SingleShotMultiBoxDetector(SSD,单步多框目标检测)
————————————————————————————————————————————————
前言:哈哈,有多少人被标题引诱来的?不过我确实把料下足了,想彻底了解SSD理论的朋友,请你沉下心来看,估计底子好的人要看半小时到一小时左右。这篇随笔,我写了三个小时多,SSD本身结构不复杂,奈何涉及的细节与知识范围有些多,这篇随笔的全部内容对于SSD来说,都缺之不可,耐心通读本篇,SSD的原理,你就能完全掌握了,写的我累死了。。。SSD效果与YOLO V3只是略逊一点点,但是结构很简单明了
开篇简短概括SSD的特点:
•One-Stage
•均匀的密集抽样
•Priorboxes/Defaultboxes(Anchorboxes)
•不同尺度抽样•不同scale尺度的特征图抽样
•对于小目标检测效果不错
•预测速度快
•训练困难(正负样本极度不均衡)
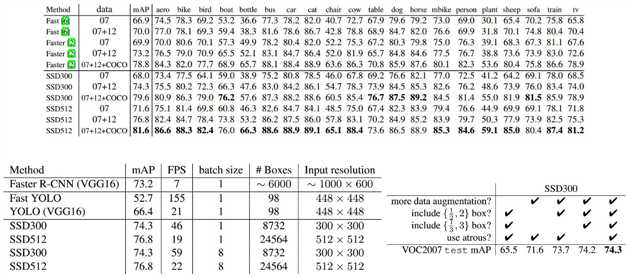
下图为一些网络结构的效率对比图,坦率来说,map达到75%到80%就可以了
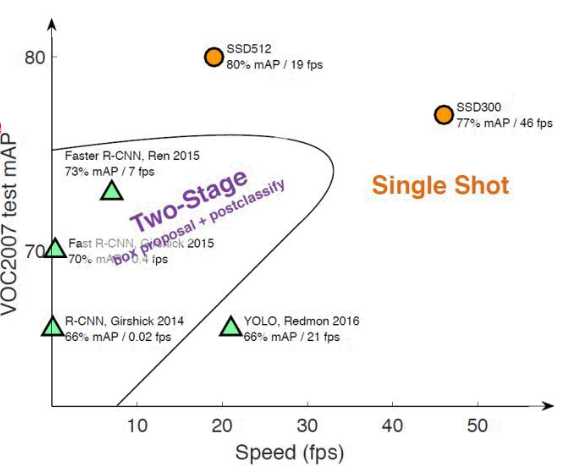
来看一下和其他的算法的对比图:
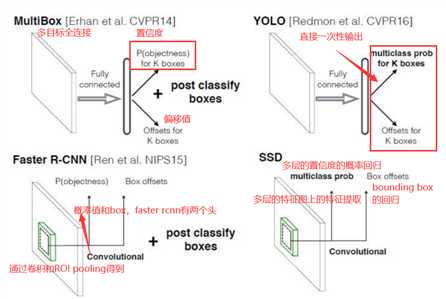
其主干网络为做了一些改动的VGG net
下图为SSD的详细结构图:
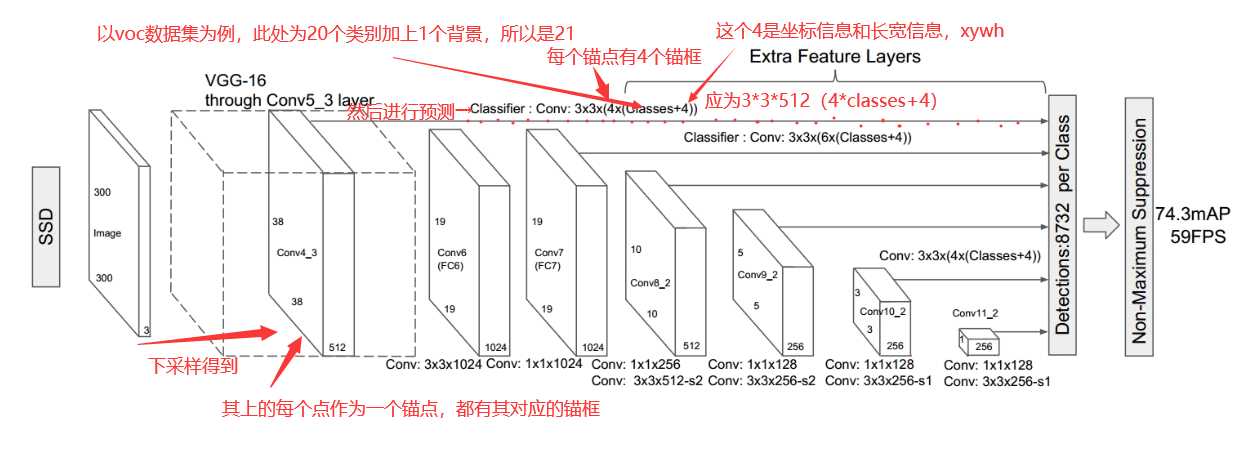
上图补充说明:第一张特
