标签:version bin 分析法 元组 分组 cnn 方式 应该 sys
论文地址:使用半监督堆栈式自动编码器实现包含记忆的人工带宽扩展
作者:Pramod Bachhav, Massimiliano Todisco and Nicholas Evans
博客作者:凌逆战
博客地址:https://www.cnblogs.com/LXP-Never/p/10889975.html
为了提高宽带设备从窄带设备或基础设施接收语音信号的质量,开发了人工带宽扩展(ABE)算法。以动态特征或从邻近帧捕获的explicit memory(显式内存)的形式利用上下文信息,在ABE研究中很常见,但是使用额外的信息会增加复杂性,并会增加延迟。以前的工作表明,无监督的线性降维技术有助于降低复杂性。本文提出了一种利用Stacked Auto-Encoder(堆叠自动编码器)进行降维的半监督非线性方法。与以前的工作进一步对比,它对原始频谱进行操作,从原始频谱中以数据驱动的方式学习低维窄带表示。三种不同的客观语音质量指标表明,新特征可以与标准回归模型相结合来提高ABE的性能。学习到的特征和缺失的高频成分之间的相互信息也得到了改善,非正式的听力测试证实了语音质量得到了改善。
虽然传统的窄带(NB)电话基础设施的带宽被限制在0.3-3.4kHz,但今天的宽带(WB)技术支持使用从50Hz-7kHz扩展的带宽来提高语音质量。为了提高宽带设备与NB设备或基础设施一起使用时的语音质量,研究了人工带宽扩展(ABE)算法。利用两个[1]之间的相关性,ABE利用现有NB分量估计3.4kHz以上缺失的高频分量,通常采用从WB训练数据中学习的回归模型。
基于源滤波器模型的ABE方法估计了分离的频谱包络和激励分量[2,3]。其他ABE方法直接作用于推导出复杂的短期频谱估计,例如使用傅里叶变换(STFT)[4,5]或constant-Q变换[6]。与短期谱估计相补充的是某种形式的contextual information(上下文信息)或menory(记忆),可以用来提高HB分量估计的可靠性。一些特定的后端回归模型,如隐马尔可夫模型(HMMs)[7,8]和深度神经网络(DNNs)[9 11],以时间信息的形式捕捉memory。一些DNN解决方案,例如[4,12,13],在前端捕获memory,例如,通过增量特性或来自相邻帧的静态特性。在研究了ABE[14]的前端特征提取之后,[15 17]的工作通过信息论分析研究了memory包含的优点。本研究在固定维数的约束下,通过增量特征证明了memory包含的好处。然而,为了适应动态增量特性,memory的包含需要丢失高阶静态HB特性。我们自己的工作[18]定量地分析了固定ABE解决方案中显式内存包含的好处。该工作还解决了延迟和复杂性问题。使用主成分分析(PCA)来管理复杂性,以便在不增加特征维数的情况下纳入memory;回归复杂度不受影响。PCA是一种无监督的线性降维方法,它的目标只是生成一个低维表示,尽可能保留输入表示的变化。本文研究的假设是,监督或半监督和非线性降维技术为学习专门针对ABE的低维表示提供了可能,从而获得更好的性能。
自动编码器(AEs)是一种越来越受欢迎的非线性降维方法,已被广泛应用于许多语音处理任务,如音素/语音识别[19 21]和语音合成[22]。这些例子中常见的是使用AEs学习所谓的瓶颈特性,即针对模式识别和分类定制的紧凑特性表示。本论文研究了用堆叠(deep)AEs来降低ABE的非线性维数,特别是用经过半监督训练的堆叠(deep)自动编码器。我们的目标是
(i)在紧凑、低维的表示中利用memory,以提高估计的HB部分的可靠性;
