标签:new t idea lock 最大值 内部类 dex 就是 字体 总结
在我们平时自己写线程的测试demo时,一般都是用new Thread的方式来创建线程。但是,我们知道创建线程对象,就会在内存中开辟空间,而线程中的任务执行完毕之后,就会销毁。
单个线程的话还好,如果线程的并发数量上来之后,就会频繁的创建和销毁对象。这样,势必会消耗大量的系统资源,进而影响执行效率。
所以,线程池就应运而生。
可以通过idea先看下线程池的类图,了解一下它的继承关系和大概结构。
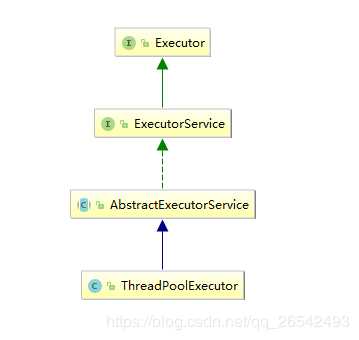
它继承自AbstractExecutorService类,这是一个抽象类,不过里边的方法都是已经实现好的。然后这个类实现了ExecutorService接口,里边声明了各种方法,包括关闭线程池,以及线程池是否已经终止等。此接口继承自父接口Executor,里边只声明了一个execute方法。
线程池就是为了解决单个线程频繁的创建和销毁带来的性能开销。同时,可以帮我们自动管理线程。并且不需要每次执行新任务都去创建新的线程,而是重复利用已有的线程,大大提高任务执行效率。
我们打开 ThreadPoolExecutor的源码,可以看到总共有四个构造函数。
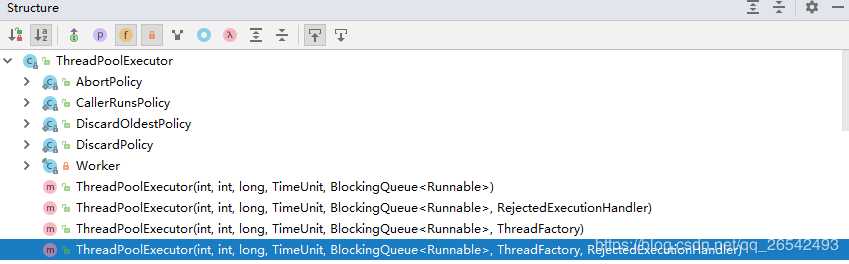
但是,前三个最终都会调用到最后一个构造函数。我们来看下这个构造函数都有哪些参数。(其实,多看下参数的英文解释就能明白其中的含义,看来英语对程序员来说是真的重要呀)
//核心构造函数
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
}1)corePoolSize
代表核心线程数。每当新的任务提交过来的时候,线程池就会创建一个核心线程来执行这个任务,即使已经有其他的核心线程处于空闲状态。 而当需要执行的任务数大于核心线程数时,将不再创建新的核心线程。
其实,我们可以看下JDK提供的官方注释说明。even if they are idle,就照应上边的加粗字体。

此外,最后一句话说,除非allowCoreThreadTimeOut 这个参数被设置了值。

什么意思呢,可以去看下这个参数默认值是false,代表当核心线程在空闲状态时,即没有任务在执行,就会一直存活,不会销毁。而设置为true之后,就会有线程存活时间,即假如设置存活时间60秒,则60秒之后,如果没有新的可执行任务,则核心线程也会自动销毁。
2)maximumPoolSize
线程所允许的最大数量。即,当阻塞队列已满的时候,并且已经创建的线程数小于最大线程数,则会创建新的线程去执行任务。所以,这个参数只有在阻塞队列满的情况下才有意义。因此,对于无界队列,这个参数将会失去效果。
3)keepAliveTime
代表线程空闲后,保持存活的时间。也就是说,超过一定的时间没有任务执行,线程就会自动销毁。
注意,这个参数,是针对大于核心线程数,小于最大线程数的那部分非核心线程来说的。如果是任务数量特别多的情况下,可以适当增加这个参数值的大小。以保证,在下个任务到来之前,此线程不会立即销毁,从而避免线程的重新创建。
4)unit
这个是描述存活时间的时间单位。可以使用TimeUnit里边的枚举值。
5)workQueue
代表阻塞队列,存储所有等待执行的任务。
6)threadFactory
代表用来创建线程的工厂。可以自定义一个工厂,传参进来。如果不指定的话,就会使用默认工厂(Executors类里边的 DefaultThreadFactory)。

可以看到,会给每个线程的名字指定一个有规律的前缀。并且每个线程都设置相同的优先级(优先级总共有三个,1、5、10)。优先级可以理解为,优先级高的线程被执行的概率会更高,但是不代表优先级高的线程一定会先执行。
7)handler
这个参数代表,拒绝策略。当阻塞队列和线程池都满了,即达到了最大线程数,会用什么策略来处理。一共有四种策略可供选择,分别对应四个内部类。
总结一下线程池的执行过程。
我们一般用 execute 方法来提交任务给线程池。当线程需要返回值时,可以使用submit 方法。
shutdown方法用来关闭线程池。注意,此时不再接受新提交的任务,但是,会继续处理正在运行的任务和阻塞队列里边的任务。
shutdownNow也会关闭线程池。但是,它不再接受新任务,并且会尝试终止正在运行的任务。
了解了线程池工作流程之后,那么我们怎样去创建它呢。
Executors类提供了四种常用的方法。可以发现它们最终都调用了线程池的构造方法。都有两种创建方式,其中一种可以传自定义的线程工厂。此处,只贴出不带工厂的方法便于理解。
①newFixedThreadPool
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}创建一个固定大小的线程池。核心线程数和最大线程数相等。当线程数量达到核心线程数时,新任务就会放到阻塞队列里边等待执行。
②newSingleThreadExecutor
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
}创建一个核心线程数和最大线程数都是1的线程池。即线程池中只会存在一个正在执行的线程,若线程空闲则执行,否则把任务放到阻塞队列。
③ newCachedThreadPool
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}创建一个可根据实际情况调整线程个数的线程池。这句话,可以理解为,有多少任务同时进来,就会创建同等数量的线程去执行任务。当然,这是在线程数不能超过Integer最大值的前提下。
当再来一个新任务时,若有空闲线程则执行任务。否则,等线程空闲60秒之后,就会自动回收。
当没有新任务,就不会创建新的线程。
④newScheduledThreadPool
public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize) {
return new ScheduledThreadPoolExecutor(corePoolSize);
}
public ScheduledThreadPoolExecutor(int corePoolSize) {
super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS,
new DelayedWorkQueue());
}创建一个可指定核心线程数的线程池。这个线程池可以执行周期性的任务。
如果本文对你有用,欢迎点赞,评论,转发。
学习是枯燥的,也是有趣的。我是「烟雨星空」,欢迎关注,可第一时间接收文章推送。
标签:new t idea lock 最大值 内部类 dex 就是 字体 总结
原文地址:https://www.cnblogs.com/starry-skys/p/12375166.html