征图进行预测后,大小不变还是38*38,深度变成了(4*classes+4),即100,这上面的每一个1*1*100,对应的是一个锚点的预测值。在深度上来说,每25个深度对应的是一个锚点框,继续分解,那么这25个深度,前20个深度是预测属于某一个类别的概率,第21个是预测为背景的概率,后面4个深度是其坐标信息和宽高的预测,即xywh。
然后继续用3*3*1024的卷积核下采样得到conv6,原来是fc6层,这一层没有做预测的操作。
然后用1*1*1024的卷积核卷了一下,形状依然是19*19*1024的特征图,然后现在是19*19个锚点,此时每个点设置的是有6个锚点框
后面如图同样的步骤。箭头上没有写卷积方式的都是同上一条箭头的卷积方式
如图,一共有6张不同尺度的特征图进行预测得到预测值,一共6层,原图映射到38*38大小,19*19大小.....,然后去跟它们各层的锚框去计算重合不重合(GIOU或者IOU),大于0.5的判断为正例,小于0.5的判断为负例。
上面总结好了,下面来分析一下它的特点:
一,重用了faster rcnn的锚点框机制。
在featuremap上提取各种不同尺度大小的defaultbox,也就是类似Anchor的一系列大小固定的框。不同featuremap上尺度是一样的。
二,为什么要这样多尺度特征图预测?
因为小物体在感受野小的大特征图上容易检测目标,反之,小的特征图,它的感受野大,检测大物体有利。
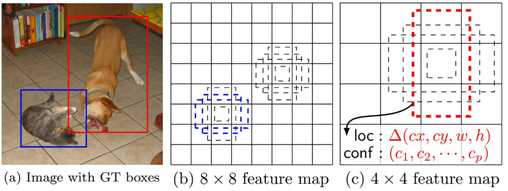
上图举了个某一层特征图的例子,该层每个锚点设置4个锚点框,loc为坐标偏移值,conf为类别的置信度,所以针对于每个锚框会得到20+1+4个预测值