(ii)直接从原始频谱系数而不是手工制作的特征中学习NB特征。通过客观评价、信息论方法和非正式的听力测试来评估这两篇文章的价值。
本文的其余部分组织如下。第2节描述了一个基线ABE算法。第3节展示了如何应用半监督堆叠AEs来提高其性能。第4节实验工作,第5节结果,第6节结论。
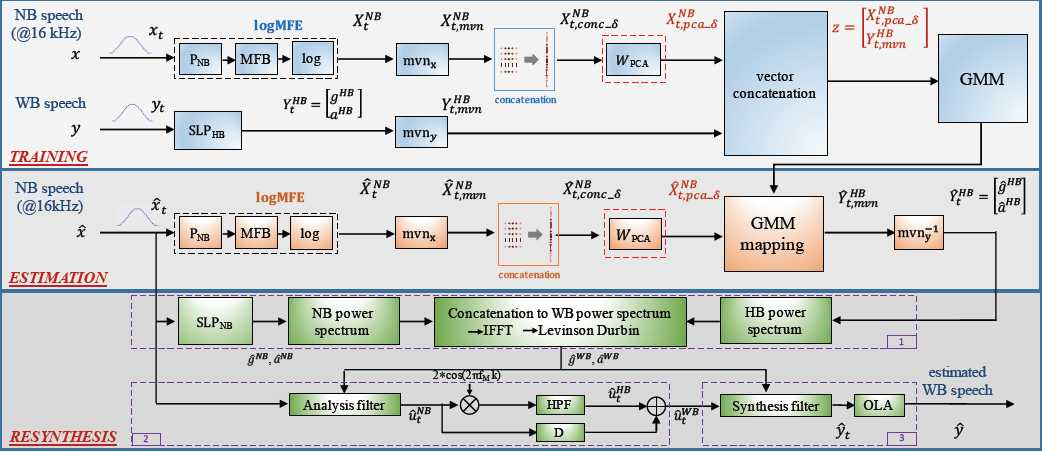
图1:包含memory的基线ABE系统框图
图1显示了基线ABE系统。它与[18]中提出的基于源滤波器模型的方法是一致的。由于上面提供了完整的细节,所以这里只提供一个简要的概述。该算法由训练、估计和再合成三个部分组成。
训练分别使用NB和WB帧frame-blocked(阻塞信号)$x_t$和$y_t$进行,其中t为时间指标。采用10 log-Mel滤波能量系数(logMFE)对NB分量进行参数化($X_t^{NB}$--训练框架的顶层)。通过选择线性预测(SLP)[23]对HB分量进行参数化,得到9个线性预测(LP)系数和一个增益参数($Y_t^{HB}$ -训练框架的底端)。NB和HB特征经过均值和方差正态化($mvn_x$和$mvn_y$),得到$X_{t,mvn}^{NB}$和$Y_{t,mvn}^{HB}$。将t时刻的NB特征与从$\delta $相邻帧中提取的特征串联起来,得到
$$X_{t,conc\_\delta }=[X_{t-\delta ,mvn}^{NB},...,X_{t ,mvn}^{NB},...,X_{t+\delta ,mvn}^{NB}]^T$$
为了限制复杂性,采用PCA(主成分分析法)将$X_{t,conc\_\delta}$降为10维特征$X_{t,pca\_\delta}^NB$。主成分分析矩阵$W_{PCA}$是从训练数据中学习而来,在估计步骤中保持不变。最后,使用串联$Z=[X_{t,pca\_\delta}^{NB}, Y_{t,mvn}^{HB}]^T$从训练数据中学习128分量全协方差高斯混合模型(GMM)。
对上采样过的NB信号$\hat{x}$进行估计。按照训练中相同的NB处理和memory inclusion进行处理得到10维特征$\hat{X}_{t,pca\_\delta}^{NB}$。然后将训练中学习的GMM参数定义的传统回归模型[2]用于估计HB特征$\hat{Y}_{t,mvn}^{HB}$。利用训练得到的均值和方差,采用逆均值和方差归一化($mvn_y^{-1}$)估计HB LP系数$\hat{a}^{HB}$和增益$\hat{g}^{HB}$。
根据图1中编号块所示的三个不同步骤进行重新合成。首先(框1)由NB LP参数$\hat{g}^{NB}$、$\hat{a}^{NB}$和估计的HB参数$\hat{g}^{HB}$、$\hat{a}^{HB}$定义的$\hat{x}_t$的NB和HB功率谱估计缺失WB功率谱。然后利用逆快速傅里叶反变换(IFFT)和Levinson-Durbin递归,从WB功率谱中得到估计的WB参数$\hat{g}^{WB}$和$\hat{a}^{WB}。第二(框2)采用由$\hat{g}^{NB}$和$\hat{a}^{NB}$定义的LP分析滤波器得到NB激励$\hat{u}_t^{NB}$。然后应用频谱平移[3]和高通滤波器(HPF)得到HB激励分量$\hat{u}_t^{HB}$,在适当的延迟D后加入$\hat{u}_t^{NB}$得到扩展的WB激励$\hat{u}_t^{WB}$。最后(框3)使用$\hat{g}^{WB}$和$\hat{a}^{WB}$定义的合成滤波器对$\hat{u}_t^{WB}$进行滤波,以重新合成语音帧$\hat{t}_t$。重叠和相加(OLA)得到扩展的WB语音$\hat{y}$。
