标签:var 只读 添加 code imp pfile check create 完成
在数据库集群架构中,让主库负责处理事务性查询,而从库只负责处理select查询,让两者分工明确达到提高数据库整体读写性能。当然,主数据库另外一个功能就是负责将事务性查询导致的数据变更同步到从库中,也就是写操作。
读写分离适用于读远比写的场景,如果有一台服务器,当select很多时,update和delete会被这些select访问中的数据堵塞,等待select结束,并发性能并不高,而主从只负责各自的写和读,极大程度的缓解X锁和S锁争用;
假如我们有1主3从,不考虑上述1中提到的从库单方面设置,假设现在1分钟内有10条写入,150条读取。那么,1主3从相当于共计40条写入,而读取总数没变,因此平均下来每台服务器承担了10条写入和50条读取(主库不承担读取操作)。因此,虽然写入没变,但是读取大大分摊了,提高了系统性能。另外,当读取被分摊后,又间接提高了写入的性能。所以,总体性能提高了,说白了就是拿机器和带宽换性能;
Mycat是一个开源的分布式数据库系统,但是因为数据库一般都有自己的数据库引擎,而Mycat并没有属于自己的独有数据库引擎,所有严格意义上说并不能算是一个完整的数据库系统,只能说是一个在应用和数据库之间起桥梁作用的中间件。
在Mycat中间件出现之前,MySQL主从复制集群,如果要实现读写分离,一般是在程序段实现,这样就带来了一个问题,即数据段和程序的耦合度太高,如果数据库的地址发生了改变,那么我的程序也要进行相应的修改,如果数据库不小心挂掉了,则同时也意味着程序的不可用,而对于很多应用来说,并不能接受;
引入Mycat中间件能很好地对程序和数据库进行解耦,这样,程序只需关注数据库中间件的地址,而无需知晓底层数据库是如何提供服务的,大量的通用数据聚合、事务、数据源切换等工作都由中间件来处理;
Mycat中间件的原理是对数据进行分片处理,从原有的一个库,被切分为多个分片数据库,所有的分片数据库集群构成完成的数据库存储,有点类似磁盘阵列中的RAID0.
CREATE TABLE `t_users` ( `user_id` varchar(64) NOT NULL COMMENT ‘注册用户ID‘, `user_email` varchar(64) NOT NULL COMMENT ‘注册用户邮箱‘, `user_password` varchar(64) NOT NULL COMMENT ‘注册用户密码‘, `user_nikename` varchar(64) NOT NULL COMMENT ‘注册用户昵称‘, `user_creatime` datetime NOT NULL COMMENT ‘注册时间‘, `user_status` tinyint(1) NOT NULL COMMENT ‘验证状态 1:已验证 0:未验证‘, `user_deleteflag` tinyint(1) NOT NULL COMMENT ‘删除标记 1:已删除 0:未删除‘, PRIMARY KEY (`user_id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
CREATE TABLE `t_message` ( `messages_id` varchar(64) NOT NULL COMMENT ‘微博ID‘, `user_id` varchar(64) NOT NULL COMMENT ‘发表用户‘, `messages_info` varchar(255) DEFAULT NULL COMMENT ‘微博内容‘, `messages_time` datetime DEFAULT NULL COMMENT ‘发布时间‘, `messages_commentnum` int(12) DEFAULT NULL COMMENT ‘评论次数‘, `message_deleteflag` tinyint(1) NOT NULL COMMENT ‘删除标记 1:已删除 0:未删除‘, `message_viewnum` int(12) DEFAULT NULL COMMENT ‘被浏览量‘, PRIMARY KEY (`messages_id`), KEY `user_id` (`user_id`), CONSTRAINT `t_message_ibfk_1` FOREIGN KEY (`user_id`) REFERENCES `t_users` (`user_id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
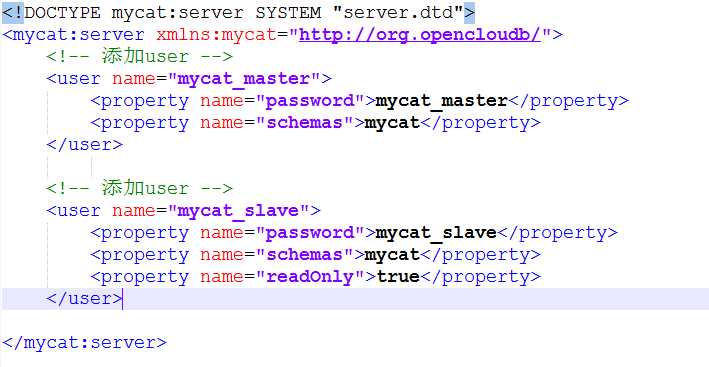
<!DOCTYPE mycat:server SYSTEM "server.dtd"> <mycat:server xmlns:mycat="http://org.opencloudb/"> <!-- 添加user --> <user name="mycat_master"> <property name="password">mycat_master</property> <property name="schemas">mycat</property> </user> <!-- 添加user --> <user name="mycat_slave"> <property name="password">mycat_slave</property> <property name="schemas">mycat</property> <property name="readOnly">true</property> </user> </mycat:server>
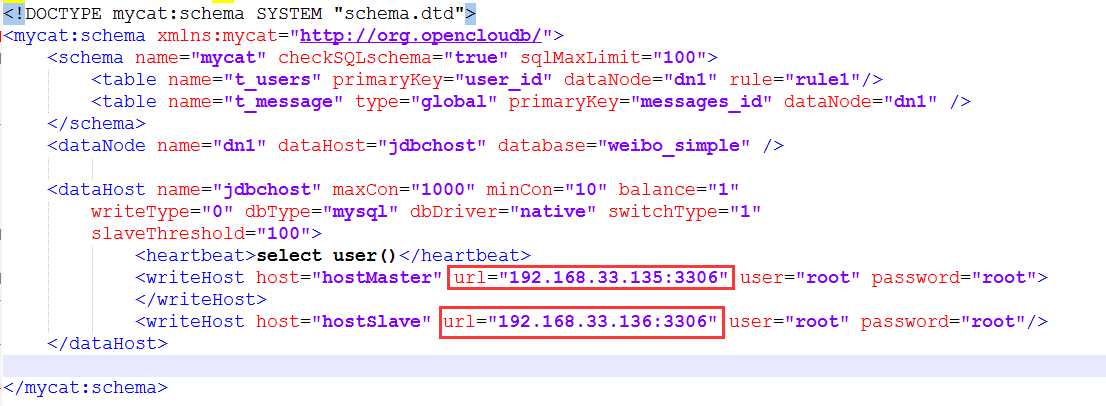
<!DOCTYPE mycat:schema SYSTEM "schema.dtd"> <mycat:schema xmlns:mycat="http://org.opencloudb/"> <schema name="mycat" checkSQLschema="true" sqlMaxLimit="100"> <table name="t_users" primaryKey="user_id" dataNode="dn1" rule="rule1"/> <table name="t_message" type="global" primaryKey="messages_id" dataNode="dn1" /> </schema> <dataNode name="dn1" dataHost="jdbchost" database="weibo_simple" /> <dataHost name="jdbchost" maxCon="1000" minCon="10" balance="1" writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100"> <heartbeat>select user()</heartbeat> <writeHost host="hostMaster" url="192.168.33.135:3306" user="root" password="root"> </writeHost> <writeHost host="hostSlave" url="192.168.33.136:3306" user="root" password="root"/> </dataHost> </mycat:schema>
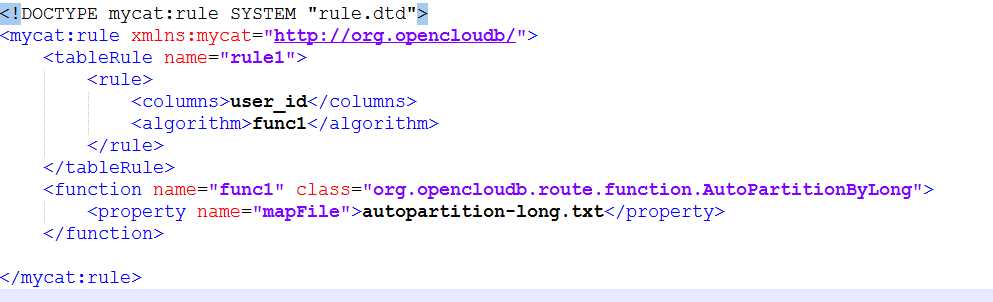
<!DOCTYPE mycat:rule SYSTEM "rule.dtd"> <mycat:rule xmlns:mycat="http://org.opencloudb/"> <tableRule name="rule1"> <rule> <columns>user_id</columns> <algorithm>func1</algorithm> </rule> </tableRule> <function name="func1" class="org.opencloudb.route.function.AutoPartitionByLong"> <property name="mapFile">autopartition-long.txt</property> </function> </mycat:rule>
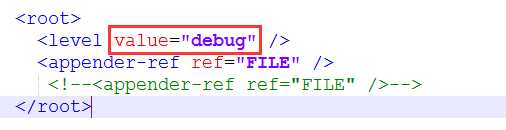
<root> <level value="debug" /> <appender-ref ref="FILE" /> <!--<appender-ref ref="FILE" />--> </root>
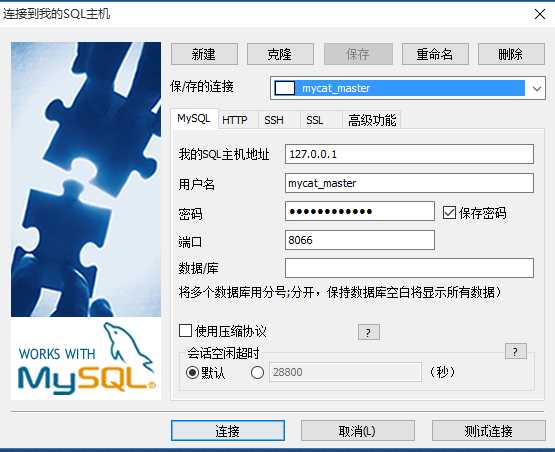

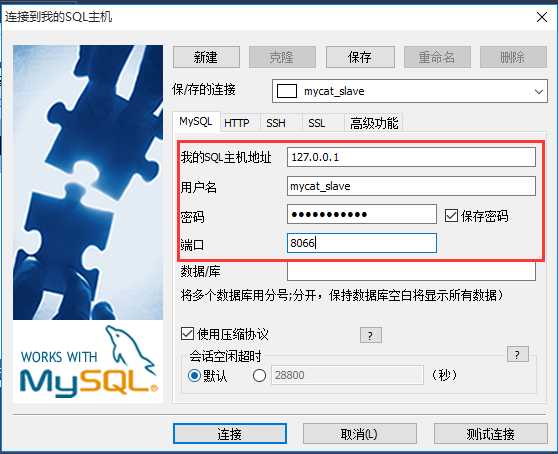
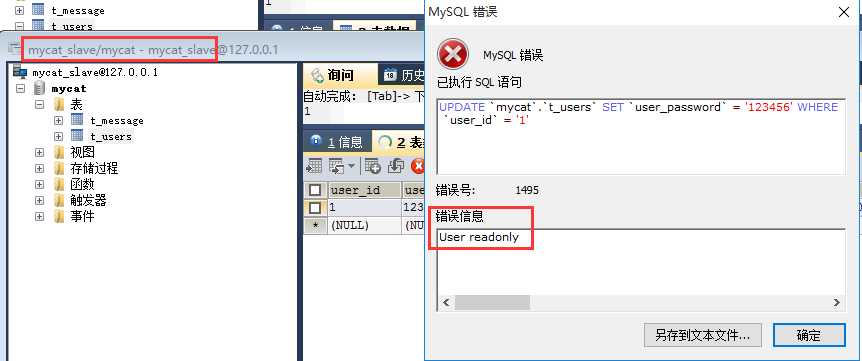
注意:在使用mycat连接SQLyog时,SQLyog版本不能太低,版本不能太低,不能太低,需要高版本!!!
标签:var 只读 添加 code imp pfile check create 完成
原文地址:https://www.cnblogs.com/Zzzzn/p/12343668.html