三,全卷积网络结构(Convolutionalpredictorsfordetection)
•结合RFCN网络的优点,将所有的全连接网络全部更改为全卷积网络结构。
•使用卷积来提取候选框特征(offsetbox+score)。
特别注意:当你设置的特征图上的锚点还原到原图上的时候,要以特征图上的锚点的坐标*下采样的倍数+下采样的倍数/2,这样是为了防止你的锚点的坐标如果是(0,0),直接*下采样倍数还是(0,0)
下图是关于锚点和锚点框的计算:
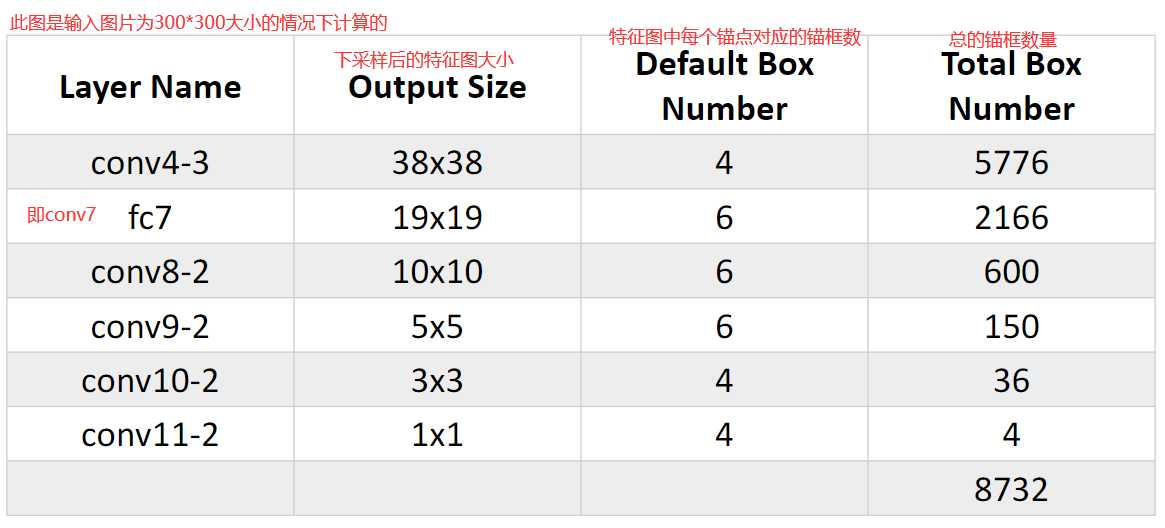
我把开局第一张图分成了三部分,如图
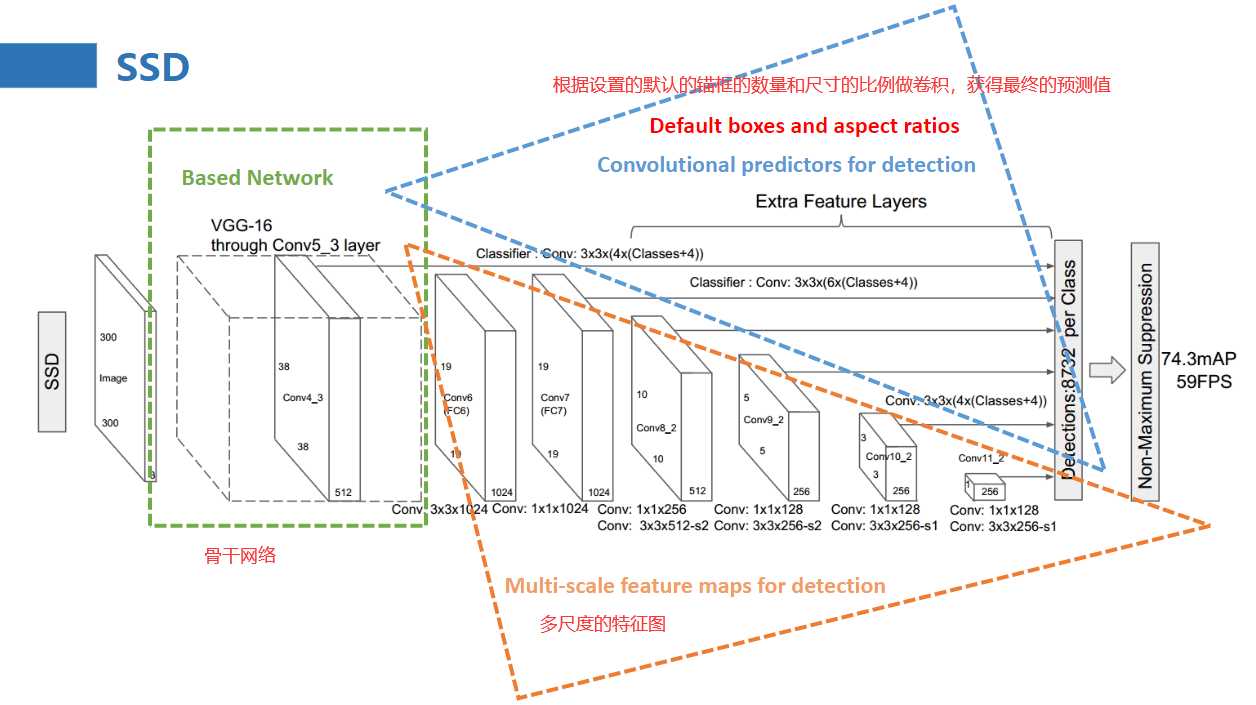
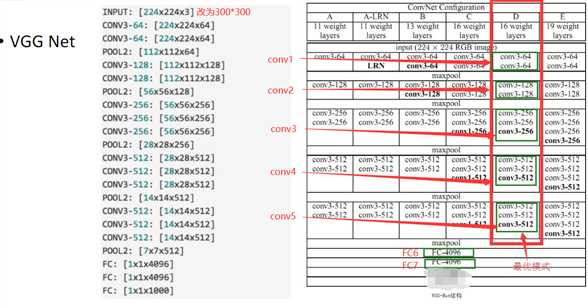
接下来说一说基于VGG网络做的具体的改动:
1.基础网络结构使用VGG,并且将FC6Layer和FC7Layer转换为卷积层,并将原来的MaxPooling5的大小从2x2-s2变化为3x3-s1(没有像原来一样做下采样,这样相当于做了一个特征的融合),这样pooling5操作后featuremap还是保持较大的尺寸,这样就会导致之后的感受野变小,也就是一个点对应到原始图形中的区域变小了。
2.为了保障感受野以及利用到原来的FC6和FC7的模型参数,使用atrousalgorithm的方式来增大感受野,也就是膨胀卷积/空洞卷积。(上图中fc6到fc7做了膨胀卷积)
膨胀卷积:为了增大感受野,但是又不想增加参数量时,在卷积核内部填充0,即可达到目的,如下图。但是会有一些信息损失。