基线ABE算法采用无监督的线性降维方法,使得在训练中学习并用于估计的标准回归模型的复杂度由于memory inclusion而保持不变。本文的工作是利用一种半监督的、非线性的、使用堆叠式自动编码器的降维技术来提高ABE的性能。
自动编码器(AE)是一种广泛用于学习高级数据表示的人工神经网络。声发射由编码器和解码器组成。编码器f()根据:
$$公式1:y=f_{\theta}(x)=s(Wx+b)$$
其中o = fW;bg为权矩阵W和偏置向量b的参数集,函数s为非线性变换。编码器后面是解码器g 0(),其目的是根据所学习的表示y重构原始输入:
$$z=g_{{\theta}‘}(y)={s}‘({W}‘y+{b}‘)$$
其中0 = fW0;根据输入x的性质,b0g和s0可以是线性变换,也可以是非线性变换。利用均方误差(MSE)目标损失函数对0g进行优化,该函数反映了输入和重建输出之间的差异。
更深层次的网络天生具有更强的能力来学习高度非线性和复杂的函数[24]。通过叠加多层编码器和解码器,可以增加声发射的深度,从而形成叠加式自动编码器(SAE)。然而,随着网络的增长,网络要找到全局最小[25]变得越来越困难。
为了缓解这些问题,通常采用某种形式的预训练来初始化网络权值。流行的解决方案包括使用受限玻尔兹曼机(RBMs)[25]进行预培训,以及对AEs[26]进行降噪。层在训练前堆积,然后进行微调。其他工作研究了网络初始化的替代方法,如[27,28]。
通过基于重构的目标损失函数,SAEs可以学习输入和重构输出之间的简单映射,而不是有意义的高级表示[26]。此外,由于没有监督,从传统SAE的瓶颈层提取的特征没有明确设计用于分类或回归;在这方面,它们可能不是最优的。在[24]中,部分监督的AEs预训练被证明是有益的,特别是对回归任务。
在此基础上,我们探索了SAEs的半监督训练,以便学习专门为回归建模和ABE设计的紧凑表示。得到的具有两个输出层的半监督SAE (SSAE)体系结构如图2所示。一个输出层学习用传统的SAE重构输入(AE输出),另一个输出层学习估计缺失的HB特征(回归输出)。这是通过给出的联合目标损失函数来实现的
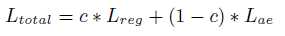
其中Lreg和Lae分别为回归和AE输出的目标损失函数,其中c2 [0];1]加权个人损失的贡献。
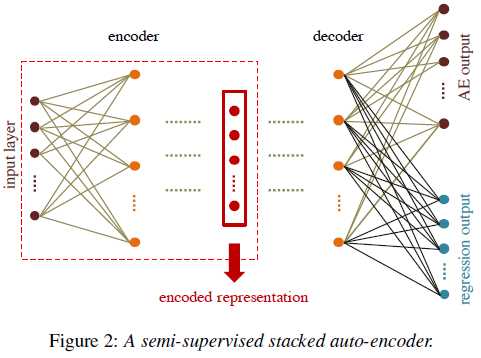
SSAE体系结构还可以用于直接从回归层估计HB组件。在[29]中报道了一个类似的基于CNN的体系结构,该结构设计用于规范化短i-向量到长i-向量的映射,用于演讲者的二值化任务。这里的重点是不同的,即。,规范/监督降维,以保存对ABE至关重要的信息。这些信息被一个标准的回归模型所利用。为了研究基于ssa的降维方法的优点,将图1(红色框)中的权值矩阵WPCA替换为SSAE编码器(图2中的红色框),然后对提取的低维特征进行均值和方差归一化。GMM的训练和估计按照第2节中描述的相同方式执行。本文还报道了这种方法的一个变体,即低维NB表示直接从NB对数功率谱(LPS)系数而不是logMFE特征得到。这是通过用LPS系数替换logMFE特性来实现的。
实验旨在比较使用PCA降维MPCA 2的基线ABE系统与使用SSAE降维MAE 2的基线ABE系统的性能。系统mpca2和MAE 2分别使用^X NB t;pca 2和^X NB t;ae 2;mvn特性。本节描述用于ABE实验的数据库、SSAE配置细节和度量。
4.1 数据集
TIMIT数据集[30]用于培训和验证。将训练集中的3696个话语和测试集中的1152个话语(不含核心测试子集)按照[6]中描述的步骤处理并行的WB和NB语音信号,训练ABE解。TIMIT核心测试子集(192条语句)用于验证和优化网络参数。受[31]中提出的分析方法的启发,使用由1378个语音组成的声学不同TSP数据库[32]进行测试。将TSP数据降采样至16kHz,并进行类似的预处理,得到并行的WB和NB数据。
4.2 SSAE训练和配置
SSAE是使用Keras工具包[33]实现的。与之前的工作[18]一致,特性Xt;将t时刻的conc2(由前两帧和后两帧拼接而成)输入SSAE。AE输出与输入相同,回归输出设为HB feature Y HB t;mvn。为了提高收敛速度到全局最小值,根据[28]中描述的方法对SSAE进行初始化。优化是根据[34]中描述的程序进行的,标准学习率为0.001,动量为0.9,MSE标准。
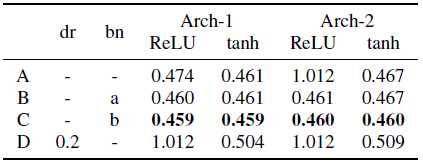
我们研究了两种6层对称SSAE结构,它们在隐层中具有不同的单元数:1)512、256、10、256、512 (Arch-1);2) 1024、512、10、512、1024 (Arch-2)。输出层由50个(AE)和10个(回归)单元组成。隐层具有tanh或ReLU激活单元,而输出层具有线性激活单元。研究了辍学(dr)[35]和批量标准化[36]技术,以防止过度拟合。当验证损失在连续两个时点之间增加时,学习率降低了一半。回归和AE损失权重均设为c=0.5。网络被训练了30个时代。
4.3 度量
业绩报告是根据客观评价。目标光谱失真测量包括:均方根对数光谱失真(RMS-LSD);所谓的COSH测度(对称版的Ikatura-Saito失真)[37]计算的频率范围为3.4-8kHz,并将WB扩展到感知分析的语音质量算法[38]。后者给出了平均意见得分的客观估计(mo - lqowb)。通过互信息(MI)[14]测量SSAE和PCA表示与HB特征的相关性。
表1显示了激活(bn-a)之后或激活(bn-b)之前执行的两种不同体系结构和四种不同的dropout (dr)和批处理规范化组合的MSE的验证性能。在所有隐藏层之前使用Dropout层。相对较低的MSE值是在没有退出或批量标准化(配置A)的情况下实现的,尽管对于具有ReLU激活的Arch-2来说性能很差。在没有批处理规范化(configuration D)的情况下使用dropout会导致网络的非规范化,特别是对于ReLU激活。类似的观察在[31]中也有报道。使用任何一种没有退出的批处理正常化方法都可以得到较低的MSE值,最好的结果是使用bn-b配置(C)得到的。本文其余部分报告的所有结果都与此配置有关。
表1:不同SSAE配置的平均MSE,包括体系结构1和体系结构2,具有ReLU或tanh激活函数,具有或不具有dropout (dr)和batch normalisation (bn)(在(a)激活后或激活前)。dr值表示被设置为0的随机隐藏单元的分数。使用验证数据集对评估结果进行了说明。
从测试集以及基线MPCA 2和基于ssa的MAE 2到ABE方法中获得的性能指标如表2所示。只有一个例外,光谱失真度量结果显示SSAE值低于基线值。SSAE系统的莫斯- lqowb评分始终较高。激活tanh的Arch-2 SSAE系统性能最好。不幸的是,尽管客观表现指标有令人信服的改进,非正式的听力测试显示基线和SSAE系统产生的语音信号质量之间几乎没有明显的差异。
