "m" (next->thread.sp), [next_ip] "m" (next->thread.ip), /* regparm parameters for __switch_to(): */ [prev] "a" (prev), [next] "d" (next) __switch_canary_iparam : /* reloaded segment registers */ "memory"); } while (0)
switch_to完成了进程的切换, 新进程在该调用后开始执行, 而switch_to之后的代码只有在当前进程下一次被选择运行时才会执行.
/* switch_to之后的代码只有在 * 当前进程再次被选择运行(恢复执行)时才会运行 * 而此时当前进程恢复执行时的上一个进程可能跟参数传入时的prev不同 * 甚至可能是系统中任意一个随机的进程 * 因此switch_to通过第三个参数将此进程返回 */ /* 路障同步, 一般用编译器指令实现 * 确保了switch_to和finish_task_switch的执行顺序 * 不会因为任何可能的优化而改变 */ barrier(); /* 进程切换之后的处理工作 */ return finish_task_switch(prev);
而为了程序编译后指令的执行顺序不会因为编译器的优化而改变, 因此内核提供了路障同步barrier来保证程序的执行顺序.
barrier往往通过编译器指令来实现, 内核中多处都实现了barrier, 形式如下
// http://lxr.free-electrons.com/source/include/linux/compiler-gcc.h?v=4.6#L15 /* Copied from linux/compiler-gcc.h since we can‘t include it directly * 采用内敛汇编实现 * __asm__用于指示编译器在此插入汇编语句 * __volatile__用于告诉编译器,严禁将此处的汇编语句与其它的语句重组合优化。 * 即:原原本本按原来的样子处理这这里的汇编。 * memory强制gcc编译器假设RAM所有内存单元均被汇编指令修改,这样cpu中的registers和cache中已缓存的内存单元中的数据将作废。cpu将不得不在需要的时候重新读取内存中的数据。这就阻止了cpu又将registers,cache中的数据用于去优化指令,而避免去访问内存。 * "":::表示这是个空指令。barrier()不用在此插入一条串行化汇编指令。在后文将讨论什么叫串行化指令。 */ #define barrier() __asm__ __volatile__("": : :"memory")
finish_task_switch完成一些清理工作, 使得能够正确的释放锁, 但我们不会详细讨论这些. 他会向各个体系结构提供了另一个挂钩上下切换过程的可能性, 当然这只在少数计算机上需要.
注:A进程切换到B, A被切换, 而当A再次被选择执行, C再次切换到A,此时A执行,但是系统为了告知调度器A再次执行前的进程是C, 通过switch_to的last参数返回的prev指向C,在A调度时候需要把调用A的进程的信息清除掉
由于从C切换到A时候, A内核栈中保存的实际上是A切换出时的状态信息, 即prev=A, next=B,但是在A执行时, 其位于context_switch上下文中, 该函数的last参数返回的prev应该是切换到A的进程C, A负责对C进程信息进行切换后处理,比如,如果切换到A后,A发现C进程已经处于TASK_DEAD状态,则将释放C进程的TASK_STRUCT结构
1 /** 2 * finish_task_switch - clean up after a task-switch 3 * @prev: the thread we just switched away from. 4 * 5 * finish_task_switch must be called after the context switch, paired 6 * with a prepare_task_switch call before the context switch. 7 * finish_task_switch will reconcile locking set up by prepare_task_switch, 8 * and do any other architecture-specific cleanup actions. 9 * 10 * Note that we may have delayed dropping an mm in context_switch(). If 11 * so, we finish that here outside of the runqueue lock. (Doing it 12 * with the lock held can cause deadlocks; see schedule() for 13 * details.) 14 * 15 * The context switch have flipped the stack from under us and restored the 16 * local variables which were saved when this task called schedule() in the 17 * past. prev == current is still correct but we need to recalculate this_rq 18 * because prev may have moved to another CPU. 19 */ 20 static struct rq *finish_task_switch(struct task_struct *prev) 21 __releases(rq->lock) 22 { 23 struct rq *rq = this_rq(); 24 struct mm_struct *mm = rq->prev_mm; 25 long prev_state; 26 27 /* 28 * The previous task will have left us with a preempt_count of 2 29 * because it left us after: 30 * 31 * schedule() 32 * preempt_disable(); // 1 33 * __schedule() 34 * raw_spin_lock_irq(&rq->lock) // 2 35 * 36 * Also, see FORK_PREEMPT_COUNT. 37 */ 38 if (WARN_ONCE(preempt_count() != 2*PREEMPT_DISABLE_OFFSET, 39 "corrupted preempt_count: %s/%d/0x%x\n", 40 current->comm, current->pid, preempt_count())) 41 preempt_count_set(FORK_PREEMPT_COUNT); 42 43 rq->prev_mm = NULL; 44 45 /* 46 * A task struct has one reference for the use as "current". 47 * If a task dies, then it sets TASK_DEAD in tsk->state and calls 48 * schedule one last time. The schedule call will never return, and 49 * the scheduled task must drop that reference. 50 * 51 * We must observe prev->state before clearing prev->on_cpu (in 52 * finish_lock_switch), otherwise a concurrent wakeup can get prev 53 * running on another CPU and we could rave with its RUNNING -> DEAD 54 * transition, resulting in a double drop. 55 */ 56 prev_state = prev->state; 57 vtime_task_switch(prev); 58 perf_event_task_sched_in(prev, current); 59 finish_lock_switch(rq, prev); 60 finish_arch_post_lock_switch(); 61 62 fire_sched_in_preempt_notifiers(current); 63 if (mm) 64 mmdrop(mm); 65 if (unlikely(prev_state == TASK_DEAD)) /* 如果上一个进程已经终止,释放其task_struct 结构 */ 66 { 67 if (prev->sched_class->task_dead) 68 prev->sched_class->task_dead(prev); 69 70 /* 71 * Remove function-return probe instances associated with this 72 * task and put them back on the free list. 73 */ 74 kprobe_flush_task(prev); 75 put_task_struct(prev); 76 } 77 78 tick_nohz_task_switch(); 79 return rq; 80 }
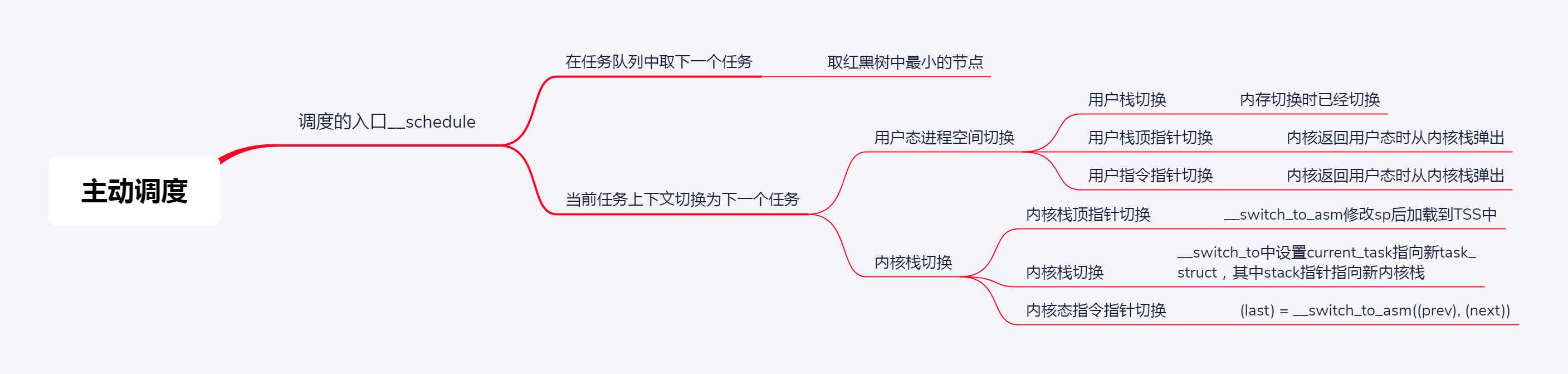
调度, 切换运行进程, 有两种方式
- 进程调用 sleep 或等待 I/O, 主动让出 CPU
- 进程运行一段时间, 被动让出 CPU
主动让出 CPU 的方式, 调用 schedule(), schedule() 调用 __schedule()
- __schedule() 取出 rq; 取出当前运行进程的 task_struct
- 调用 pick_next_task 取下一个进程
- 依次调用调度类(优化: 大部分都是普通进程), 因此大多数情况调用 fair_sched_class.pick_next_task[_fair]
- pick_next_task_fair 先取出 cfs_rq 队列, 取出当前运行进程调度实体, 更新 vruntime
- pick_next_entity 取最左节点, 并得到 task_struct, 若与当前进程不一样, 则更新红黑树 cfs_rq
- 进程上下文切换: 切换进程内存空间, 切换寄存器和 CPU 上下文(运行 context_switch)
- context_switch() -> switch_to() -> __switch_to_asm(切换[内核]栈顶指针) -> __switch_to()
- __switch_to() 取出 Per CPU 的 tss(任务状态段) 结构体
-
> x86 提供以硬件方式切换进程的模式, 为每个进程在内存中维护一个 tss, tss 有所有寄存器, 同时
TR(任务寄存器)指向某个 tss, 更改 TR 会触发换出 tss(旧进程)和换入 tss(新进程), 但切换进程没必要换所有寄存器
- 因此 Linux 中每个 CPU 关联一个 tss, 同时 TR 不变, Linux 中参与进程切换主要是栈顶寄存器
- task_struct 的 thread 结构体保留切换时需要修改的寄存器, 切换时将新进程 thread 写入 CPU tss 中
- 具体各类指针保存位置和时刻
- 用户栈, 切换进程内存空间时切换
- 用户栈顶指针, 内核栈 pt_regs 中弹出
- 用户指令指针, 从内核栈 pt_regs 中弹出
- 内核栈, 由切换的 task_struct 中的 stack 指针指向
- 内核栈顶指针, __switch_to_asm 函数切换(保存在 thread 中)
- 内核指令指针寄存器: 进程调度最终都会调用 __schedule, 因此在让出(从当前进程)和取得(从其他进程) CPU 时, 该指针都指向同一个代码位置.
参考:《趣谈Linux操作系统》调度(中)
https://cloud.tencent.com/developer/article/1368753
标签:unsigned input clearing 单元 细节 这不 inline 字段 nis
原文地址:https://www.cnblogs.com/mysky007/p/12342599.html