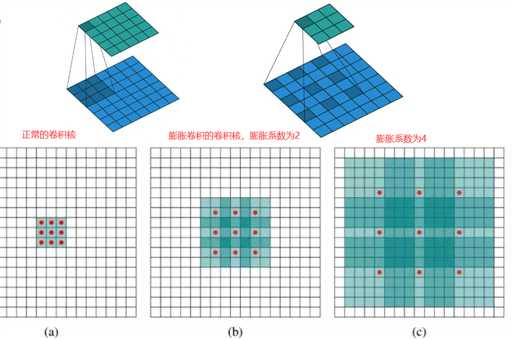
膨胀卷积核尺寸=膨胀系数*(原始卷积核尺寸-1)+1
•Conv6(fc6)中卷积核kernel为3,pad为6,dilation为6,所以相当于真实的卷积核大小为13,pad为6是为了保障输出featuremap大小尺度不变,仍为19x19。
•膨胀卷积(DilatedConvolution)的存在是为了解决一下几个问题的:
•普通的数据上采样层参数不可学习;
•内部数据结构丢失,空间层级化信息丢失;
•小物体信息无法重建。
•TensorFlow中膨胀卷积/空洞卷积API:•tf.nn.atrous_conv2d(value,filters,rate,padding,name=None)
一些提取框框的解说:
•在基础网络之后,使用不同层次卷积的featuremap来分别提取defaultbox,对于每个layer的featuremap使用两个并行的3x3卷积分别来提取位置信息(offsetbox)和置信度信息;结合Defaultbox和GroundTruthbox构建损失函数。
•对于Con4_3的数据提取的时候,会先对featuremap做一个L2 norm的操作(在进行3*3卷积进行预测前),因为层次比较靠前,防止出现数据值过大的情况。
在CNN网络中,层次越深,featuremap的尺寸(size)会越来越小,这样设计主要是为了以下两个目的:
•减少计算与内存的需求;
•最终提取的featuremap在某种程度上具备平移和尺度不变性,契合分类的业务场景要求。
