标签:生成器 图片 nic 输出 类型 learn 数组 数据显示 利用
1 #!/usr/bin/env python 2 # -*- coding: utf-8 -*- 3 # @File : Iris.py 4 # @Author: 赵路仓 5 # @Date : 2020/2/26 6 # @Desc : 7 # @Contact : 398333404@qq.com 8 9 import numpy as np 10 import matplotlib.pyplot as plt 11 import pandas as pd 12 import mglearn 13 import pandas as pd 14 from sklearn.datasets import load_iris # 鸢尾花(Iris)数据集,这是机器学习和统计学中一个经典的数据集 15 from sklearn.model_selection import train_test_split 16 17 iris_dataset = load_iris() # load_iris 返回的 iris 对象是一个 Bunch 对象,与字典非常相似,里面包含键和值 18 print("Key or iris_dataset:\n{}".format(iris_dataset.keys())) # 打印 19 print(iris_dataset[‘DESCR‘][:193] + "\n...") # DESCR 键对应的值是数据集的简要说明。target_names 键对应的值是一个字符串数组 里面包含我们要预测的花的品种 20 print("Target names: {}".format(iris_dataset[‘target_names‘])) # 三种花的名字类型 21 print("Feature names: {}".format(iris_dataset[‘feature_names‘])) # 三种花的特征,花瓣的长度 宽度 及 花萼的长度 宽度 22 print("Type of data: {}".format(type(iris_dataset[‘data‘]))) # data 数组的每一行对应一朵花,列代表每朵花的四个测量数据 23 print("Shape of data: {}".format(iris_dataset[‘data‘].shape)) # 数组中包含 150 朵不同的花的测量数据 24 print("First five rows of data:\n{}".format(iris_dataset[‘data‘][:5])) # 前五朵花的数据 25 print("Type of target: {}".format(type(iris_dataset[‘target‘]))) # 是一个一维数组,每朵花对应其中的一个数据 26 print("Shape of target: {}".format(iris_dataset[‘target‘].shape)) # 27 print("Target:\n{}".format(iris_dataset[‘target‘])) # 品种转为0 1 2三个整数,代表三个种类 28 29 X_train, X_test, Y_train, Y_test = train_test_split(iris_dataset[‘data‘], iris_dataset[‘target‘], random_state=0) 