标签:实践 构造 proc 遍历 复杂 机器 lib taf 高维数据
导读:伴随着AI的兴起,越来越多的智能产品诞生,算法链路也会变得越来越复杂,在工程实践中面临着大量算法模型的从0到1快速构建和不断迭代优化的问题,本文将介绍如何打通数据分析-样本标注-模型训练-监控回流的闭环,为复杂算法系统提供强有力的支持。
新技术/实用技术点:

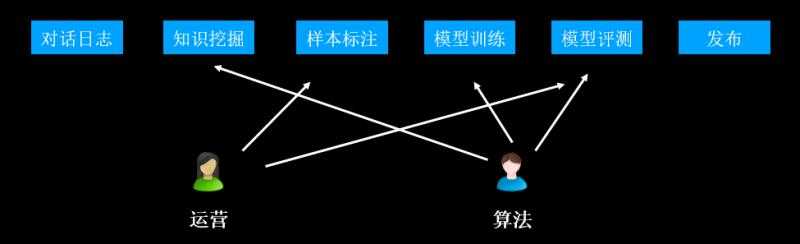
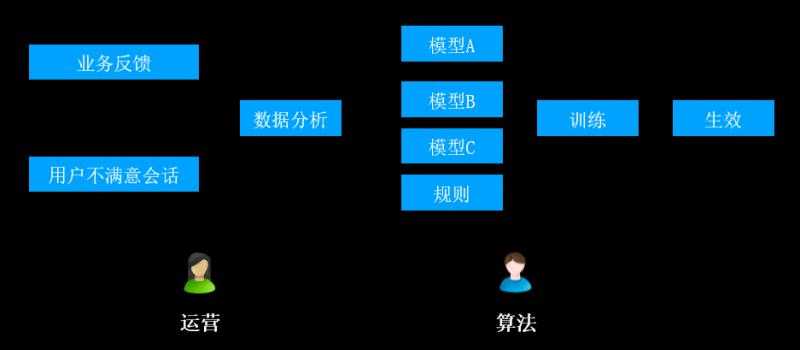
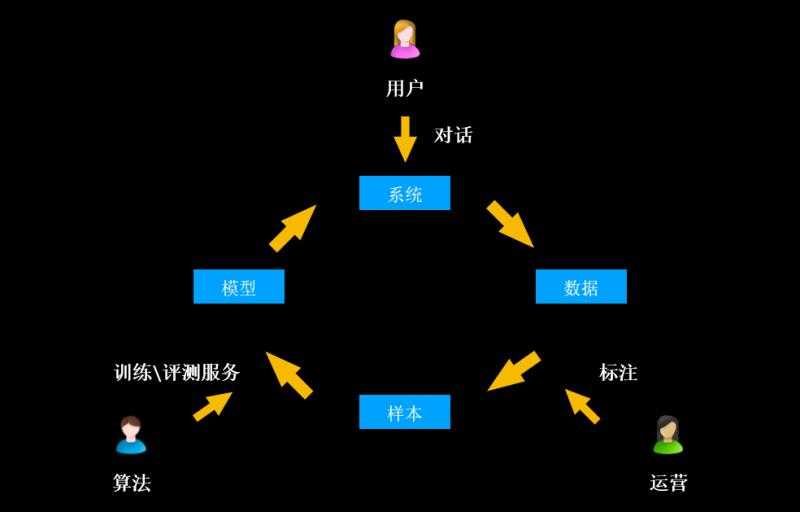