•在目标检测场景中,经常需要处理不同尺度的物体,在某些网络中,会通过将图像转换为不同尺度大小的图像独立的通过网络处理,然后将这些不同尺度的图像结果合并,但是实际上,在同一个网络中,对不同层次上的featuremaps进行特征的处理实际上效果是一样的,并且所有尺度的物体处理参数是共享的,计算会更快。
一些结构的细节:
SSD结构中,defaultboxes不需要和每一层layer的receptivefields对应,通过产生不同scale大小的boxes来负责图像中特定区域以及物体的特定尺寸。
下面我们来谈一谈先验框的大小是如何计算的:
在提取先验框的时候,主要通过尺度(大小)和长宽比两个方面来进行设置,其中在先验框尺度上遵守一个线性递增规则:随着特征图大小降低,先验框尺度线性增加。
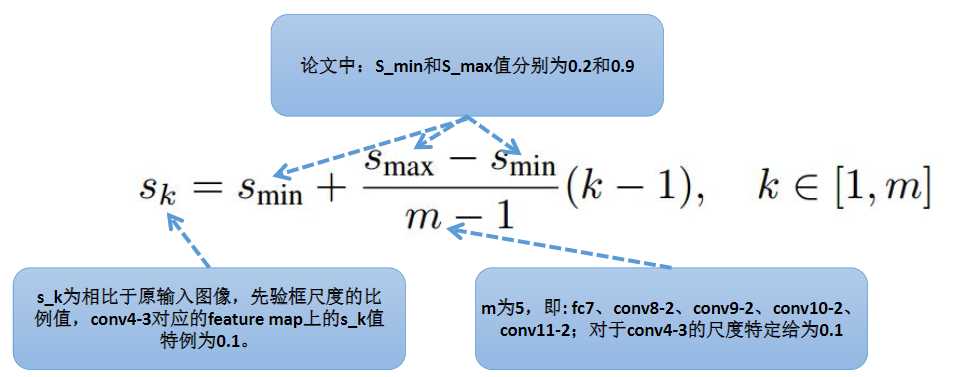
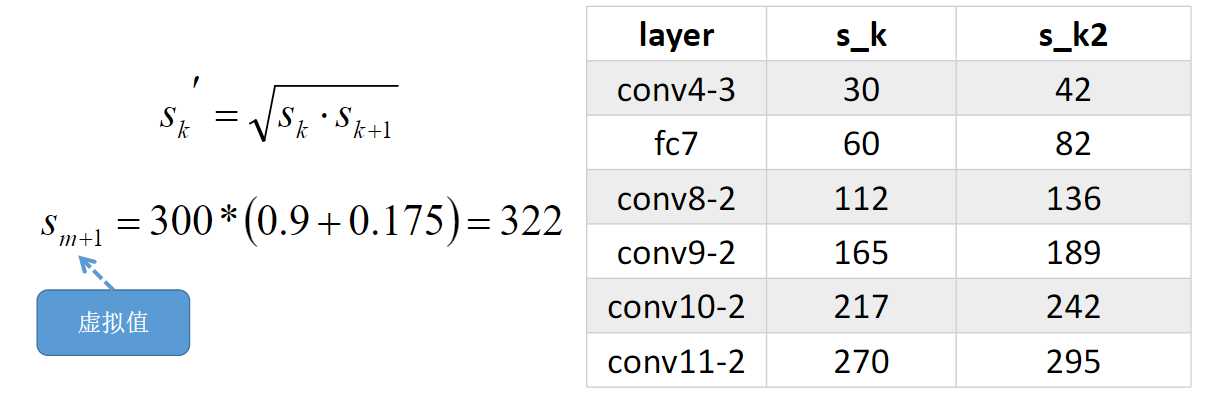
对应到我们这里就是下图,这五层的先验框的大小相对于原图的比例是从0.2到0.9不等。
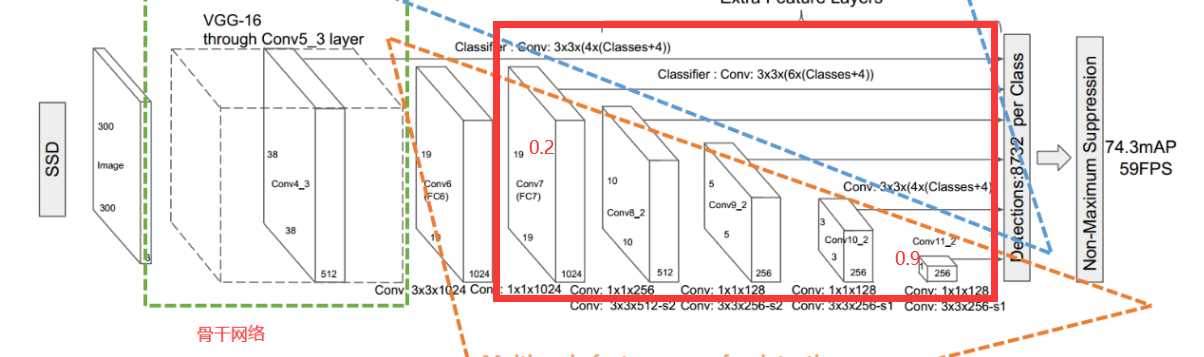
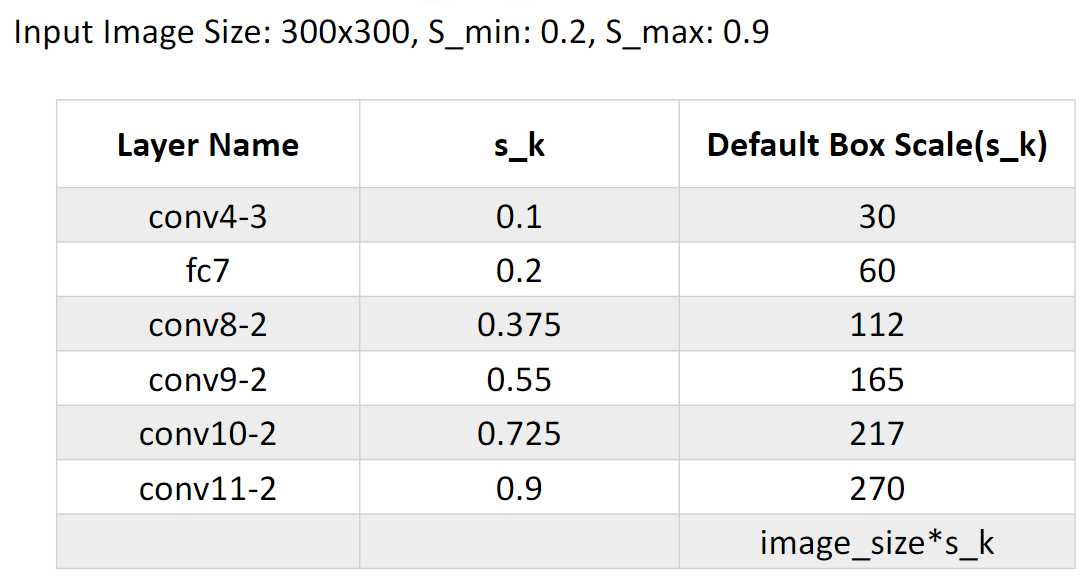
下图是该网络计算好的先验框大小:
计算好大小后还要计算它们的宽高的比例:
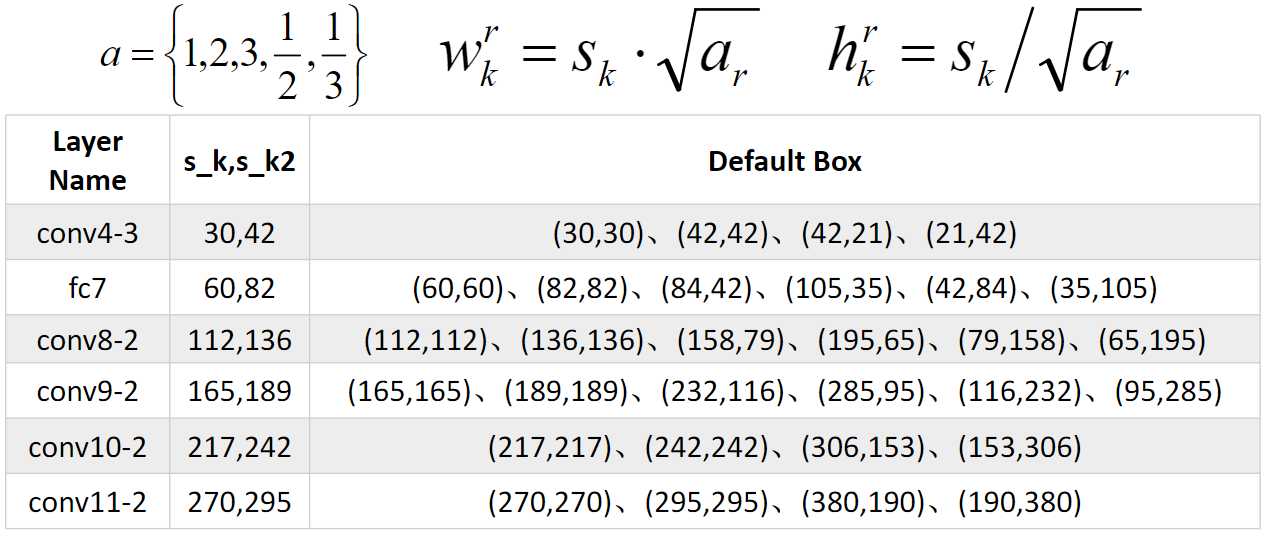
在提取先验框的时候,主要通过尺度(大小)和长宽比两个方面来进行设置,在长宽比上,论文中建议比率值选择范围为:[1,2,3,1/2,1/3]。对于Conv4-3、Conv10-2以及Conv11-2这三层,由于仅使用4个先验框,不使用1:3和3:1的这个比例值。
