标签:ble creat 区别 buffere ref contain details har nbsp
有关httpclient:
HttpClient相比传统JDK自带的URLConnection,增加了易用性和灵活性,它不仅使客户端发送Http请求变得容易,而且也方便开发人员测试接口(基于Http协议的),提高了开发的效率,也方便提高代码的健壮性。因此熟练掌握HttpClient是很重要的必修内容,掌握HttpClient后,相信对于Http协议的了解会更加深入。
org.apache.commons.httpclient.HttpClient与org.apache.http.client.HttpClient的区别
Commons的HttpClient项目现在是生命的尽头,不再被开发, 已被Apache HttpComponents项目HttpClient和HttpCore 模组取代,提供更好的性能和更大的灵活性。
一、简介
HttpClient是Apache Jakarta Common下的子项目,用来提供高效的、最新的、功能丰富的支持HTTP协议的客户端编程工具包,并且它支持HTTP协议最新的版本和建议。HttpClient已经应用在很多的项目中,比如Apache Jakarta上很著名的另外两个开源项目Cactus和HTMLUnit都使用了HttpClient。
那么这里就简单写写如何获取网页源码:
maven依赖:
<!-- httpclient的依赖 --> <dependency> <groupId>org.apache.httpcomponents</groupId> <artifactId>httpclient</artifactId> <version>4.5.2</version> </dependency>
这里最大的问题就是编码的问题,如果编码不是合适的话,就会出现中文乱码情况。
一般是通过两种方式来获取编码,一种是从响应头获取,一种是从网页源码的meta中获取。
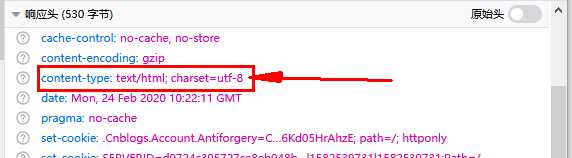

这两种方法要结合使用。一般步骤是先从响应头获取,如果响应头没有,就要到网页源码meta中获取,如果还没有,就要设置默认编码。
我的代码如下:
package httpclient.download; import java.io.BufferedReader; import java.io.ByteArrayOutputStream; import java.io.IOException; import java.io.InputStream; import java.io.StringReader; import java.util.regex.Matcher; import java.util.regex.Pattern; import org.apache.http.HttpEntity; import org.apache.http.client.methods.CloseableHttpResponse; import org.apache.http.client.methods.HttpGet; import org.apache.http.impl.client.CloseableHttpClient; import org.apache.http.impl.client.HttpClients; import org.apache.http.util.EntityUtils; /** * httpclient来下载网页源码。 * * @author 徐金仁 * *关于网页下载最大的问题是编码的问题 * */ public class Download { public String getHtmlSource(String url){ String htmlSource = null; String finallyCharset = null; //使用httpclient下载 //创建一个httpclient的引擎 CloseableHttpClient httpClient = HttpClients.createDefault(); //创建一个httpGet对象,用于发送get请求,如果要发post请求,就创建一个post对象 HttpGet get = new HttpGet(url); try { //发送get请求,获取一个响应 CloseableHttpResponse response= httpClient.execute(get); //获取这次响应的实体,接下来所有的操作都是基于此实体完成, HttpEntity entity = response.getEntity(); //方法还是两个,先从header里面来查看,如果没有,再从meta里面查看 //这个方法主要是从header里面来获取,如果没有,会返回一个null finallyCharset = EntityUtils.getContentCharSet(entity); System.out.println("编码如下:"); System.out.println("charset1 = " + finallyCharset); byte[] byteArray = null; if(finallyCharset == null){ //如果header里面没有,则要从meta里面来获取,为了节约网络资源,网页只读取一次, /* * 那么,就有几个关系 :url->字符流->子节流->字符串 * 这里可以用子节数组来作为中间的过渡,从字节数组这里获取到编码,再通过正确的编码变为字符串 */ byteArray = convertInputStreamToByteArray(entity.getContent()); if(byteArray == null){ throw new Exception("字节数组为空"); } //接下来要从字节数组中获取到meta里面的chatset finallyCharset = getCharsetFromMeta(byteArray); System.out.println("charset2 = " + finallyCharset); if(finallyCharset == null){ //如果没有找到 finallyCharset = "UTF-8"; //则等于默认的 System.out.println("charset3 = " + finallyCharset); } //如果找到了就更好 } System.out.println("charset = " + finallyCharset); htmlSource = new String(byteArray, finallyCharset); }catch (IOException e) { e.printStackTrace(); } catch (Exception e) { e.printStackTrace(); } return htmlSource; } /** * 将一个输入流转化为一个字节数组 * @param content * @param defaultCharset * @return * @throws IOException */ public byte[] convertInputStreamToByteArray(InputStream content) throws IOException { //输入流转化为一个字节数组 byte[] by = new byte[4096]; ByteArrayOutputStream bos = new ByteArrayOutputStream(); int l = -1; while((l = content.read(by)) > 0){ bos.write(by, 0, l); } byte[] s = bos.toByteArray(); return s; } /** * 从字节数组中获取到meta里面的charset的值 * @param byteArray * @return * @throws IOException */ public String getCharsetFromMeta(byte[] byteArray) throws IOException { //将字节数组转化为bufferedReader,从中一行行的读取来,再判断 String htmlSource = new String(byteArray); StringReader in = new StringReader(htmlSource); BufferedReader reader = new BufferedReader(in); String line = null; while((line = reader.readLine()) != null){ line = line.toLowerCase(); if(line.contains("<meta")){ //通过正则表达式来获取网页中的编码 String regex = "\"text/html;[\\s]*?charset=([\\S]*?)\""; Pattern pattern = Pattern.compile(regex); if(pattern != null){ Matcher matcher = pattern.matcher(htmlSource); if(matcher != null){ if(matcher.find()){ return matcher.group(1); } } } }else{ continue; } } return null; } //测试: public static void main(String[] args) { String htmlsource = new Download().getHtmlSource("http://news.youth.cn/gn/"); System.out.println("源码:"); System.out.println(htmlsource); } }
结果:

收藏的相关博客:
https://blog.csdn.net/justry_deng/article/details/81042379
https://blog.csdn.net/w372426096/article/details/82713315
标签:ble creat 区别 buffere ref contain details har nbsp
原文地址:https://www.cnblogs.com/1998xujinren/p/12360758.html