标签:应用 关系 过滤 有一个 一个 两种 展示 neu 框架
题目:SCA-CNN: Spatial and Channel-wise Attention in Convolutional Networks for Image Captioning
作者: Long Chen等(浙大、新国立、山大)
期刊:CVPR 2017
注意力机制已经在自然语言处理和计算机视觉领域取得了很大成功,但是大多数现有的基于注意力的模型只考虑了空间特征,即那些注意模型考虑特征图像中的局部更“重要”的信息,忽略了多通道信息的重要性关系。这篇文章介绍了一种新型的卷积神经网络——SCA-CNN,它融合了空间和信道的关注。
本文提出的方法针对图像和文字的匹配问题(neural image/video captioning (NIC))和视觉问答(visual question answering (VQA))。图1说明了在多层特征图中引入通道注意力机制的动机。首先,由于通道方向的特征映射本质上是对应滤波器的检测器响应映射,因此通道方向的保持可以看作是根据句子上下文的需求选择语义属性的过程。例如,当我们要预测蛋糕的时候,我们的通道会更关注根据蛋糕、火、光和蜡烛的语义,在过滤器生成的通道方向的特征图。
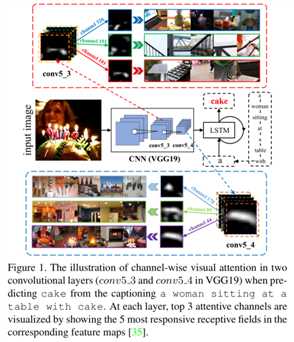
概述:
网络采用编码-解码框架生成图像标题,如图2所示,SCA-CNN通过多层面的信道注意和空间注意,赋予了原CNN多层地物图对句子上下文的自适应能力。
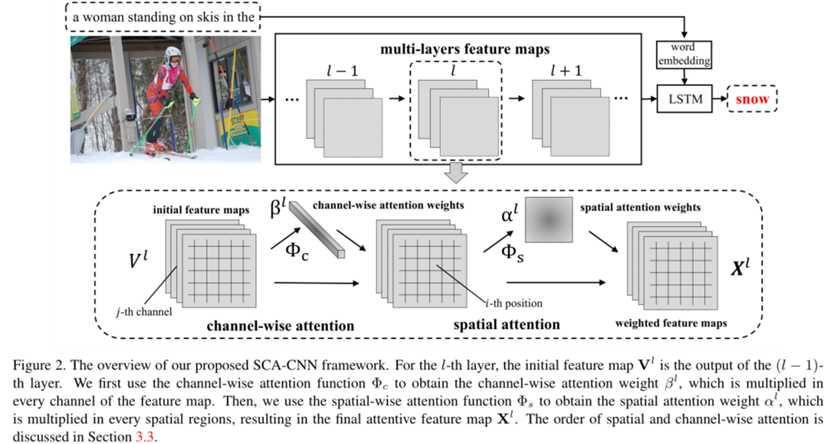
空间注意(Spatial Attention):
一般来说,一个词只与图片的一小部分有关,空间注意机制试图将注意力更多地放在语义相关区域,而不是平均考虑每个图像区域。对于第l层特征图V = [v1, v2,…,v m], v∈RC×m,其中m为图像被划分的区域数,C为信道数,因此vi∈RC是第i个位置的视觉特征。空间注意力分布因子α如下:

通道注意力(Channel-wise Attention):
对每个通道应用空间均值池化,得到通道特征v:
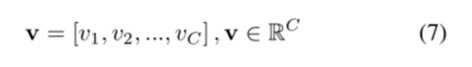
通道注意力因子β:

框架结构1 通道-空间:
如图2所示,现在通道特征上应用注意力机制,然后再空间特征上应用。
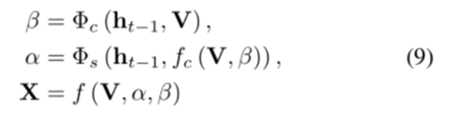
其中fc()为特征映射通道与对应通道权值的乘机。
框架结构2 空间-通道:
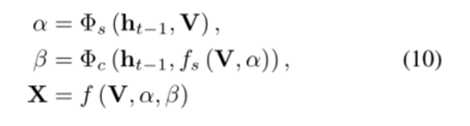
框架结构3 空间、通道集成到一个结构:
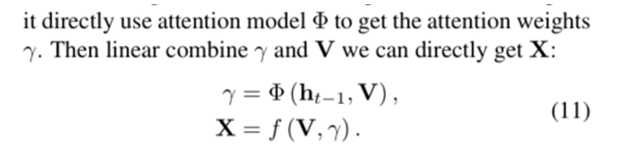
每个标量特征都有一个概率权重,可以显著增加特征表示的变化量,但是计算量大。
对通道注意力机制的评估:
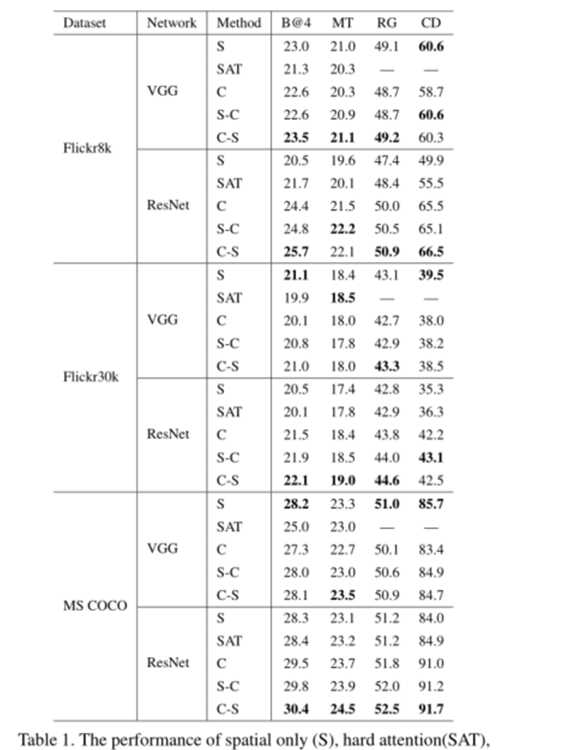
根据表1,我们得出以下结论:1)使用VGG-19,S比SAT好;使用ResNet-152,SAT性能要优于S。这是因为VGG-19网络具有完全连接的层,可以保留空间信息,但是,ResNet-152最初是平均池化的,因此无法保存空间信息。 2)比较C ans S的性能,ResNet-152可以比VGG-19网络显着改善C性能,这表明更多的通道数可以提高通道的注意性能,因为ResNet-152比VGG-19具有更多的通道数。 3)在VGG-19和ResNet-152中,S-C和S-C的性能非常相似。通常,C-S比S-C稍好一些,这可能是由于通道方向的特征更加关注。 4)在ResNet-152中,C-S或S-C可以明显改善S的性能。这表明,通过增加按通道注意,可以在通道数量较大时显着提高性能。
多层注意力机制评价:
另外实验证明,通过在两个模型(S和C-S)中添加层可以获得更好的结果,这是因为多层注意有助于获得对多种语义抽象的视觉关注,但是添加的层数过多会引起过拟合的问题。
从表4和表5的结果可以看出,在大多数情况下,SCA-CNN都优于其他两种模型(数据集:MS COCO Image Challenge set)。
与当前较好的结果的比较:
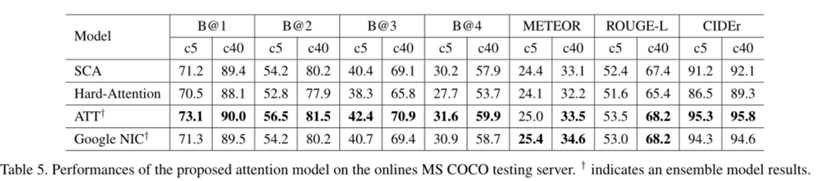
我们可以看到,在大多数情况下,SCA-CNN优于其他模型。 这是由于SCA-CNN利用空间,通道和多层注意力,而大多数注意力模型仅关注一种注意力类型。这是因为SCA-CNN利用了空间、频道和多层的注意力,而大多数注意力模型只关注一种注意力类型。请注意,我们不能超越ATT和谷歌NIC的原因是他们声称使用集成模型。然而,作为一个单一的模型,SCA-CNN仍然可以达到与集成模型相比较的结果。
相关结果展示:

提出了一种新的注意力结构,称为SCA-CNN。SCA-CNN充分考虑了CNN的特点,并将其转化为细致的图像特征:空间性、频道性和多层性,实现了跨越流行基准的最新性能。
SCA-CNN: Spatial and Channel-wise Attention in Convolutional Networks for Image Captioning
标签:应用 关系 过滤 有一个 一个 两种 展示 neu 框架
原文地址:https://www.cnblogs.com/zzm96/p/12376681.html