标签:direction 序列 应用 方向 str dde 重复 har 表示
我们都知道CNN常常被用在影像处理上,当然也可以用一般的neural network来做影像处理,不一定要用CNN。比如说你想要做影像的分类,
那么你就是training一个neural network,input一张图片,那么你就把这张图片表示成里面的pixel,也就是很长很长的vector。output就是(假如你有1000个类别,output就是1000个dimension)dimension。
但是呢,我们现在会遇到的问题是这样的,实际上我们在training neural network时,我们会期待说:在network的structure里面,每一个neural就是代表了一个最基本的classifier,
事实在文件上根据训练的结果,你有可能会得到很多这样的结论。举例来说:第一层的neural是最简单的classifier,它做的事情就是detain有没有绿色出现,有没有黄色出现,有没有斜的条纹。
第二个layer是做比这个更复杂的东西,根据第一个layer的output,它看到直线横线就是窗框的一部分,看到棕色纹就是木纹,看到斜条纹+灰色可能是很多的东西(轮胎的一部分等等)
再根据第二个hidden layer的outpost,第三个hidden layer会做更加复杂的事情。
但现在的问题是这样的,当我们一般直接用fully connect feedforward network来做影像处理的时候,往往我们会需要太多的参数,举例来说,假设这是一张100 *100的彩色图(一张很小的imgage),
你把这个拉成一个vector,(它有多少个pixel),它有100 *100 3的pixel。 如果是彩色图的话,每个pixel需要三个value来描述它,就是30000维(30000 dimension),那input vector假如是30000dimension,
那这个hidden layer假设是1000个neural,那么这个hidden layer的参数就是有30000 *1000,那这样就太多了。那么CNN做的事就是简化neural network的架构。
我们把这里面一些根据人的知识,我们根据我们对影像就知道,某些weight用不上的,我们一开始就把它滤掉。不是用fully connect feedforward network,而是用比较少的参数来做影像处理这件事。
所以CNN比一般的DNN还要简单的。
等一下我们讲完会觉得发现说:你可能觉得CNN运作很复杂,但事实上它的模型是要比DNN还要更简单的。我们就是用power-knowledge 去把原来fully connect layer中一些参数拿掉就成了CNN。

我们先来讲一下,为什么我们有可能把一些参数拿掉(为什么可以用比较少的参数可以来做影像处理这件事情)
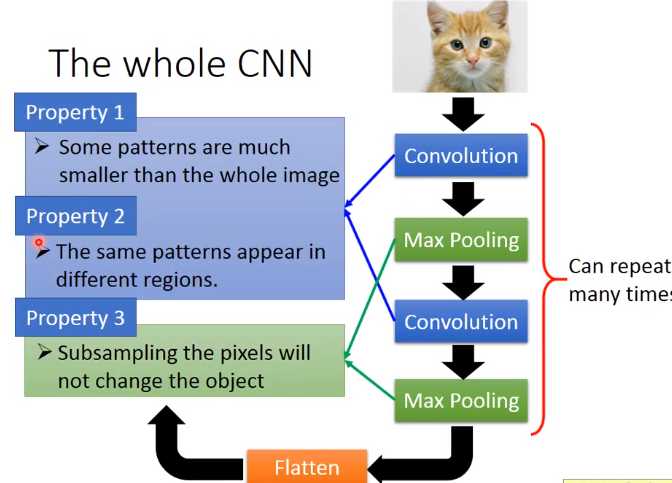
这里有几个观察,第一个是在影像处理里面,我们说第一层的 hidden layer那些neural要做的事就是侦测某一种pattern,有没有某一种patter出现。
大部分的pattern其实要比整张的image还要小,对一个neural来说,假设它要知道一个image里面有没有某一个pattern出现,它其实是不需要看整张image,它只要看image的一小部分。

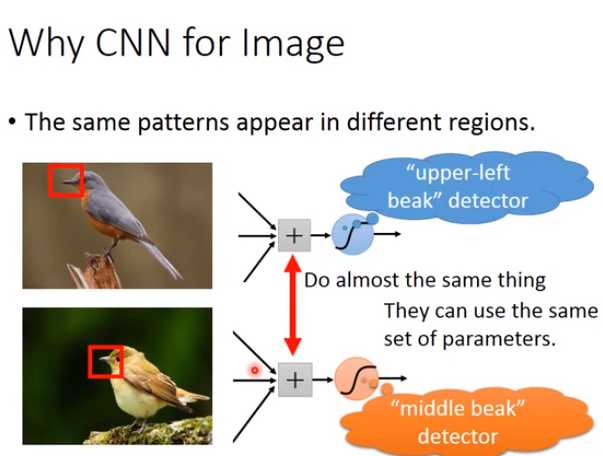
同样的pattern在image里面,可能会出现在image不同的部分,但是代表的是同样的含义,它们有同样的形状,可以用同样的neural,同样的参数就可以把patter侦测出来
我们知道一个image你可以做subsampling,你把一个image的奇数行,偶数列的pixel拿掉,变成原来十分之一的大小,它其实不会影响人对这张image的理解
所以我们就可以用这样的概念把image变小,这样就可以减少你需要的参数。

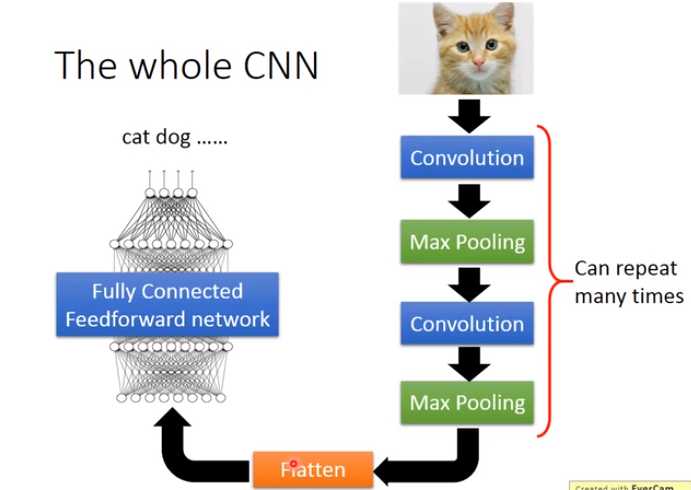
CNN 的架构
你要做几层的convolution,做几层的Max Pooling,你再定neural架构的时候,你要事先决定好
Convolution

假设现在我们的network的input是一张6*6的Image,如果是黑白的,一个pixel就只需要用一个value去描述它,1就代表有涂墨水,0就代表没有涂到墨水。
那在convolution layer里面,它由一组的filter,(其中每一个filter其实就等同于是fully connect layer里面的一个neuron),每一个filter其实就是一个matrix(3 *3),这每个filter里面的参数(matrix里面每一个element值)就是network的parameter(这些parameter是要学习出来的,并不是需要人去设计的)
每个filter如果是3* 3的detects意味着它就是再侦测一个3 *3的pattern(看3 *3的一个范围)。在侦测pattern的时候不看整张image,只看一个3 *3的范围内就可以决定有没有某一个pattern的出现。这个就是我们考虑的第一个Property
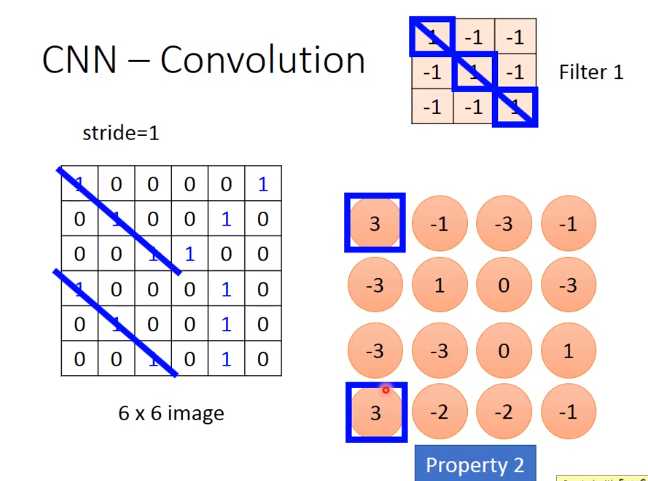
这个filter就会告诉你:左上跟左下出现最大的值(3*3的矩阵内积)
就代表说这个filter要侦测的pattern,出现在这张image的左上角和左下角,这件事情就考虑了propetry2。
同一个pattern出现在了左上角的位置跟左下角的位置,我们就可以用filter 1侦测出来,并不需要不同的filter来做这件事。
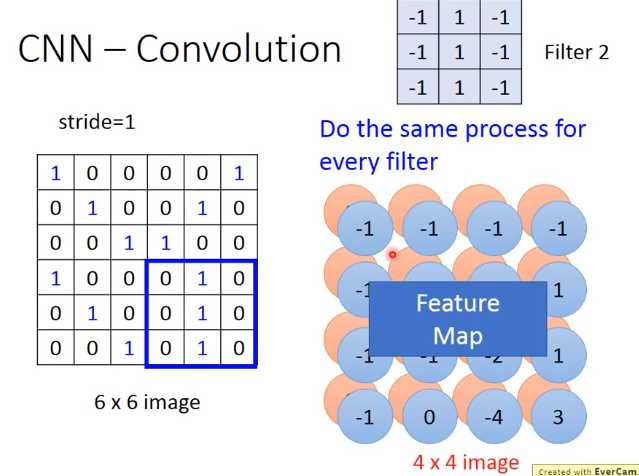
在一个convolution layer 里面会有很多的filter(刚才只是一个filter的结果),那另外的filter会有不同的参数(图中显示的filter2),它也做跟filter1一模一样的事情,
在filter放到左上角再内积得到结果-1,依次类推。你把filter2跟 input image做完convolution之后,你就得到了另一个4*4的matrix,红色4 *4的matrix跟蓝色的matrix合起来就叫做feature map,
看你有几个filter,你就得到多少个image(你有100个filter,你就得到100个4 *4的image)
彩色图片 RGB
input:3*6*6(立方体)
filter:3*3*3
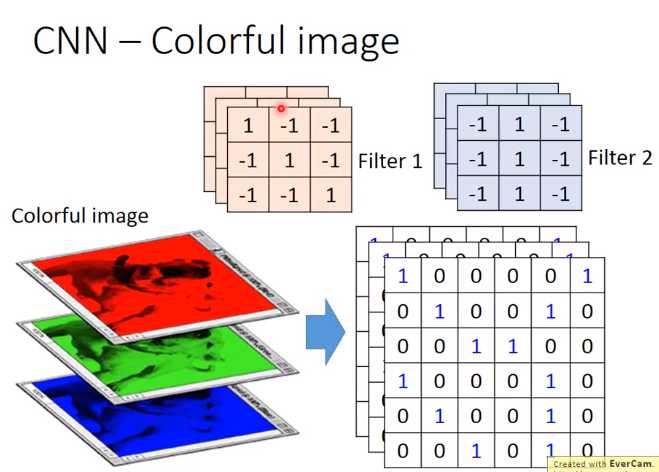
在做convolution的话,就是将filter的9个值和image的9个值做内积(不是把每一个channel分开来算,而是合在一起来算,一个filter就考虑了不同颜色所代表的channel)
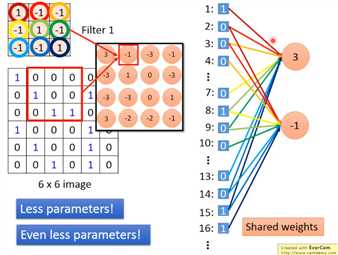
convolution就是fullly connected去掉一些weight
把6*6的image flatter 为vector(36),weight为Filter(用不同的颜色标记)如:左上角:1 2 3 7 8 9 13 14 15(每次9个,原来每次需要36个)
不同的neutral共用一个Weight(share weight)
减少weight和共用weight都可以减少parameter
Max Pooling
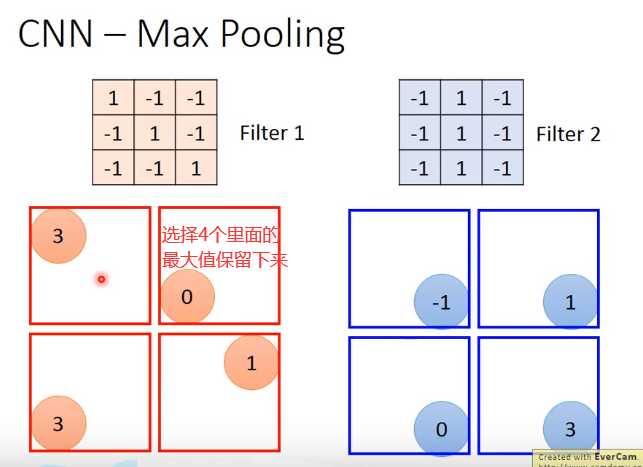
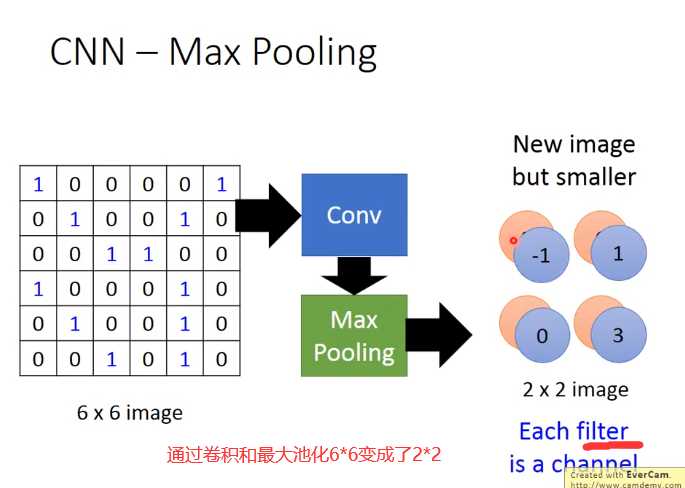
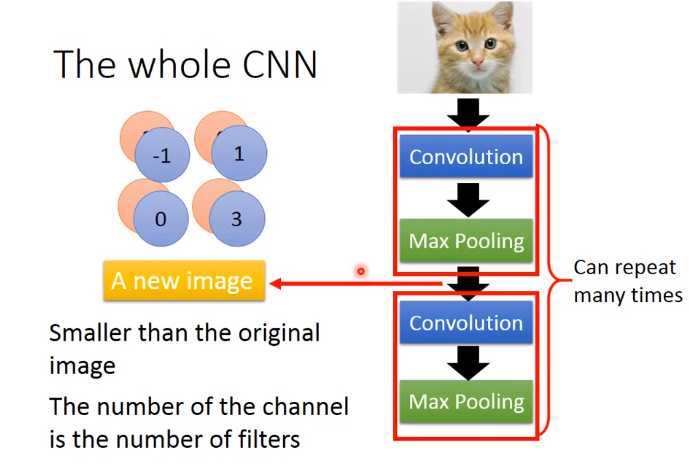
这边有一个问题:第一次有25个filter,得到25个feature map,第二个也是由25个filter,那将其做完是不是要得到25*25的feature map。其实不是这样的!
假设第一层filter有2个,第二层的filter在考虑这个imput时是会考虑深度的,并不是每个channel分开考虑,而是一次考虑所有的channel。
所以convolution有多少个filter,output就有多少个filter(convolution有25个filter,output就有25个filter。只不过,这25个filter都是一个立方体)
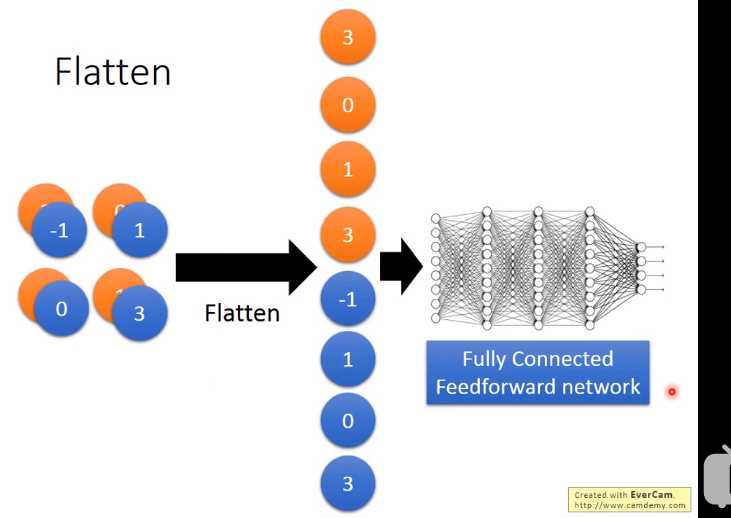
Flatten
CNN 在keras
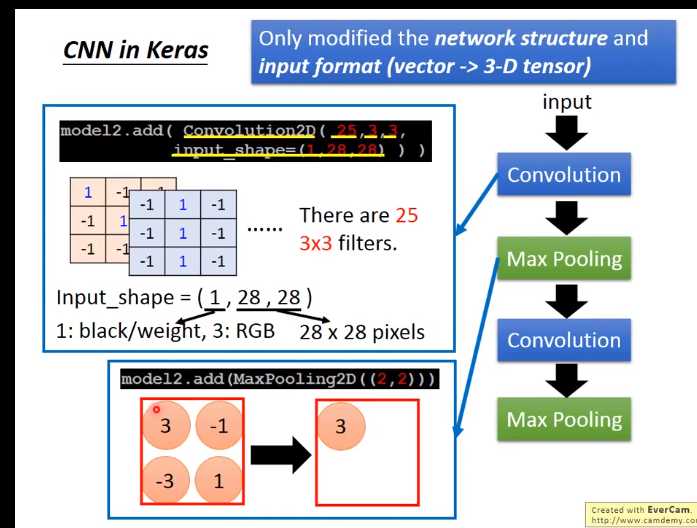
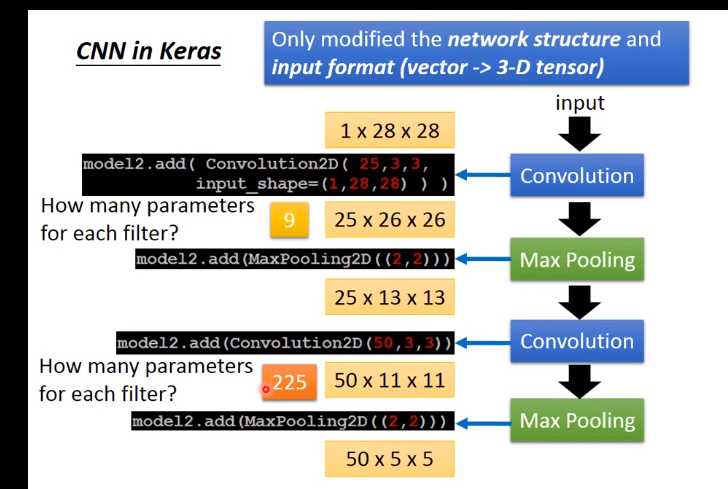
唯一要改的是:network structure和input format,本来在DNN中input是一个vector,现在是CNN的话,会考虑 input image的几何空间的,
所以不能给它一个vector。应该input一个tensor(高维的vector)。为什么要给三维的vector?因为image的长宽高各是一维,若是彩色的话就是第三维。所以要给三维的tensor model.add(Convolution2D( 25, 3, 3) 25代表有25个filter,3 *3代表filter是一个3 *3的matrix Input_shape=(28,28,1) 假设我要做手写数字辨识,input是28 *28的image,每个pixel都是单一颜色。所以input_shape是(1,28,28)。如果是黑白图为1(blacj/white),如果是彩色的图时为3(每个pixel用三个值来表述)。 MaxPooling2D(( 2, 2 )) 2,2表示把2*2的feature map里面的pixel拿出来,选择max value 假设我们input一个1 *28 * 28的image,你就可以写model.add(Convolution2D( 25, 3, 3, Input_shape=(28,28,1)))。通过convplution以后得到output是25 *26 26(25个filter,通过3 *3得到26 * 26)。
然后做max pooling,2 *2一组选择 max value得到 25 *13 * 13 然后在做一次convolution,假设我在这选50个filter,每一个filter是3 *3时,那么现在的channel就是50。13 *13的image通过3 *3的filter,就成11 *11,然后通过2 *2的Max Pooling,变成了50 *5 *5 在第一个convolution layer里面,每一个filter有9个参数,在第二个convolution layer里面,虽然每一个filter都是3 *3,但不是3 *3个参数,因为它input channel 是25个,所以它的参数是3 *3 *25(225)。(立体的) 通过两次convolution,两次Max Pooling,原来是1 *28 *28变为50 *5 *5。flatten的目的就是把50 *5 *5拉直,拉直之后就成了1250维的vector,然后把1250维的vector丢到fully connected。
分析input第一个filter是比较容易的,因为一个layer每一个filter就是一个3*3的mmatrix,对应到3 *3的范围内的9个pixel。所以你只要看到这个filter的值就可以知道说:它在detain什么东西,所以第一层的filter是很容易理解的,
但是你没有办法想要它在做什么事情的是第二层的filter。在第二层我们也是3 *3的filter有50个,但是这些filter的input并不是pixel(3 *3的9个input不是pixel)。而是做完convolution再做Max Pooling的结果。所以这个3 *3的filter就算你把它的weight拿出来,你也不知道它在做什么。另外这个3 *3的filter它考虑的范围并不是3 *3的pixel(9个pixel),而是比9个pxiel更大的范围。不要这3 *3的element的 input是做完convolution再加Max Pooling的结果。所以它实际上在image上看到的范围,是比3 *3还要更大的。那我们咋样来分析一个filter做的事情是什么呢,以下是一个方法。
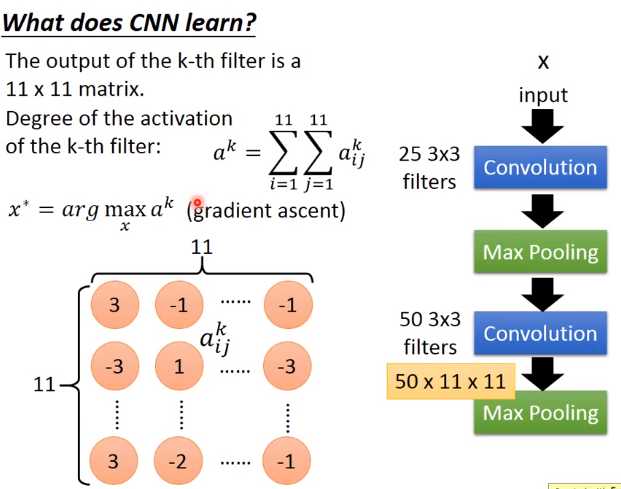
我们知道现在做第二个convolution layer里面的50个filter,每一个filter的output就是一个matrix(11*11的matrix)
接下来我们定义一个东西叫做:"Degree of the activation of the k-th filter",我们定义一个值代表说:现在第k个filter有多被active(现在的input跟第k个filter有多match),第k个filter被启动的Degree定义成:这个11*11的 matrix里面全部的 element的summation。(input一张image,然后看这个filter output的这个11 *11的值全部加起来,当做是这个filter被active的程度)
:我们想知道第k个filter的作用是什么,所以我们想要找一张image,这张image它可以让第k个filter被active的程度最大。
假设input一张image,我们称之为X,那我们现在要解的问题就是:找一个x,它可以让我们现在定义的activation Degree 最大,这件事情要咋样做到呢?其实是用gradient ascent你就可以做到这件事
(minimize使用gradient descent,maximize使用gradient ascent)
这是事还是蛮神妙的,我们现在是把X当做我们要找的参数用gradient ascent做update,原来在train CNN network neural的时候,input是固定的,model的参数是你需要用gradient descent找出来的,
用gradient descent找参数可以让loss被 minimize。但是现在立场是反过来的,现在在这个task里面,model的参数是固定的,我们要让gradient descent 去update这个X,
可以让这个activation function的Degree of the activation是最大的。
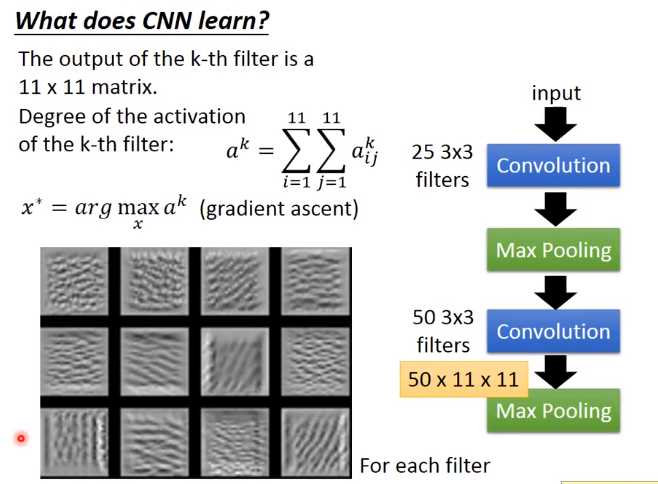
这个是得到的结果,如果我们随便取12个filter出来,每一个filter都去找一张image,这个image可以让那个filter的activation最大。现在有50个filter,你就要去找50张image,它可以让这些filter的activation最大。
随便取了前12个filter,可以让它最active的image出来(如图)。
这些image有一个共同的特征就是:某种纹路在图上不断的反复。比如说第三张image,上面是有小小的斜条纹,意味着第三个filter的工作就是detain图上有没有斜的条纹。
每一个filter考虑的范围都只是图上一个小小的范围。所以一个图上如果出现小小的斜的条纹的话,这个filter就会被active,这个output的值就会比较大。如果让图上所有的范围通通都出现这个小小的斜条纹的话,
那这个时候它的Degree activation会是最大的。(因为它的工作就是侦测有没有斜的条纹,所以你给它一个完整的数字的时候,它不会最兴奋。你给它都是斜的条纹的时候,它是最兴奋的)
发现:每一个filter的工作就是detain某一张pattern。比如说:第三图detain斜的线条,第四图是detain短的直线条,等等。每一个filter所做的事情就是detain不同角度的线条,如果今天input有不同角度的线条,
就会让某一个activation function,某一个filter的output值最大
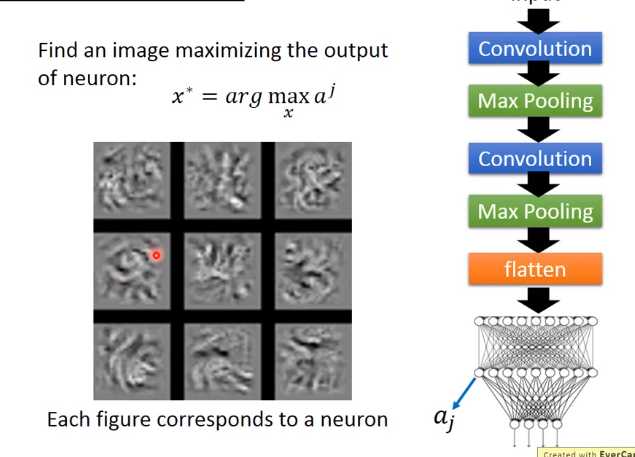
现在每一个neural,在你做flatten以后,每个neural的工作就是去看整张图,而不是是去看图的一小部分。
数字识别的例子
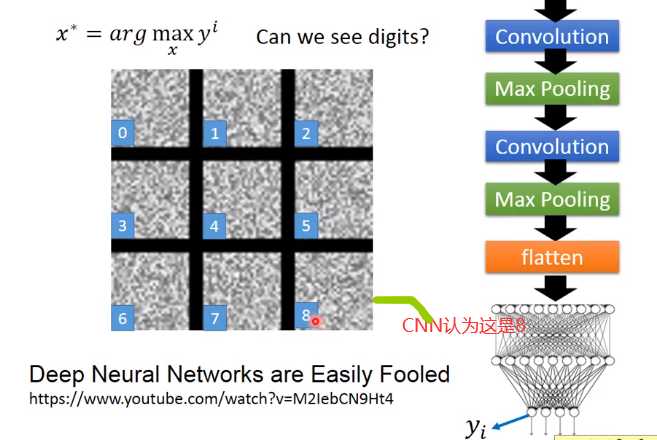
今天的这个neuron network它所学到东西跟我们人类是不太一样的
让图片更像数字

对x进行限制。我们告诉machine,有些x可能会使y很大但不是数字. image 里面的每一个pixel x(ij)
让yi最大的同时让sum(xij)越小越好。也就是我们希望找出的image,大部分的地方是没有涂颜色的,只有非常少的部分是有涂颜色的
加上constraint后得到右边的图
Deep Dream
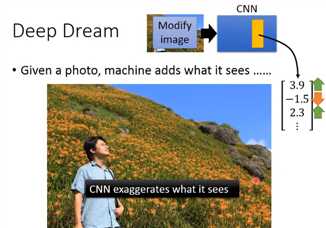
其实上述的想法就是Deep Dream的精神,Deep Dream是说:如果你给machine一张image,它会在这张image里加上它看到的东西。咋样做这件事情呢?
你先找一张image,然后将这张image丢到CNN中,把它的某一个hidden layer拿出来(vector),它是一个vector(假设这里是:[3.9, -1.5, 2.3...])。接下来把postitive dimension值调大,
把negative dimension值调小(正的变的更正,负的变得更负)。你把这个(调节之后的vector)当做是新的image的目标(把3.9的值变大,把-1.5的值变得更负,2.3的值变得更大。
然后找一张image(modify image)用GD方法,让它在hidden layer output是你设下的target)。这样做的话就是让CNN夸大化它所看到的东西,本来它已经看到某一个东西了,
你让它看起来更像它原来看到的东西。本来看起来是有一点像东西,它让某一个filter有被active,但是你让它被active的更剧烈(夸大化看到的东西)。

如果你把这张image拿去做Deep Dream的话,你看到的结果是这样子的。右边有一只熊,这个熊原来是一个石头(对机器来说,这个石头有点像熊,它就会强化这件事情,所以它就真的变成了一只熊)。
Deep Dream还有一个进阶的版本,叫做Deep Style
Deep Style

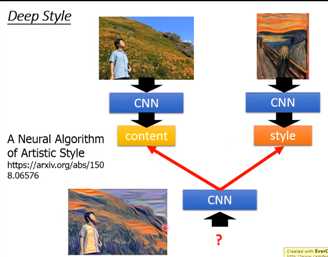
其中做法的精神是这样的:原来的image丢给CNN,然后得到CNN的filter的output,CNN的filter的output代表这张image有什么content。
接下来你把呐喊这张图也丢到CNN里面,也得到filter的output。我们并不在意一个filter ,而是在意filter和filter之间 的convolution,这个convolution代表了这张image的style。
接下来你用同一个CNN找一张image,这张image它的content像左边这张相片,但同时这张image的style像右边这张相片。你找一张image同时可以maximize左边的图,也可以maximize右边的图。
那你得到的结果就是像最底下的这张图。用的就是刚才讲的gradient ascent的方法找一张image,然后maximize这两张图,得到就是底下的这张图。
CNN 的应用
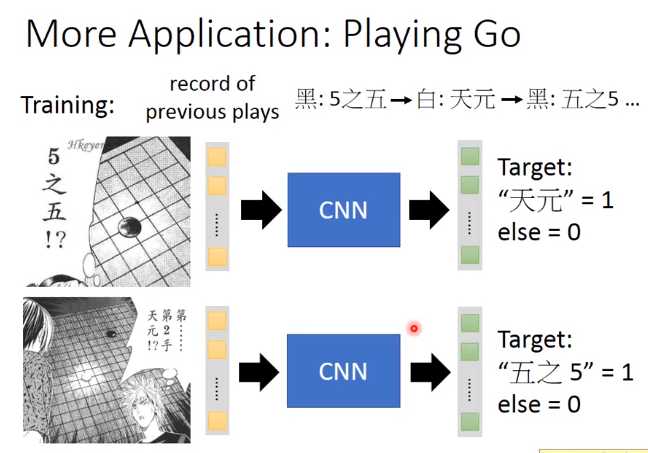
什么时候应该用CNN呢?image必须有该有的那些特性,在CNN开头就有说:根据那三个观察,所以设计出了CNN这样的架构。在处理image时是特别有效的。
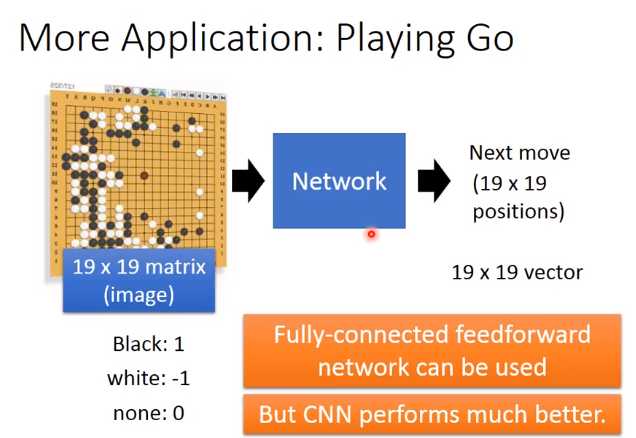
为什么这样的架构也同样可以用在围棋上面(因为围棋有一些特性跟影像处理是非常相似的)

一个白子被三个黑子围住(这就是一个pattern),你现在只需要看这一小小的范围,就可以知道白子是不是没“气”了,不需要看整个棋盘才能够知道这件事情,这跟image是有同样的性质。
在“AlphaGo”里面它的第一个layer filter其实就是用5*5的filter,显然做这个设计的人觉得说:围棋最基本的pattern可能都是在5 *5的范围内就可以被侦测出来,不需要看整个棋牌才能知道这件事情。

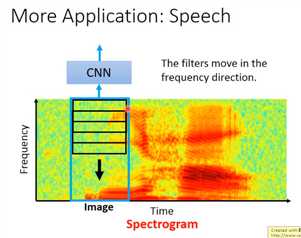
CNN也可以用在其它的task里面,比如说:CNN也用在影像处理上。如图是一段声音,你可以把一段声音表示成Spectrogram(横轴是时间,纵轴是那段时间里面声音的频率),
红色代表:在那段时间里那一频率的energy比较大。
这张image其实是我说“你好”,然后看到的Spectrogram。有通过训练的人,看这张image,就知道这句话的内容是什么。
