标签:更改 字母 注意 工具 多次 筛选 基础 alt 信息
正则表达式是用于信息筛选的工具,其地位非常重要
#使用格式如下
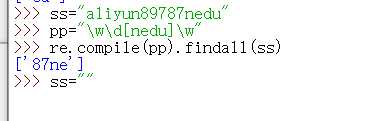
re.compile(正则表达式).findall(源字符串)普通字符——正常匹配
\n——匹配换行符
\t——匹配制表符
\w——匹配字母、数字、下划线(也统称非特殊字符)
\W——匹配除字母、数字、下划线
\d——匹配十进制数字
\D——匹配除十进制数字
\s——匹配空白字符
\S——匹配除空白字符
[sean010]——原子表,匹配sean010中的任意一个字符
[^sean010]——原子表,匹配除sean010中的任意一个字符
案例展示

.——匹配除换行外任意一个字符
^——匹配开始位置
$——匹配结束位置
*——前一个字符出现0\1\多次
?——前一个字符出现0\1次
+——前一个字符出现1\多次
{n}——前一个字符恰好出现n次
{n,}——前一个字符出现至少n次
{n,m}——前一个字符出现至少n次,至多m次
|——模式选择符或
()——模式单元,想要什么内容就写什么
案例展示
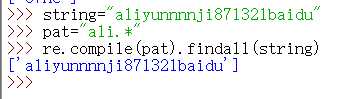
注意上图*默认是贪婪,即尽可能多地匹配
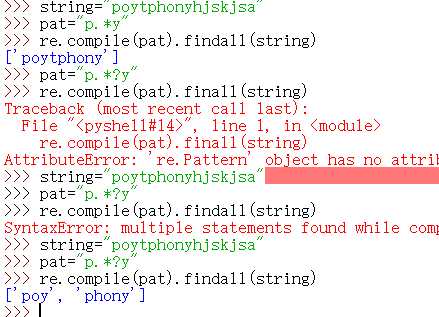
上面一种为贪婪模式,下面一种为懒惰模式。
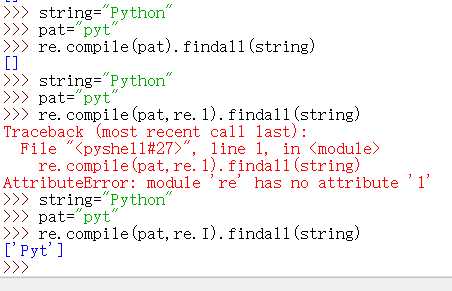
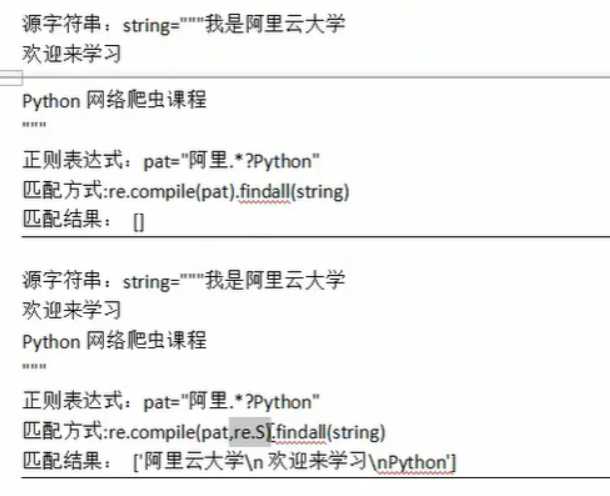
模式修正符:在不改变正则表达式的情况下,通过模式修正符使得匹配结果发生更改
案例展示
标签:更改 字母 注意 工具 多次 筛选 基础 alt 信息
原文地址:https://www.cnblogs.com/seanry/p/12364883.html