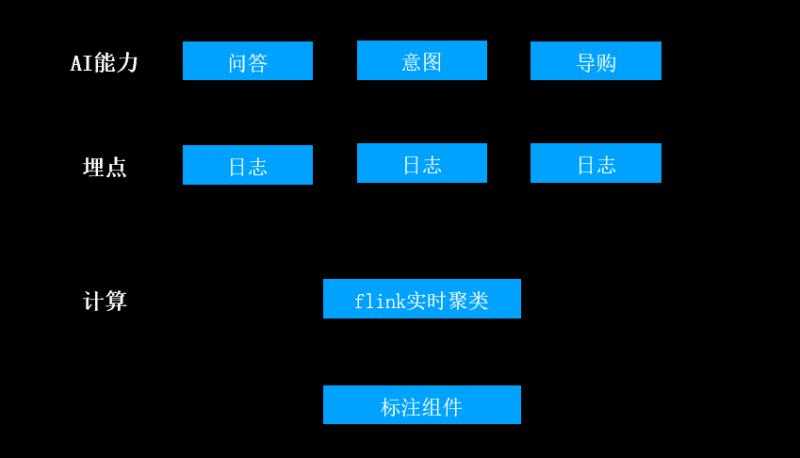
A. 对话系统层:用户端会跟机器人系统进行对话
B. 对话产生的日志经过数仓埋点进入到数据层
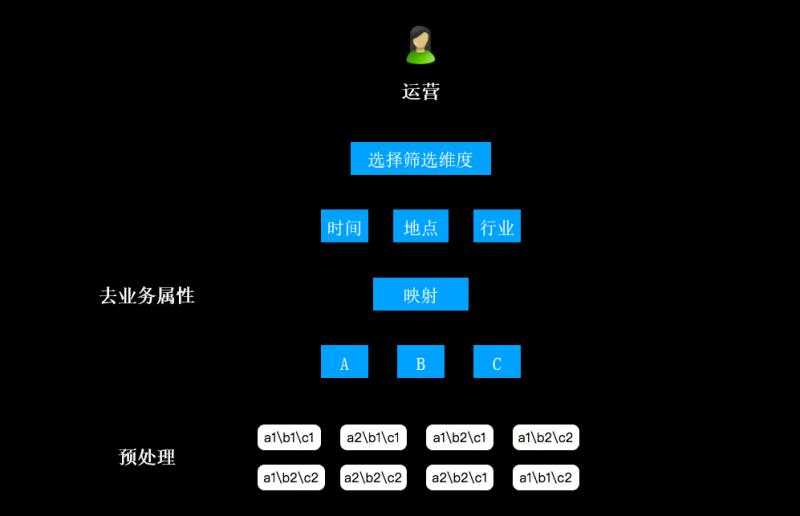
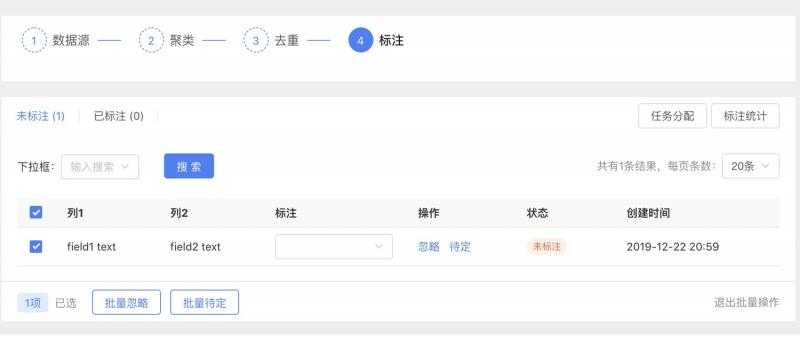
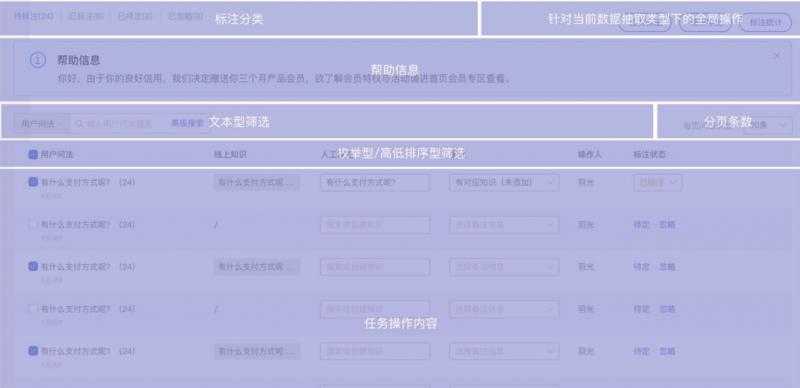
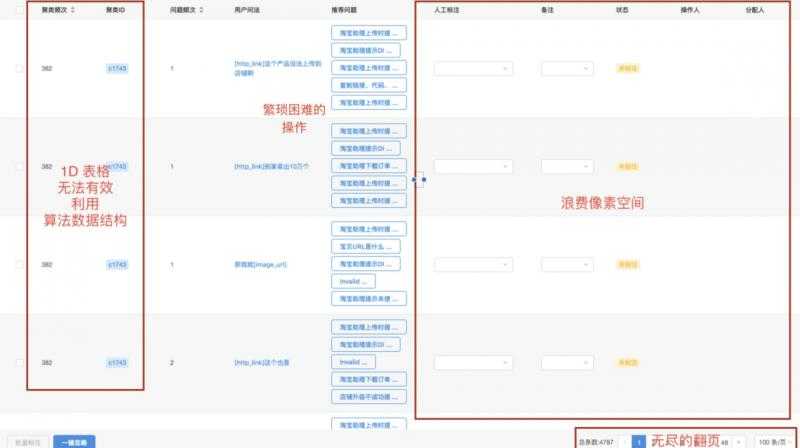
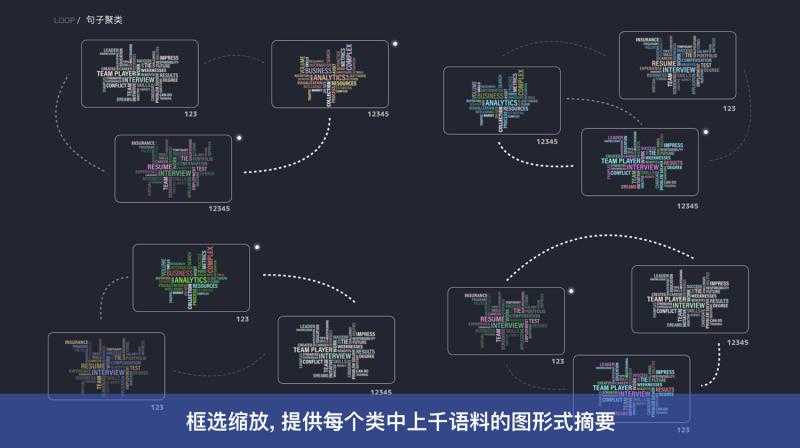
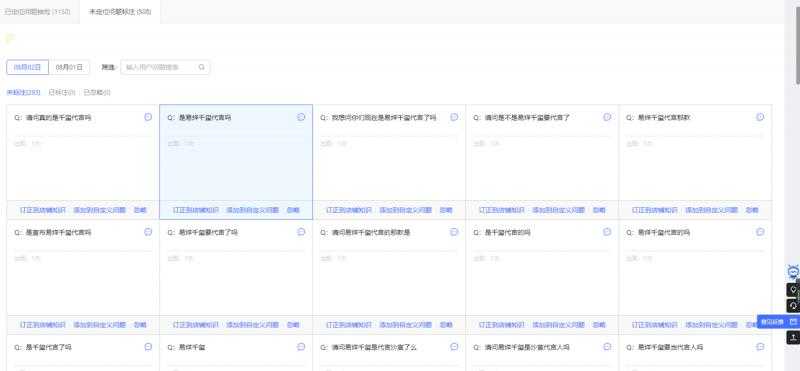
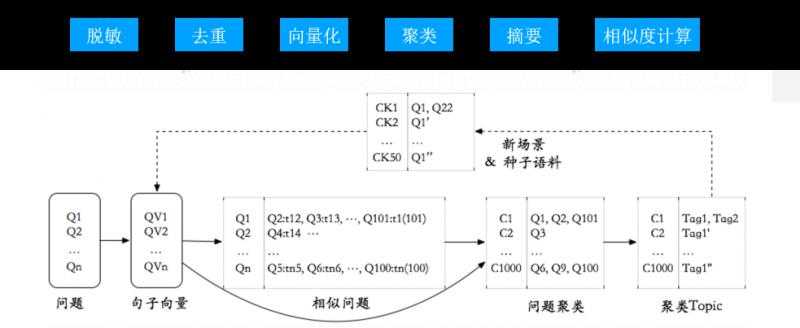
C. 数据层由运营人员做标注
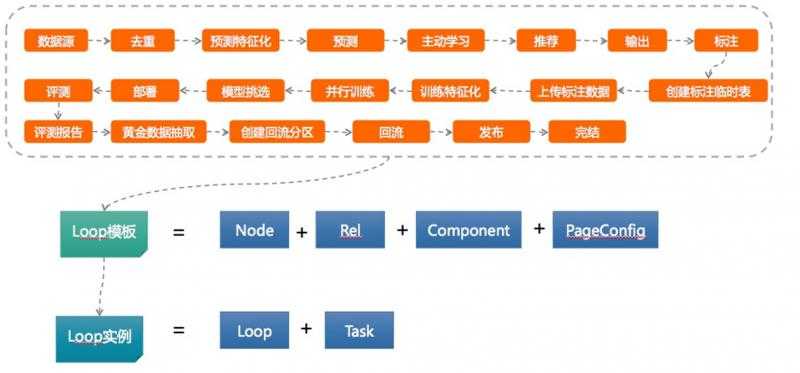
D. 完成标注的数据作为样本,借助算法团队提供的训练/评测服务,进入到模型层
E. 模型发布到系统中,形成训练闭环
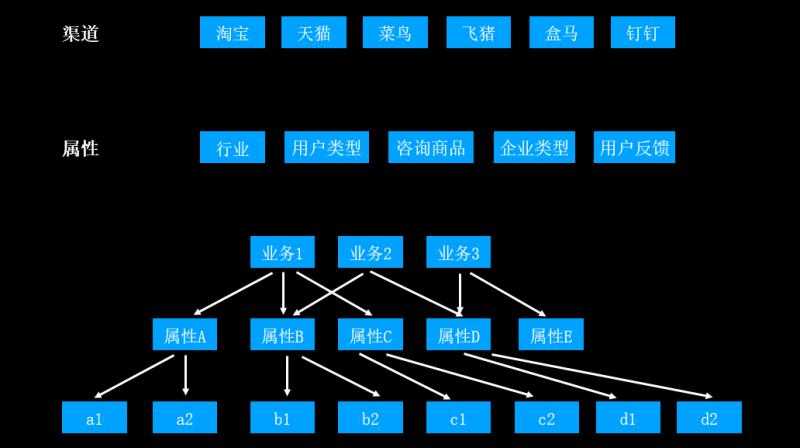




标签:实践 构造 proc 遍历 复杂 机器 lib taf 高维数据
原文地址:https://www.cnblogs.com/datafuntalk/p/12357981.html