表2:目标性能度量结果。在dB中,RMS-LSD和dCOSH是平均光谱失真度量(低值表示更好的性能),而莫斯- lqowb值反映质量(高值表示更好的性能)。
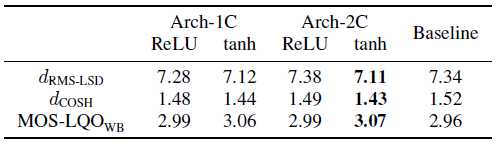
表3显示了使用LPS输入(而不是logMFE特性)训练的两种性能最佳的SSAE配置Arch-1C和Arch-2C(都是tanh激活)的目标性能度量。失真测量值始终较低,而莫斯- lqowb评分始终高于所有其他基于ssa的系统的结果。与使用logMFE功能的SSAE系统的结果相反,非正式听力测试显示,与使用基线ABE系统生成的语音相比,语音质量有明显改善。在logMFE和LPS输入上运行的基线和SSAE系统产生的带宽扩展语音的例子可以在网上找到。
表3:使用原始对数功率谱(LPS)输入代替对数- mel滤波能量(logMFE)对SSAE进行客观评价的结果。
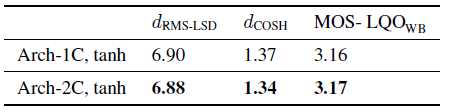
最后一组结果旨在进一步验证客观和非正式听力测试的结果。这是通过观察改善之间的互信息(MI)和真正的学会了NB表示HB表示测量使用测试集。128 -组件fullcovariance GMM和联合训练向量由学会NB和真正的HB特性用于MI估计如[18]所述。表4所示的MI结果表明,使用LPS输入训练tanh激活的Arch-2C SSAE系统的MI相对于基线系统增加了23%。这一结果证实了上述发现,即对原始光谱输入进行操作的半监督技术能够学习更好的表示,从而提高ABE性能。
表4:互信息评估结果。我(X;表示特征X与特征Y之间的MI。

提出了一种用于人工带宽扩展的非线性半监督降维方法。进一步利用叠置自编码器学习高阶表示的能力,直接从原始光谱中学习紧凑窄带特征。该方法的优点通过不同的客观指标得到了证明,并通过非正式听力测试的结果得到了证实。信息理论分析证实了新特征的有效性。在不增加复杂度的情况下,标准的回归模型可以使用以数据处理方式从原始光谱中提取的特征。利用潜在的光谱模型转换及其进一步优化来学习ABE的特性应该是我们未来的重点。进一步的工作还应该研究半监督的自动编码器与非监督或部分监督的训练前方法的结合。这些可能提供了更大的潜力,以提高人工带宽扩展语音的质量。
[1] Y. Cheng, D. O’Shaughnessy, and P. Mermelstein, “Statistical recovery of wideband speech from narrowband speech,” IEEE Trans. on Speech and Audio Processing, vol. 2, no. 4, pp. 544–548, 1994.
[2] K.-Y. Park and H. Kim, “Narrowband to wideband conversion of speech using GMM based transformation,” in Proc. of IEEE
Int. Conf. on Acoustics, Speech, and Signal Processing (ICASSP),vol. 3, 2000, pp. 1843–1846.
[3] P. Jax and P. Vary, “On artificial bandwidth extension of telephone speech,” Signal Processing, vol. 83, no. 8, pp. 1707–1719, 2003.