30 print("X_train shape:{}".format(X_train.shape)) 31 print("Y_train shape:{}".format(Y_train.shape)) 32 print("X_test shape:{}".format(X_test.shape)) 33 print("Y_test shape:{}".format(Y_test.shape)) 34 35 # 利用X_train的数据创建DataFrame 36 # 利用iris_dataset.feature_names的字符对数据进行标记 37 iris_dataframe=pd.DataFrame(X_train,columns=iris_dataset.feature_names) # 横坐标 以及横坐标名称 38 # 利用DataFrame创建散点图矩阵,按y_trian着色 39 grr=pd.plotting.scatter_matrix(iris_dataframe, c=Y_train, figsize=(15, 15), marker=‘o‘,hist_kwds={‘bins‘: 20}, s=60, alpha=.8, cmap=mglearn.cm3) 40 plt.show()
注:其中data数组的每一行代表一朵花,列代表每朵花的四个测量数据,一共150朵不同的花。而target是一个一维数组,每朵花代表其中的以个数据,用0、1、2三个整数代表三个不同的花品种。
首先,不能用构建模型的数据用于评估模型,因为模型是适配构建模型数据的,若用来测试匹配必定是100%。因此,要用新数据来测试模型。
X_train, X_test, Y_train, Y_test = train_test_split(iris_dataset[‘data‘], iris_dataset[‘target‘], random_state=0) print("X_train shape:{}".format(X_train.shape)) print("Y_train shape:{}".format(Y_train.shape)) print("X_test shape:{}".format(X_test.shape)) print("Y_test shape:{}".format(Y_test.shape))
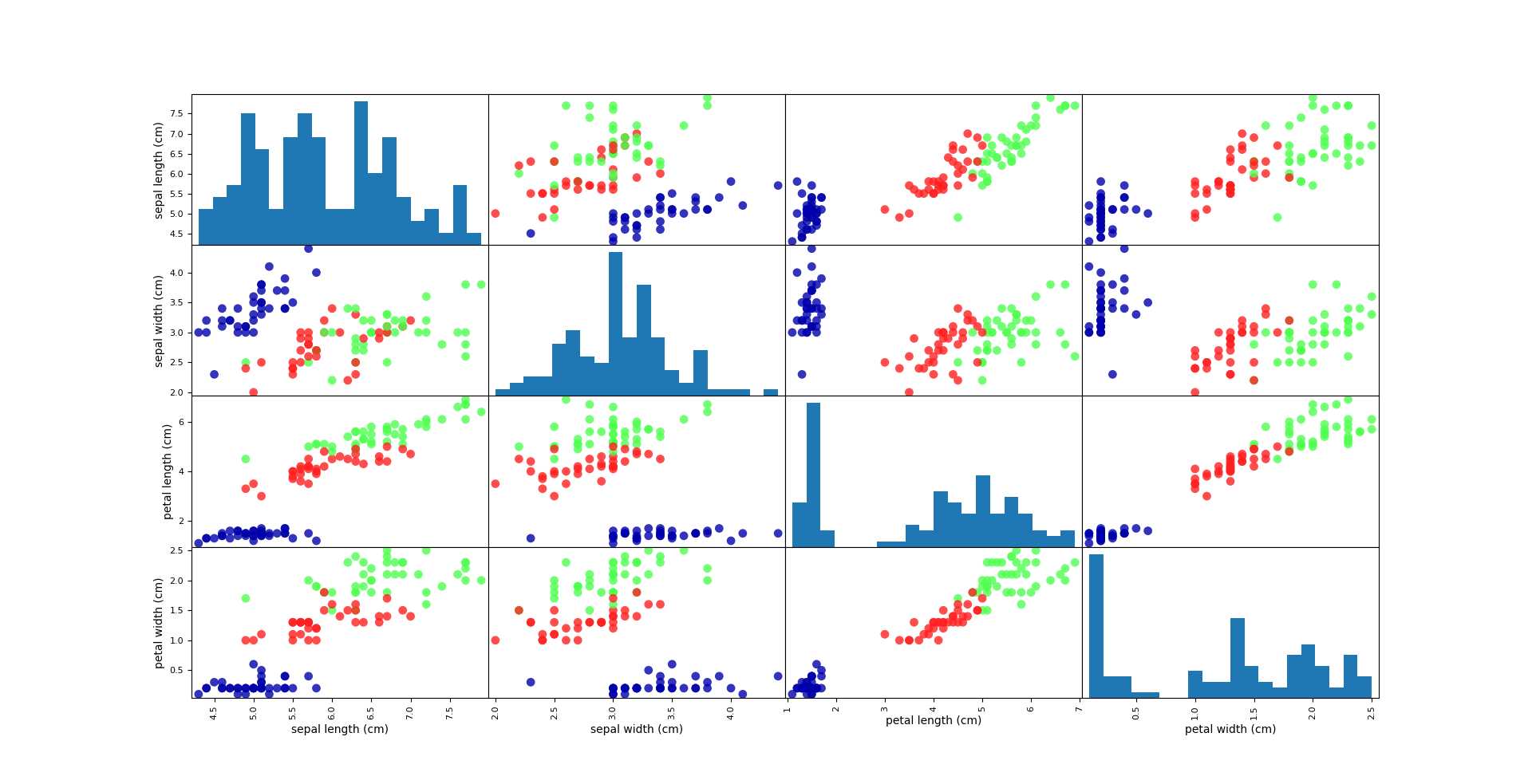
1 # 利用X_train的数据创建DataFrame 2 # 利用iris_dataset.feature_names的字符对数据进行标记 3 iris_dataframe=pd.DataFrame(X_train,columns=iris_dataset.feature_names) # 横坐标 以及横坐标名称 4 # 利用DataFrame创建散点图矩阵,按y_trian着色 5 grr=pd.plotting.scatter_matrix(iris_dataframe, c=Y_train, figsize=(15, 15), marker=‘o‘,hist_kwds={‘bins‘: 20}, s=60, alpha=.8, cmap=mglearn.cm3) 6 plt.show()
数据显示结果:
标签:生成器 图片 nic 输出 类型 learn 数组 数据显示 利用
原文地址:https://www.cnblogs.com/zlc364624/p/12369979.html