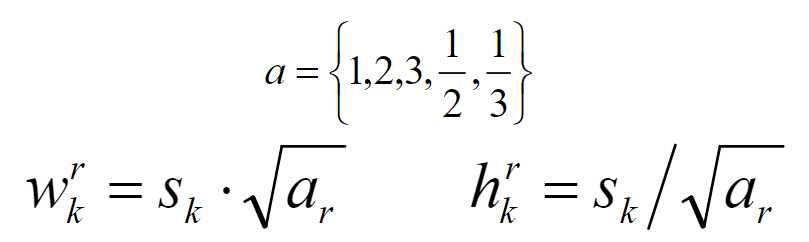
除了使用上述5个长宽比外,还引入一个特殊尺度并且长宽比为1的先验框。引入这个框的主要目的是为了体现最终的候选框中出现两个长宽比为1但是大小不同的正方形先验框。
最后计算得到所有的先验框大小:
来看一下正负样本的组成:

HardNegativeMining(难负样本挖掘):
•在生成先验框后,会产生很多符合GroundTruthBox的先验框,但是不符合的边框会更多,也就是negativeboxes的数目远多于positiveboxes的数目,也就会导致数据之间极度不均衡的情况出现,训练的时候比较难收敛。故在SSD中,采用R-CNN中介绍的难负样本挖掘算法对数据进行处理。将每个物体位置上对应的defaultboxes是negative的boxes按照前向loss的大小进行排序,获取loss比较大的N个negativeboxes参与模型训练,最终保证正负样本比例在1:3左右。
然后还做了数据增强:
•水平翻转(HorizontalFlip)
•随机剪裁加颜色扭曲(RandomCrop&ColorDistortion)
•随机采集块域(Randomlysampleapath)
训练数据类别给定标准:
•正样本:若先验框和GroundTruth框匹配,那么认为当前先验框为正样本;
•负样本:若先验框和所有GroundTruth框都不匹配,那么认为当前先验框为负样本。
•NOTE:采用hardnegativemining(难负样本挖掘算法)选择loss大的样本作为负样本,正负样本比例1:3;
