标签:位置 事件 str font 离婚 enc bio style 环境
一、摘要
为了方便法官更好地了解案情,采用事件抽取技术更快地捕捉案情的“焦点”。本研究提出了一种定义焦点事件的机制,并且能够解决多个事件共享同一论元(arguement)或触发词的问题。
二、在法律背景下应用事件抽取技术的难点
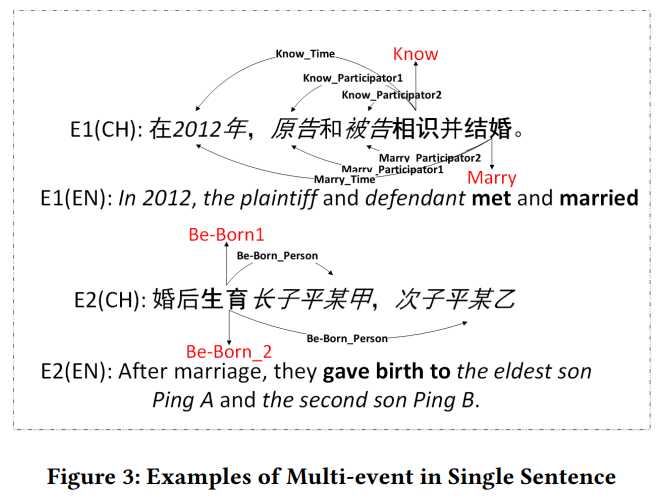
三、方法
主要以离婚案例为例。
方法主要分为三部分:核心事件类型定义、数据标注、事件抽取。
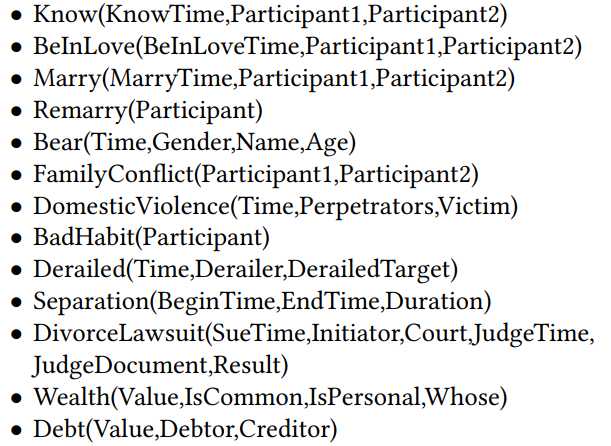
定义核心事件类型
主要定义了13种事件类型,40种事件参数类型。
数据标注
采用BIO模式进行数据标注。首先对一小部分数据进行预标注,之后在http://brat.nlplab.org/about.html环境中进行标注。
事件抽取
下图展示了事件抽取的步骤。
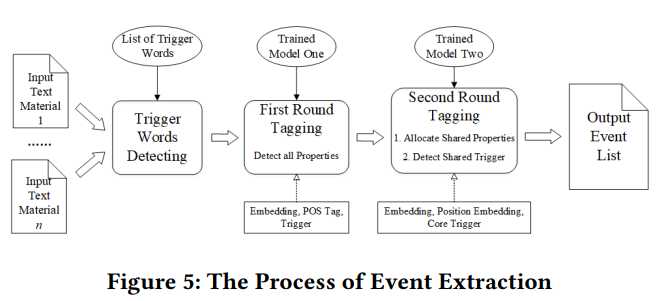
下面详细解释一下事件抽取的过程。
触发词词典:尽可能多地收集事件触发词,并形成触发词词典。
过滤和分类触发词:首先使用LTP对句子进行分词,之后对每个单独的句子,通过触发词词典来确定其中是否有事件,并且确定触发词。
First Labelling:如上所述,对离婚事件定义了13个事件触发词和40个事件参数。这一步将原来的40个label映射到12个transition label,以减少label种类数和某种label的总数。下面是定义的transition label以及first label操作的架构。

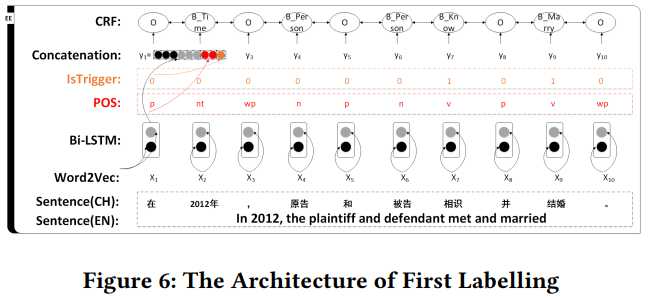
Second labelling:这一步与上一步结合,解决了事件参数和触发词共享问题:在上一步中先打上tansition label,这一步中再为其打上前文所述的40个label中的一个,标定单词的具体类型。
四、实验
数据预处理
数据规模为3100条诉讼材料。
评价指标
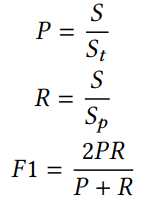
其中St为所有触发词和论元的总和,S为预测正确的触发词和论元的总和,Sp为预测为触发词和论元的词语总和。
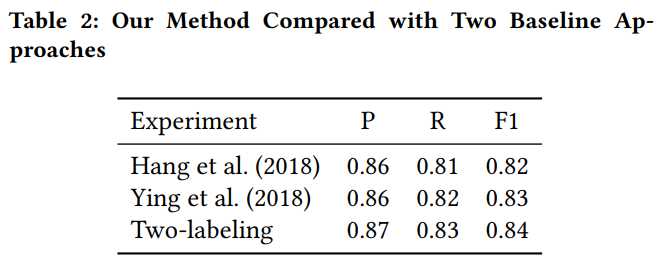
实验结果
五、存在的问题
论文阅读 | Ubicomp19 Apply Event Extraction Techniques to the Judicial Field
标签:位置 事件 str font 离婚 enc bio style 环境
原文地址:https://www.cnblogs.com/otaku-47/p/12343624.html