标签:validate static rip 错误 sig 字符串 ima ip地址 传值
本篇参考微信官方文档:https://developers.weixin.qq.com/doc/offiaccount/Basic_Information/Access_Overview.html
随着salesforce学习文章越来越多,查找文章也变得越来越不方便。去年有个关注的粉丝私下微信聊天,问是否可以在微信公众号做一个搜索功能,通过关键字返回匹配的文章,这样可以减少了一直拖拽耽误的时间和精力。去年一直懒惰没有实现,其实也是没有接触过微信公众号集成,所以简单的推脱了,说后续会搞定这个功能。今年因为疫情憋在家里正好有机会去进行学习,顺便就简单的学了一下公众号集成以及相关的简单开发,然后将这个功能实现。此功能实现主要通过两个大步骤。
一. 启用微信公众号服务器配置
根据官方文档的描述,接入微信公众平台开发,开发者需要按照如下步骤完成:
我们需要先搞定前两步,微信在验证服务器地址的有效性时,会发送几个parameter,然后按照字典化排序以及SHA1加密来判断signature比较,因为我们可以使用oauth认证或者不认证方式,这里我们通过salesforce site方式,这样可以忽略了认证,通过restful接口去接受微信服务器发送过来的验证消息,从而最简单化集成微信。

1. restful接口来接收微信服务器传参以及验证:验证的原理时根据传递的几个参数字典排序然后SHA1加密,然后将结果和微信传过来的signature比对是否相同,相同代表验证通过,并且将标识传递回微信即可。代码部分如下,其中myToken部分为微信公众号要求验证的token,每个人不同,按需修改。
@RestResource(urlMapping=‘/WeChatRest/*‘) global without sharing class WeChatRestController { @HttpGet global static void validateSignature() { //获取微信端传递的参数 String signature = RestContext.request.params.get(‘signature‘); // 微信加密签名 String timestamp = RestContext.request.params.get(‘timestamp‘); // 微信请求URL时传过来的timestamp值 String nonce = RestContext.request.params.get(‘nonce‘); // 随机数-->微信请求URL时传过来的nonce值 String echostr = RestContext.request.params.get(‘echostr‘); // 随机字符串 // 转换规则详情:https://developers.weixin.qq.com/doc/offiaccount/Basic_Information/Access_Overview.html //1. 字典排序 String myToken = ‘zhangyq‘; List<String> paramList = new List<String>{myToken,timestamp,nonce}; paramList.sort(); String content = ‘‘; for(String param : paramList) { content += param; } // 2. sha1算法转换 Blob hash = Crypto.generateDigest(‘SHA1‘, Blob.valueOf(content)); String hexString= EncodingUtil.convertToHex(hash); //3. 