SSD的先验框与GroundTruth的匹配原则主要有几点:
•1.对于图片中每个GroundTruth,找到与其IoU最大的先验框,该先验框与其匹配,
•2.对于剩余的未匹配先验框,若其和某个GroundTruth的IoU大于某个阈值(一般是0.5),那么该先验框也与这个GroundTruth(选择最大IoU的GT框)进行匹配。这意味着某个GroundTruth可能与多个先验框匹配,这是可以的。
•3.如果某个先验框和多个GroundTruth的IoU值大于阈值或者是最大IoU的先验框,那么这个先验框仅和IoU最大的那个GroundTruth匹配。
终于写到最后了...
最后,是激动人心的损失函数:
在SSD中,损失函数被定义为位置误差(locatizationloss,loc)与置信度误差(confidenceloss,conf)的加权和


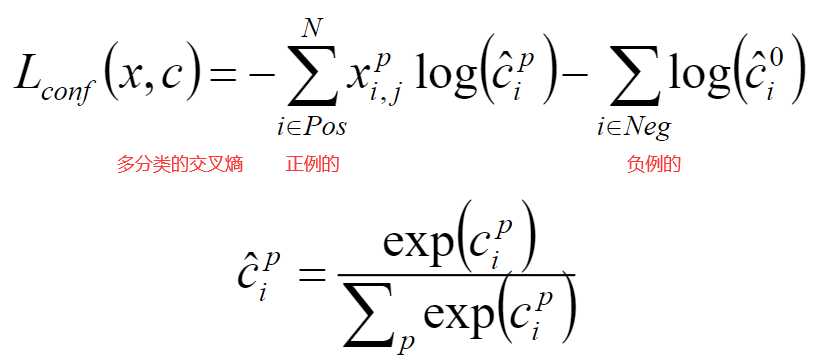

预测过程比较简单:
对于每个预测框,首先根据类别置信度确定其类别(置信度最大者)与置信度值,并过滤掉属于背景的预测框。然后根据置信度阈值(如0.5)过滤掉阈值较低的预测框。对于留下的预测框进行解码,根据DefaultBox先验框+offsetbox偏移量预测值做线性转换得到其真实的位置参数(解码后一般还需要做clip,防止预测框位置超出图片)。解码之后,一般需要根据置信度进行降序排列,然后仅保留top-k(如400)个预测框。最后就是进行NMS算法,过滤掉那些重叠度较大的预测框。最后剩余的预测框就是检测结果了。
最后一张与faster rcnn的效果对比图结束本场解说: