标签:exce 劳动力 str 抓取 struct ima 目标 excel 翻译
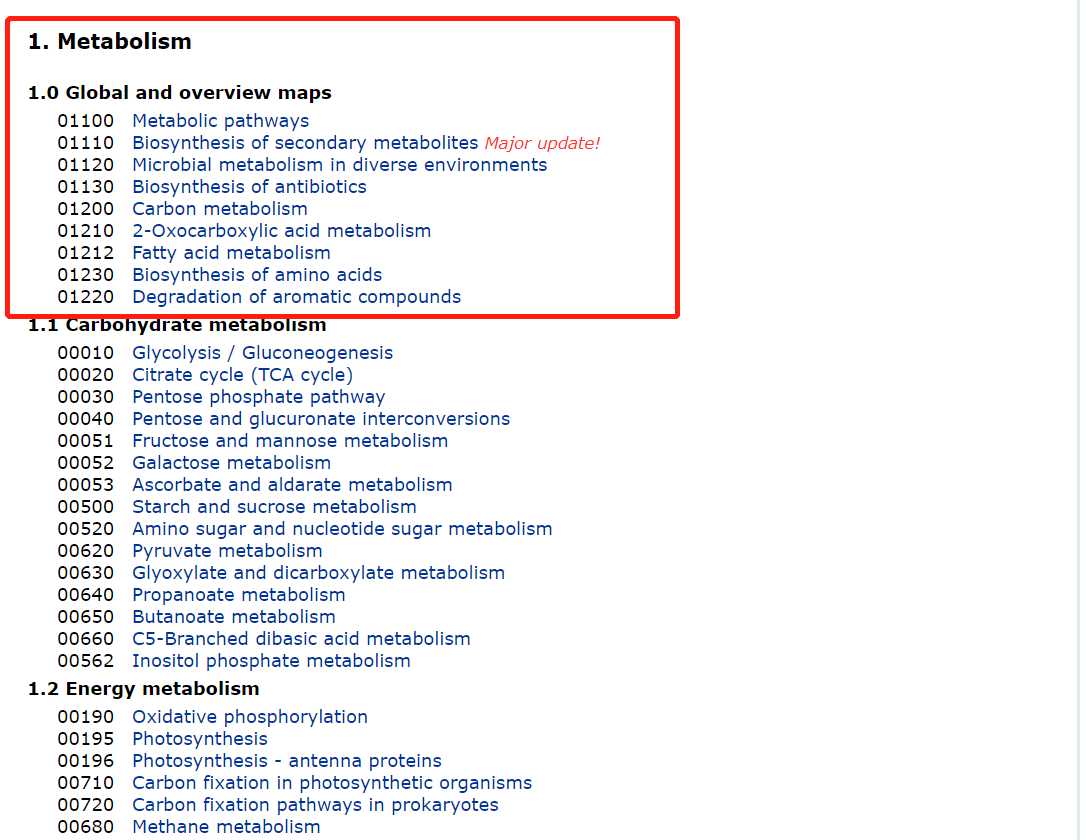
由于这是一个structured data,而且有一定的层次,鉴于需要较快完成信息的整理,所以并没有另外新学structured data信息的爬取(以后再说QAQ)
如果简单的复制粘贴的话,会变成以下模样...

(可能要改好久的换行符,我不!!!)
那首先直接抓取最多的元素,省去最多的劳动力
在检查元素后发现,像01100Metabolic pathways这样的元素都分组到某个list中,那么直接driver.find_elements_by_class_name(‘list‘),就可以获取95%以上的元素啦!
直接将目标元素以下格式输出即可~ (可以用panda库,也可以直接以\t分割复制到excel中)

由于需要翻译各个通道名,本来想用R调用谷歌翻译API,但是突然发现excel可以自己翻译了!!!
但是翻译水平还有待提高... 虽然还是要人工修改,但是已经省去不少滴工作~
当然也是先爬取网页信息,再粘贴啦,不然一个个复制会死的...
置顶用的是win32gui库
标签:exce 劳动力 str 抓取 struct ima 目标 excel 翻译
原文地址:https://www.cnblogs.com/TANGLi83/p/12347975.html