人既然可以看这个image就可以知道是什么样的声音讯号,那我们也可以让机器把这个Spectrogram当做一张image。然后用CNN来判断:input一张image,它是对应什么样的声音讯号(单位可能是phone)。
但是神奇的地方是:CNN里面的时候,在语音上,我们通常只考虑在frequency方向上移动的filter。
如果把filter向时间的方向移动的话,结果是没有太大的帮助。这样的原因是:在语音里面,CNN的output还会接其他的东西(比如:LSTM),所以在向时间方向移动是没有太多的帮助。
为什么在频率上的filter会有帮助呢?我们用filter的目的是:为了detain同样的pattern出现在不同的range,我们都可以用同一个的filter detain出来。那在声音讯号上面,男生跟女生发同样的声音(同样说“你好”),
Spectrogram看起来是非常不一样的,它们的不同可能只是频率的区别而已(男生的“你好”跟女生的“你好”,它们的pattern其实是一样的)
所以今天我们把filter在frequency direction移动是有效的。当我们把CNN用在application时,你永远要想一想,这个application的特性是什么,根据那个application的特性来design network的structure
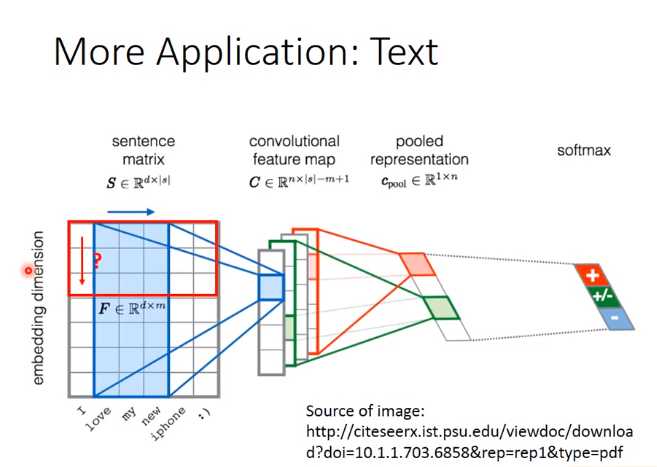
在文字处理上面,假设你要做的是:让machine侦测这个word sequence代表的是positive还是negative。首先input一个word sequence,你把word sequence里面的每一个word都用一个vector来表示。
这边的每一个vector代表word本身的sementic,如果两个word含义越接近的话,那它们的vector在高维的空间上就越接近,这个就叫做“wordembedding”(每一个word用vector来表示)。
当你把每一个word用vector来表示的时候,你把sentence所有的word排在一起,它就变成一张image。你可以把CNN套用在这个image上面。
当我们把CNN用在文字处理上的时候,你的filter其实是这个样子的(如图所示)。它的高跟image是一样的,你把filter沿着句子里面词汇的顺序来移动,然后你就会得到一个vector。
不同的filter就会得到不同的vector,然后Max Pooling,然后把Max Pooling的结果丢到fully connect里面,就会得到最后的结果。在文字处理上,filter只在时间的序列上移动,
不会在“embedding dimension”这个方向上移动。在“embedding dimension”方向上移动是没有帮助的,因为在word embedding里面每一个dimension的含义其实是独立的。
所以当我们如果使用CNN的时候,你会假设说:第二个dimension跟第一个dimension有某种特别的关系;第四个dimension跟第五个dimension有某种特别的关系。这个关系是重复的
(这个pattern出现在不同的位置是同样的意思)。但是在word embedding里面,不同dimension是独立的(independent)。所以在embedding dimension移动是没有意义的,所以你在做文字处理的时候,
你只会在sentence顺序上移动filter,这个是另外的例子。
标签:direction 序列 应用 方向 str dde 重复 har 表示
原文地址:https://www.cnblogs.com/tingtin/p/12346755.html