[4] K. Li and C.-H. Lee, “A deep neural network approach to speech bandwidth expansion,” in Proc. of IEEE Int. Conf. on Acoustics,Speech and Signal Processing (ICASSP), 2015, pp. 4395–4399.
[5] R. Peharz, G. Kapeller, P. Mowlaee, and F. Pernkopf, “Modeling speech with sum-product networks: Application to bandwidth extension,” in Proc. of IEEE Int. Conf. on Acoustics, Speech and Signal Processing, 2014, pp. 3699–3703.
[6] P. Bachhav, M. Todisco, M. Mossi, C. Beaugeant, and N. Evans, “Artificial bandwidth extension using the constant Q transform,” in Proc. of IEEE Int. Conf. on Acoustics, Speech and Signal Processing (ICASSP), 2017, pp. 5550–5554.
[7] C. Ya?gli and E. Erzin, “Artificial bandwidth extension of spectral envelope with temporal clustering,” in Proc. of IEEE Int. Conf.on Acoustics, Speech, and Signal Processing (ICASSP), 2011, pp.5096–5099.
[8] I. Katsir, D. Malah, and I. Cohen, “Evaluation of a speech bandwidth extension algorithm based on vocal tract shape estimation,” in Proc. of Int. Workshop on Acoustic Signal Enhancement(IWAENC). VDE, 2012, pp. 1–4.
[9] Y. Wang, S. Zhao, D. Qu, and J. Kuang, “Using conditional restricted boltzmann machines for spectral envelope modeling in speech bandwidth extension,” in Proc. of IEEE Int. Conf. on Acoustics, Speech, and Signal Processing (ICASSP), 2016, pp.5930–5934.
[10] Y. Gu, Z.-H. Ling, and L.-R. Dai, “Speech bandwidth extension using bottleneck features and deep recurrent neural networks.” in Proc. of INTERSPEECH, 2016, pp. 297–301.
[11] Y. Wang, S. Zhao, J. Li, J. Kuang, and Q. Zhu, “Recurrent neural network for spectral mapping in speech bandwidth extension,” in Proc. of IEEE Global Conf. on Signal and Information Processing(GlobalSIP), 2016, pp. 242–246.
[12] B. Liu, J. Tao, Z. Wen, Y. Li, and D. Bukhari, “A novel method of artificial bandwidth extension using deep architecture,” in Sixteenth Annual Conf. of the Int. Speech Communication Association,2015.
[13] J. Abel, M. Strake, and T. Fingscheidt, “Artificial bandwidth extension using deep neural networks for spectral envelope estimation,” in Proc. of Int. Workshop on Acoustic Signal Enhancement(IWAENC). IEEE, 2016, pp. 1–5.
[14] P. Jax and P. Vary, “Feature selection for improved bandwidth extension of speech signals,” in Proc. IEEE Int. Conf. on Acoustics,Speech, and Signal Processing (ICASSP), 2004, pp. I–697.
[15] A. Nour-Eldin, T. Shabestary, and P. Kabal, “The effect of memory inclusion on mutual information between speech frequency bands,” in Proc. of IEEE Int. Conf. on Acoustics, Speech, and Signal Processing (ICASSP), vol. 3, 2006, pp. III–III.
[16] A. Nour-Eldin and P. Kabal, “Objective analysis of the effect of memory inclusion on bandwidth extension of narrowband speech,” in Proc. of INTERSPEECH, 2007, pp. 2489–2492.
[17] ——, “Mel-frequency cepstral coefficient-based bandwidth extension of narrowband speech,,” in Proc. of INTERSPEECH,2008, pp. 53–56.
[18] P. Bachhav, M. Todisco, and N. Evans, “Exploiting explicit memory inclusion for artificial bandwidth extension,” in Proc. of IEEE Int. Conf. on Acoustics, Speech and Signal Processing (ICASSP),2018, pp. 5459–5463.
[19] J. Gehring, Y. Miao, F. Metze, and A. Waibel, “Extracting deep bottleneck features using stacked auto-encoders,” in Proc. of IEEE Int. Conf. on Acoustics, Speech and Signal Processing (ICASSP),2013, pp. 3377–3381.