比对转换后的值是否和传递的echostr相同,相同证明认证通过 Boolean isValid = hexString != null ? signature.equalsIgnoreCase(hexString) : false; if(isValid) { RestContext.response.addHeader(‘Content-Type‘, ‘text/plain‘); RestContext.response.responseBody = Blob.valueOf(echostr); } } }
2. 创建site,在Set Up处搜索sites以后新建一个site,最后别忘记active。
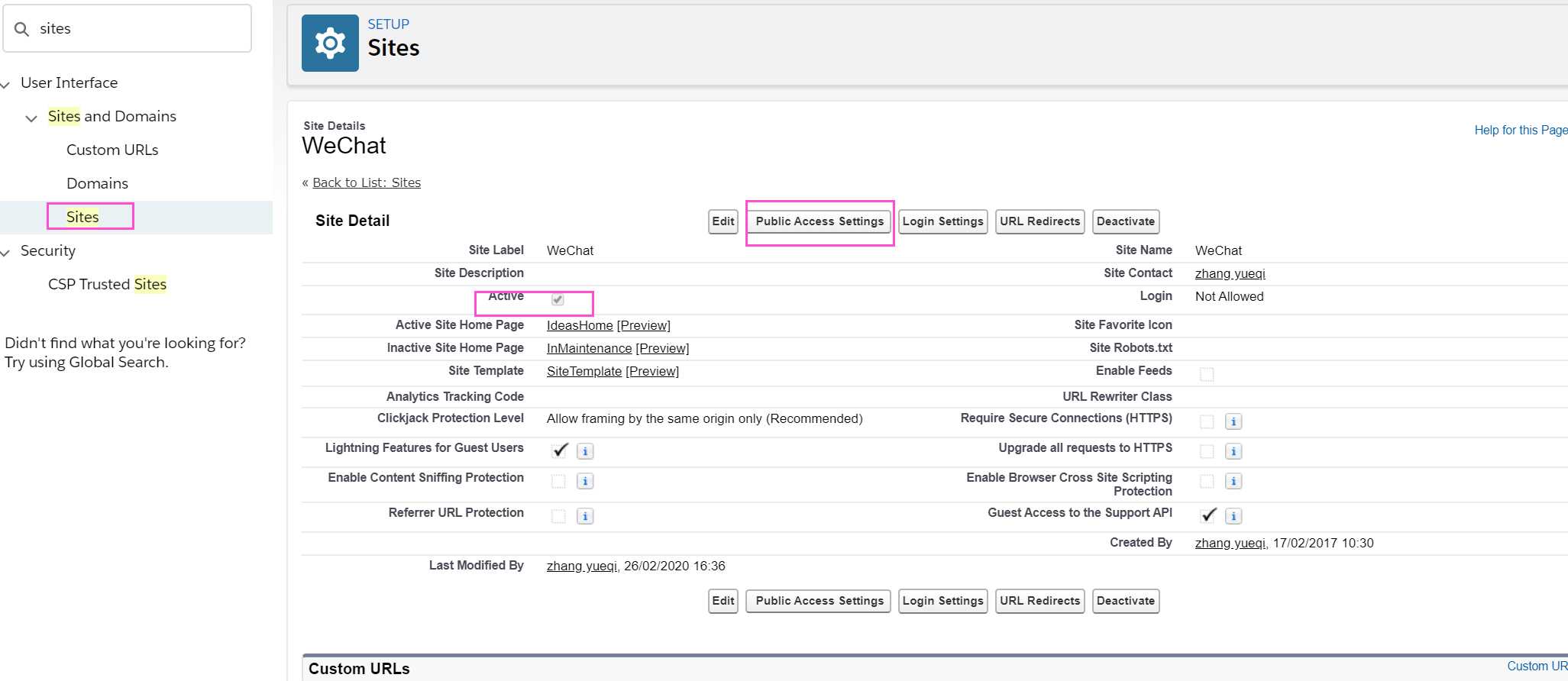
记住划线的URL,后期需要使用这个配置到微信端。

save以后点击来这个site,点击Public Access Settings,然后Apex Class Access,在Enabled Apex class将WeChatRestController选中。

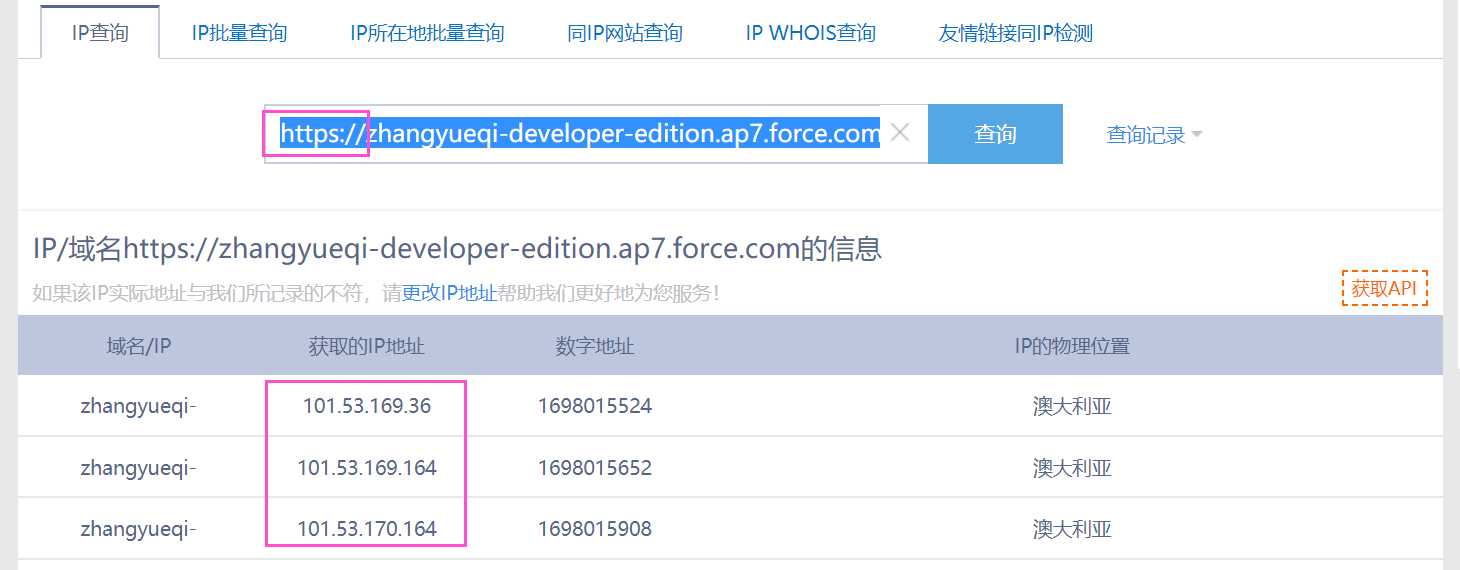
3. 配置微信端:在公众号的下方有一处是开发-》基本配置,点击此项以后有开发者ID,开发者密码,IP白名单。启用开发者馍是,然后记住开发者密码,这个密码只会出现一次,后期就只能重置,类似salesforce的 reset security token的效果,所以务必记住。在白名单处我们可以配置一些白名单,比如我们可以将上述的URL找到其对应的IP地址,然后配置在白名单中,想要找到域名对应的IP可以访问:http://ip.tool.chinaz.com/,这里搜索使用site的配置的链接,改成https://用来查询。
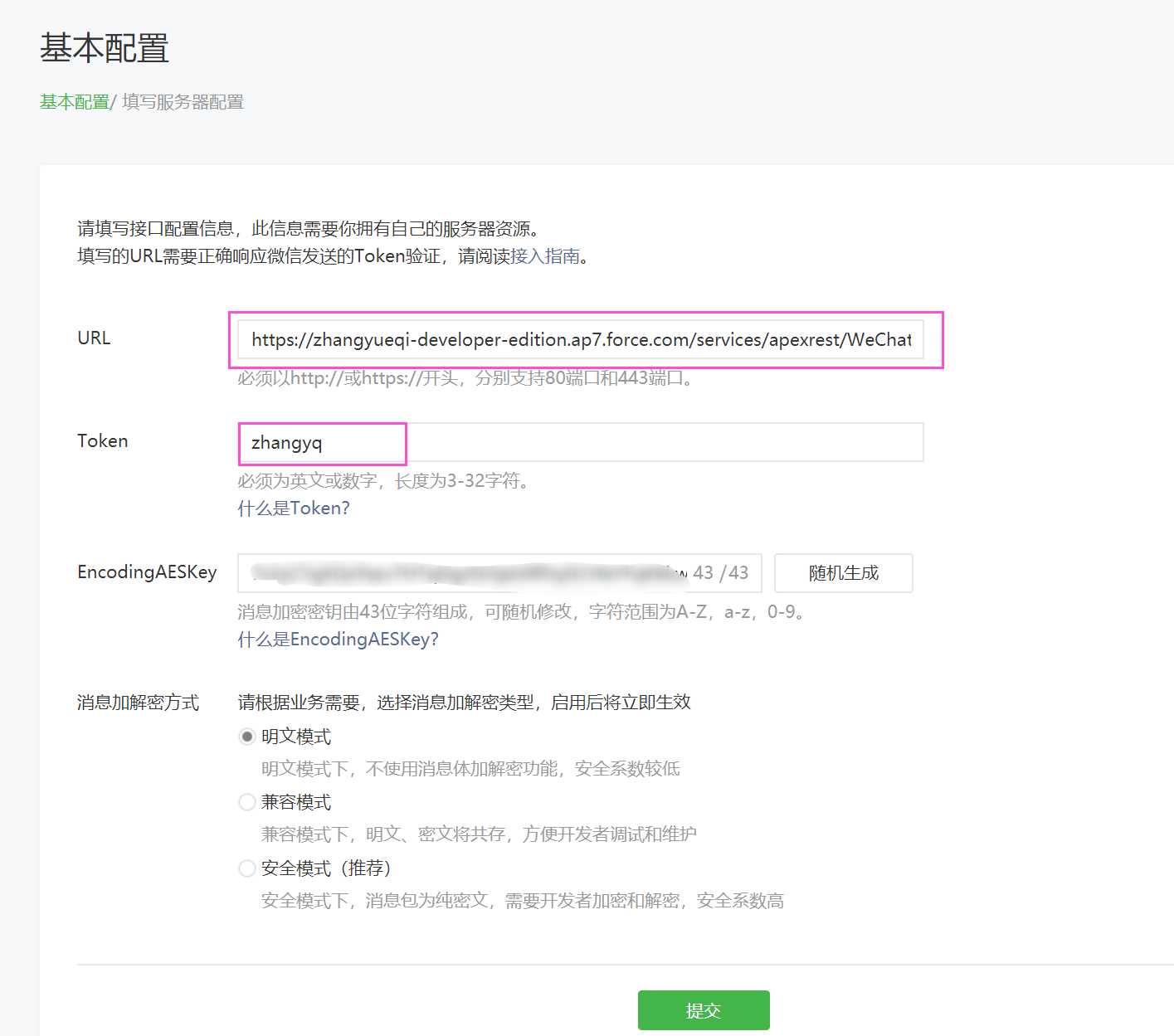
打开开发者模式以后就可以配置服务器信息,通过下图可以看到,URL配置的是site对应的URL后面拼接的是rest的访问地址,token为我们在代码中写的值,点击提交如果没有报错则配置成功。
二. 解析微信传值并回传给微信
https://developers.weixin.qq.com/doc/offiaccount/Message_Management/Receiving_standard_messages.html 这个是官方文档关于消息机制的阐明。当配置完服务器以后,用户在公众号里面输入的内容,微信不再做解析和处理,将消息通过post方式传递到配置的服务器URL,所以我们想要解析和处理,需要在刚才的类中添加一个@HttpPost方法来接收和处理数据。
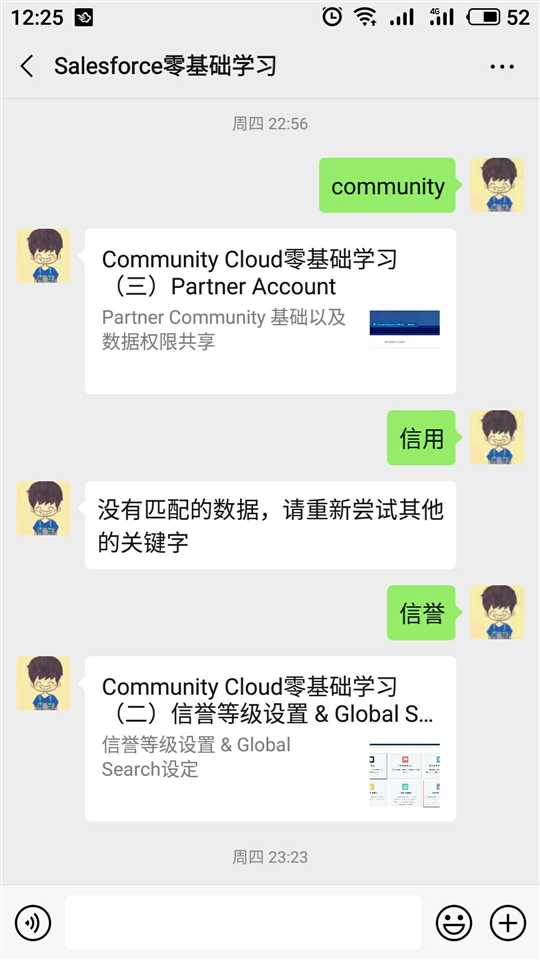
本来想做的效果类似下面的展示,结果开发完以后测试以后只能返回一条图文,查看文档以后才知道一个文字类型的消息只能返回一个图文消息,所以大家开发以前一定要详细读文档,避免走弯路。
微信发送过来以及后期需要接受的数据格式是XML类型,意味着我们在开发时,对数据解析和处理都需要有一定的XML的解析基础,不知道XML如何解析的,请访问此篇博客:https://www.cnblogs.com/zero-zyq/p/5601158.html, 发送和接受类型请自行查看上面提供的链接,这里不做处理。直接上代码:
RequestMessage:用于封装微信传递过来的信息,微信根据不同的类型会有不同的参数传递,这里只封装我们用到的文本类型内容的变量进行封装。
public with sharing class RequestMessage { public String toUserName; public String fromUserName; public String msgType; public String content; public RequestMessage(String toUserName,String fromUserName,String msgType,String content) { this.toUserName = toUserName; this.fromUserName = fromUserName; this.msgType = msgType; this.content = content; } }
ResponseMessage:因为response部分需要返回多条,无法选择图文方式,所以这里使用文本链接方式发送回到微信,所以我们只需要封装title以及URL即可。
public with sharing class ResponseMessage { public String title; public String url; public ResponseMessage(String title,String url) { this.title = title; this.url = url; } }
最后完整的WeChatRestController代码如下,对post内容解析,使用SOSL搜索我们自定义的存储数据的My_Blog__c,然后对结果进行封装后扔回给微信,目前只支持文本方式,其他类型会有提示。目前最多只返回5条数据。
@RestResource(urlMapping=‘/WeChatRest/*‘) global without sharing class WeChatRestController { @HttpGet global static void validateSignature() { //获取微信端传递的参数 String signature = RestContext.request.params.get(‘signature‘); // 微信加密签名 String timestamp = RestContext.request.params.get(‘timestamp‘); // 微信请求URL时传过来的timestamp值 String nonce = RestContext.request.params.get(‘nonce‘); // 随机数-->微信请求URL时传过来的nonce值 String echostr = RestContext.request.params.get(‘echostr‘); // 随机字符串 // 转换规则详情:https://developers.weixin.qq.com/doc/offiaccount/Basic_Information/Access_Overview.html //1. 字典排序 String myToken = ‘zhangyq‘; List<String> paramList = new List<String>{myToken,timestamp,nonce}; paramList.sort(); String content = ‘‘; for(String param : paramList) { content += param; } // 2. sha1算法转换 Blob hash = Crypto.generateDigest(‘SHA1‘, Blob.valueOf(content)); String hexString= EncodingUtil.convertToHex(hash); //3. 比对转换后的值是否和传递的echostr相同,相同证明认证通过 Boolean isValid = hexString != null ? signature.equalsIgnoreCase(hexString) : false; if(isValid) { RestContext.response.addHeader(‘Content-Type‘, ‘text/plain‘); RestContext.response.responseBody = Blob.valueOf(echostr); } } @HttpPost global static void doPost() { RestRequest req = RestContext.request; RestResponse res = RestContext.response; string strMsg = req.requestBody.toString(); system.debug(‘*** message from wechat : ‘ + strMsg); XmlStreamReader reader = new XmlStreamReader(strMsg); String toUserName = ‘‘; String fromUserName = ‘‘; String msgType = ‘‘; String content = ‘‘; //解析微信传递过来的XML,将主要的内容的值取出来并进行操作 while(reader.hasNext()) { if(reader.getLocalName() == ‘ToUserName‘) { reader.next(); if(String.isNotBlank(reader.getText())) { toUserName = reader.getText(); } } else if(reader.getLocalName() == ‘FromUserName‘) { reader.next(); if(String.isNotBlank(reader.getText())) { fromUserName = reader.getText(); } } else if(reader.getLocalName() == ‘MsgType‘) { reader.next(); if(String.isNotBlank(reader.getText())) { msgType = reader.getText(); } } else if(reader.getLocalName() == ‘Content‘) { reader.next(); if(String.isNotBlank(reader.getText())) { content = reader.getText(); } } reader.next(); } //封装到request bean中用于获取传递过来的关键字的值 RequestMessage receiveMsg = new RequestMessage(toUserName,fromUserName,msgType,content); //返回到微信的XML格式类型的字符串 String resultXML; //根据输入类型进行处理,目前公众号只支持文本类型 if(msgType.equals(‘text‘)){ resultXML = buildResponseXMLByContent(receiveMsg); } else { resultXML = buildResponseXML(receiveMsg,null); } RestContext.response.addHeader(‘Content-Type‘, ‘text/plain‘); RestContext.response.responseBody = Blob.valueOf(resultXML); } private static String buildResponseXMLByContent(RequestMessage message) { //用于作为XML拼装的返回结果 String buildXMLString; //通过SOSL根据关键字进行搜索,最多返回5条 String keyword = ‘\‘‘ + message.content + ‘\‘‘; String soslString = ‘FIND‘ + keyword + ‘IN ALL FIELDS ‘ + ‘ RETURNING ‘ + ‘ My_Blog__c(Title__c,Blog_URL__c,Picture_URL__c,Description__c) LIMIT 5‘; List<List<SObject>> soslResultList = search.query(soslString); //对搜索出来的结果集进行封装,然后加工处理XML作为微信返回内容 List<ResponseMessage> responseMessageList = new List<ResponseMessage>(); List<My_Blog__c> myBlogList = new List<My_Blog__c>(); if(soslResultList.size() > 0) { myBlogList = (List<My_Blog__c>)soslResultList.get(0); } for(My_Blog__c myBlog : myBlogList) { ResponseMessage messageItem = new ResponseMessage(myBlog.Title__c,myBlog.Blog_URL__c); responseMessageList.add(messageItem); } buildXMLString = buildResponseXML(message, responseMessageList); System.debug(LoggingLevel.INFO, ‘*** buildXMLString: ‘ + buildXMLString); return buildXMLString; } private static String buildResponseXML(RequestMessage message,List<ResponseMessage> responseMessageList) { String newsTpl = ‘<item><Title><![CDATA[{0}]]></Title><Description><![CDATA[{1}]]></Description><PicUrl><![CDATA[{2}]]></PicUrl><Url><![CDATA[{3}]]></Url></item>‘; String currentDateTime = System.now().format(‘YYYY-MM-dd HH:mm:ss‘); //根据微信公众号规则拼装XML模板 String responseMessageTemplate = ‘<xml><ToUserName><![CDATA[{0}]]></ToUserName><FromUserName><![CDATA[{1}]]></FromUserName><CreateTime>‘ + currentDateTime + ‘</CreateTime><MsgType><![CDATA[text]]></MsgType>‘ + ‘<Content><![CDATA[{2}]]></Content>‘ +‘</xml>‘; //XML模板中对应的Placeholder的值 String[] arguments; //非文本输入提示 if(!message.msgType.equalsIgnoreCase(‘text‘)) { arguments = new String[]{message.fromUserName, message.toUserName, ‘该公众号目前支支持文字输入‘}; } else { //没有搜索出记录提示 if(responseMessageList.isEmpty()) { arguments = new String[]{message.fromUserName, message.toUserName, ‘没有匹配的数据,请重新尝试其他的关键字‘}; } else { String messageStringBuffer = ‘‘; for(ResponseMessage responseItem : responseMessageList) { messageStringBuffer += ‘<a href="‘ + responseItem.url + ‘">‘ + responseItem.title + ‘"></a>\n‘; } messageStringBuffer = messageStringBuffer.removeEnd(‘\n‘); arguments = new String[]{message.fromUserName, message.toUserName, messageStringBuffer}; } } String results = String.format(responseMessageTemplate, arguments); return results; } }
效果展示:
当使用非文本类型在公众号进行搜索,比如语音,会提示“该公众号目前只支持文字输入”;当输入可以查询到的内容,会以文字的方式返回,点击链接即可进入对应的文章;如果输入的内容在数据库中查询不到,则返回“没有匹配的数据”。
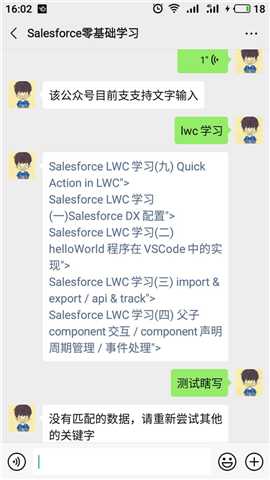
总结:篇中只是以简单的方式对代码进行开发实现微信和salesforce的集成。篇中有错误的地方欢迎指出,有不懂的欢迎留言。
标签:validate static rip 错误 sig 字符串 ima ip地址 传值
原文地址:https://www.cnblogs.com/zero-zyq/p/12382156.html