标签:区别 一起 文学 工作 创建 offset produce 命名 tar
听到这个名字是不是很熟悉,没错这个名字就是文学家卡夫卡的英文,传说中国的王小波也被誉为东方的乔伊斯+卡夫卡,哈哈哈,当然这篇文章不是谈论文学家卡夫卡的,那为什么一个消息中间件叫kafka呢?很简单就是这个中间件的作者喜欢卡夫卡,所以就这么命名了,如果有一天你也写出来一个牛逼的软件,而且你也很喜欢王小波,那你可以命名为xiaobo,没人可以拦得住你。
先上图(开篇一张图,内容全靠编)
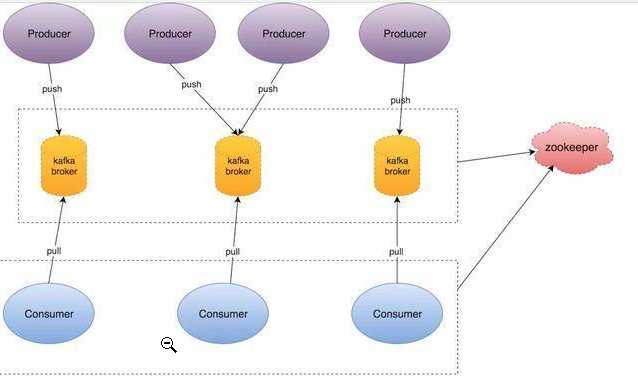
kafka broker: 从图中可以看出,这家伙是喜欢搞黄色的^_^,其实broker是kafka的基础存储单位,kafka所谓的分布式完全由多个broker一起组成的。
Topic:这个图中没有体现,不过很简单,所谓的Topic就是消息,每个种类的消息都有一个topic,这就像你在数据库中要给学生建立一张表,给老师建立一张表一样。
Partition:这个图中也没有体现,不过也很简单,有了Topic,你肯定要把Topic存储到broker中吧,既然broker有好多,那你不可能把一个Topic都存到一个broker里面吧,就像一个皇帝,怎么说也要做到雨露均沾,当然了,真实的原因并不是因为Topic喜欢瞎搞,而是因为这样可以提高吞吐量,一个节点肯定没有多个节点一起处理处理的快啊。那既然要分开存储就有了partition的概念,这个在创建Topic时候可以指定partition的个数。
Replication:这个就是partition的副本,作用也很明显就是容灾用的,不过这里需要特意说明一下,就是kafka的主分区和副本的待遇是完全不同的,这里面牵涉到两个问题,第一个就是如果主partition挂了,需要重新选出来一个主partition,这个是谁做的呢?就是zookeeper,上篇文章中有写到zookeeper也是需要选主的,第二个问题就是主partition负责读和写,副本什么也不干,只负责从主partition同步数据过来,这和zookeeper的leader,follower就有区别了,zookeeper的follower是可以处理读请求的,来分担leader的负担。
Consumer:这个无需多言,就是消费消息
Consumer Group:这个需要介绍一下,举一个不恰当的例子,过年祭祖的时候会供奉很多吃的,咱们就把这个比作Topic,那你直系祖先是一组,非直系祖先是另一组,接下来就开始吃了,那同一组里面吃的东西是不能重复吃的,比如一个鸡屁股被你太太爷吃了,你太太奶奶就吃不了了,但是不同组之间是没有影响的,你的非直系亲属仍然可以吃这个鸡屁股。
作为一个消息中间件,整个的工作流程应该是这样的,先生产消息,存储到kafka,之后消费者进行消费,接下来就分析一下这三个过程。
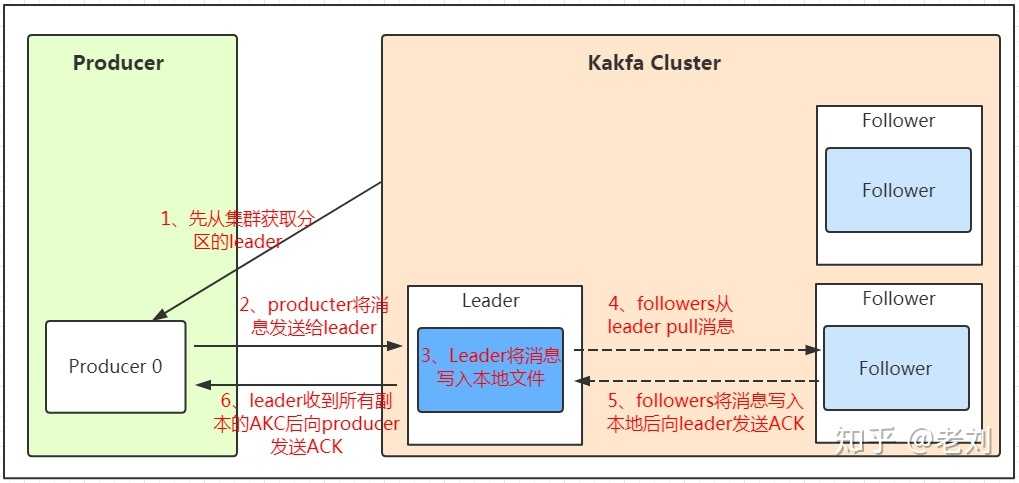
此图是盗的,上面水印为证,我有罪。。。
由上面这张图会引申出3个问题
问题一:图中的ACK是数据保存成功,并且同步到副本,之后再向生产者发送ACK,只有这种方式吗?
问题二:数据保存到本地文件之后是有顺序的吗?
问题三:如何找到特定的某条消息?比如生产了3000条消息,现在的offset是2456,怎么快速找到这条消息?
下面就一一解答上面的三个问题
问题一答案:图中的ACK机制是非常完美的方法,安全级别是最高的,当然还有另外两种机制,第一就是生产者发送完消息,kafka直接ack,不管有没有存储成功,这时ack=0。第二就是生产者发送完消息,消息存储到主分区,就直接ack,不等待向副本同步消息是否成功,这时ack=1。从上面的介绍可以看出图中的方式似乎是最好的,但是这种方式有一个缺点就是效率低。
问题二答案:数据无法保证全局有序,但是可以保证在同一个分区内部是有序的,如果要保证数据全局有序,只有一个办法,就是这个Topic只有一个分区。
问题三答案:要回答这个问题需要先了解kafka的存储方式,Partition在服务器上的表现形式就是一个一个的文件夹,每个partition的文件夹下面会有多组segment文件,每组segment文件又包含.index文件、.log文件、.timeindex文件(早期版本中没有)三个文件, log文件就实际是存储message的地方,而index和timeindex文件为索引文件,用于检索消息。如下图

yes,你没有看错,这个图仍然是盗的,下面我打算把我本机的实际存储贴一下,更加清晰。
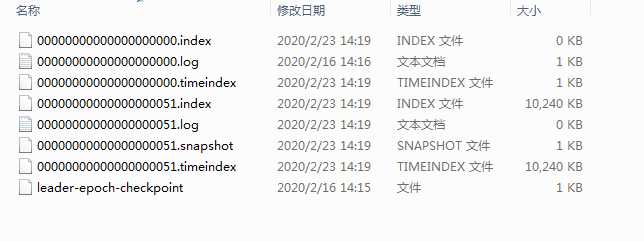
可以看出,我本地的kafka的这个Topic分为两段,第一段存储offset是0-50,第二个segment存储的51-之后的,这里说一下50是怎么来的,图中有一个000000000000000051.log,这个是怎么命名的呢?前面那一堆0是用于补齐的,没啥用,重点是51,这个是偏移量offset的开始位置,类似于mysql的分片。这里还要说明一点,就是向kafka存储的消息可以是压缩格式,比如gzip2,这样有两方面的好处,第一可以节省网络开销,第二可以节省存储空间,但是也有缺点,就是消费消息的时候需要解压缩,增加cpu的开销。因为巩固一下mysql的存储的知识,正好借着这个机会来比对一下mysql存储和这个相同点和不通点。
待更新。。。
1. 管理broker与consumer的动态加入与离开。(Producer不需要管理,随便一台计算机都可以作为Producer向Kakfa Broker发消息)
2. 触发负载均衡,当broker或consumer加入或离开时会触发负载均衡算法,使得一
个consumer group内的多个consumer的消费负载平衡。(因为一个comsumer消费一个或多个partition,一个partition只能被一个consumer消费)
3. 维护消费关系及每个partition的消费信息。
由于在新版本的kafka中,消费的偏移量offset信息已经不保存到zookeeper了,而是以Topic的形式直接保存到kafka中,至于为什么这么做,参考下面这篇文章:kafka中的offset存储问题小记,这篇文章降到了两点,第一就是每次消费更新zookeeper的offset是一个写操作,而zookeeper只有一个节点负责写操作,这样会导致zookeeper的负载过高,第二就是如果zookeeper出现点什么问题会严重影响kafka。
最近受疫情影响,不太平,又到了要找工作的时候,,,水了一篇文章,算是没有浪费一天吧。
标签:区别 一起 文学 工作 创建 offset produce 命名 tar
原文地址:https://www.cnblogs.com/gunduzi/p/12396155.html