[20] T. Sainath, B. Kingsbury, and B. Ramabhadran, “Auto-encoder bottleneck features using deep belief networks,” in Proc. of IEEE Int. Conf. on Acoustics, Speech and Signal Processing (ICASSP),2012, pp. 4153–4156.
[21] D. Yu and M. Seltzer, “Improved bottleneck features using pretrained deep neural networks,” in Twelfth Annual Conf. of the Int.Speech Communication Association, 2011.
[22] S. Takaki and J. Yamagishi, “A deep auto-encoder based lowdimensional feature extraction from fft spectral envelopes for statistical parametric speech synthesis,” in Proc. of IEEE Int. Conf.on Acoustics, Speech and Signal Processing (ICASSP), 2016, pp.5535–5539.
[23] J. Markel and A. Gray, Linear prediction of speech. Springer Science & Business Media, 2013, vol. 12.
[24] Y. Bengio, P. Lamblin, D. Popovici, and H. Larochelle, “Greedy layer-wise training of deep networks,” in Advances in neural information processing systems, 2007, pp. 153–160.
[25] G. Hinton and R. Salakhutdinov, “Reducing the dimensionality of data with neural networks,” science, vol. 313, no. 5786, pp. 504–507, 2006.
[26] P. Vincent, H. Larochelle, I. Lajoie, Y. Bengio, and P.-A. Manzagol,“Stacked denoising autoencoders: Learning useful representations in a deep network with a local denoising criterion,”Journal of Machine Learning Research, vol. 11, no. Dec, pp.3371–3408, 2010.
[27] X. Glorot and Y. Bengio, “Understanding the difficulty of training deep feedforward neural networks,” in Proc. of the Thirteenth Int.Conf. on Artificial Intelligence and Statistics, 2010, pp. 249–256.
[28] K. He, X. Zhang, S. Ren, and J. Sun, “Delving deep into rectifiers:Surpassing human-level performance on imagenet classification,” in Proc. of the IEEE int. conf. on computer vision, 2015, pp. 1026–1034.
[29] J. Guo, U. A. Nookala, and A. Alwan, “CNN-based joint mapping of short and long utterance i-vectors for speaker verification using short utterances,” Proc. of INTERSPEECH, pp. 3712–3716, 2017.
[30] J. Garofolo, L. Lamel, W. Fisher, J. Fiscus, and D. Pallett,“DARPA TIMIT acoustic-phonetic continous speech corpus CDROM.NIST speech disc 1-1.1,” NASA STI/Recon technical report N, vol. 93, 1993.
[31] J. Abel and T. Fingscheidt, “Artificial speech bandwidth extension using deep neural networks for wideband spectral envelope estimation,” IEEE Trans. on Audio, Speech, and Language Processing,vol. 26, no. 1, pp. 71–83, 2018.
[32] P. Kabal, “TSP speech database,” McGill University, Database Version : 1.0, pp. 02–10, 2002.
[33] F. Chollet et al., “Keras,” https://github.com/keras-team/keras,2015.
[34] D. Kingma and J. Ba, “Adam: A method for stochastic optimization,” arXiv preprint arXiv:1412.6980, 2014.
[35] N. Srivastava, G. Hinton, A. Krizhevsky, I. Sutskever, and R. Salakhutdinov, “Dropout: A simple way to prevent neural networks from overfitting,” The Journal of Machine Learning Research,vol. 15, no. 1, pp. 1929–1958, 2014.
[36] S. Ioffe and C. Szegedy, “Batch normalization: Accelerating deep network training by reducing internal covariate shift,” in Int. conf.on machine learning, 2015, pp. 448–456.
[37] R. Gray, A. Buzo, A. Gray, and Y. Matsuyama, “Distortion measures for speech processing,” IEEE Trans. on Acoustics, Speech,and Signal Processing, vol. 28, no. 4, pp. 367–376, 1980.
[38] “ITU-T Recommendation P.862.2 : Wideband extension to Recommendation P.862 for the assessment of wideband telephone networks and speech codecs,” ITU, 2005.
标签:version bin 分析法 元组 分组 cnn 方式 应该 sys
原文地址:https://www.cnblogs.com/LXP-Never/p/10889975.html