标签:论文 https 使用 mda 讲解 time 大于 lte cep
论文:《Joint Face Detection and Alignment using Multi-task Cascaded Convolutional Networks》
论文网址:https://arxiv.org/abs/1604.02878v1
一、总体框架
MTCNN通过不同的卷积神经网络,实现对人脸的识别以及人脸关键点检测。总的框架如下:
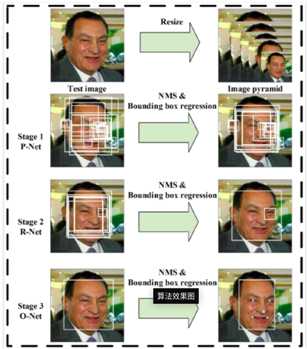
图1 Pipeline
如图1所示为MTCNN的整体框架。
给定一张图片,需要将其resize成不同大小的图片,建立图像金字塔。这些不同size的图片是下面三个stage的输入。
stage1:首先使用全卷积网络(P-Net)获取候选框和他们的回归向量。然后使用估计的bounding box回归向量去标定候选框。然后再使用非极大值抑制(NMS)去合并高度重叠的候选框;
stage2:这一层使用一个提炼网络(Refine Network, R-Net)。所有stage1中的候选框传入R-Net,使用边界框回归(bounding box regression)以及NMS,使得消除更多假的候选框(false candidates);
stage3:stage3使用一个输出网络(O-Net),该阶段与stage2相似。但是在这个阶段,我们的目标是更加详细地描述人脸。尤其是该网络将要输出5个人脸标记位置(facial landmarks‘ positions)。
二、CNN结构:
许多的论文都设计CNN用于人脸检测。但是,这些论文都受到以下几个原因的限制:
1)许多filter缺乏权重多样性限制了他们产生有判别力的描述。
2)相比于其他的多分类物体检测和分类任务,人脸检测是一个具有挑战性的二分类任务,因此可能需要更少数量的filters但是需要对人脸更具有辨别力。为了这个目的,我们减少filter的数量,将5×5的filter变成3×3的filter,减少计算量。但是增加filter的深度去获取更好的性能。从而可以得到更好的性能,但是运行时间变少。CNN的结构如图2所示。
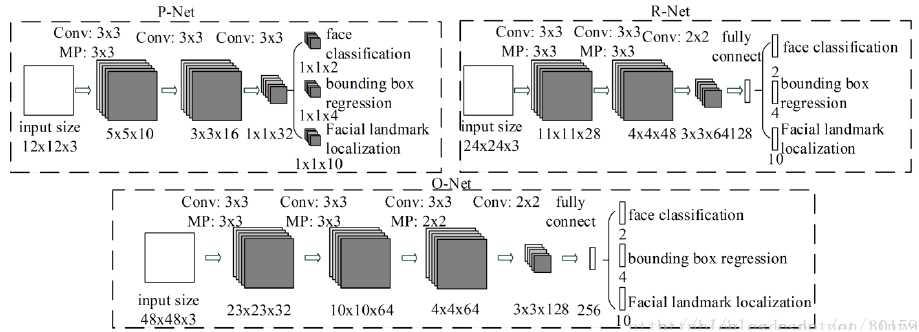
图2 CNN的结构(MP-max polling,Conv—convolution, 卷积和池化的step分别为1和2)
三、训练
使用三个tasks训练CNN detector,分别为:人脸/非人脸分类,边界框回归以及人脸标记定位。
1)人脸分类
学习目标可以表述为二分类任务。对于每个样本$x_{i}$,我们使用交叉熵损失函数(cross-entropy loss):
$L_{i}^{det}=-(y_{i}^{det}log(p_{i})+(1-y_{i}^{det})(1-log(p_{i})))$ (1)
其中,$p_{i}$是神经网络输出的概率,表示了一个样本是人脸的概率。$y_{i}^{det}\in \left \{0, 1\right \}$,表示ground truth的标签。
2)边界框回归
对于每一个候选框,我们需要预测它与最近的ground truth的偏移,包括:左上坐标、高度和宽度。学习目标可以表述为回归问题,对于每一个样本$x_{i}$,我们使用欧式损失(Euclidean loss):
$L_{i}^{box}=\left \| \hat{y}_{i}^{box} - y_{i}^{box}\right \|_{2}^{2}$ (2)
其中,$\hat{y}_{i}^{box}$回归目标是从神经网络获得的(即网络的输出),$y_{i}^{box}$是ground truth。有4个坐标,包括:左上、高度和宽度,因此$y_{i}^{box}\in \mathbb{R}^{4}$。
3)人脸标记定位
和边界框回归任务相似,人脸标记定位可以表示为回归任务问题,使用最小化欧式损失:
$L_{i}^{landmark}=\left \| \hat{y}_{i}^{landmark} - y_{i}^{landmark} \right \|_{2}^{2}$ (3)
其中,$\hat{y}_{i}^{landmark}$是从神经网络输出获得的人脸标记坐标,$ y_{i}^{landmark}$是ground truth。因为有5个人脸标记,包括:左眼睛、右眼睛、鼻子、嘴巴左边界和嘴巴右边界,因此$y_{i}^{landmark}\in \mathbb{R}^{4}$。
4)多数据源训练
因为我们在不同的CNN中执行不同的任务,所以在训练过程中,使用不同类型的训练图像数据,例如:人脸、非人脸和部分人脸数据。所以,一些损失函数(1-3公式)不会使用。例如,对于背景区域,我们仅仅计算$L_{i}^{det}$,另外两个损失设置为0,这个可以使用采样类型指示器实现。总的学习目标可以表示为:
$min\sum _{i=1}^{N}\sum _{j\in det,box,landmark}\alpha _{j}\beta _{i}^{j}L_{i}^{j}$ (4)
其中,$N$为训练样本的数量。\alpha_{j}表示人物的重要性(分别设置为:P-Net和R-Net中,$\alpha_{det}=1,\alpha_{box}=0.5,\alpha_{landmark}=0.5$;O-Net为了获得更加精确的人脸标记点定位,在O-Net中,$\alpha_{det}=1,\alpha_{box}=0.5,\alpha_{landmark}=1$)。$\beta _{i}^{j}\in \left \{ 0,1 \right \}$为采样类型指示器。使用随机梯度下降算法(SGD)训练CNNs。
5)在线困难样本挖掘
不同于在原始分类训练完成之后执行传统的困难样本挖掘,我们采用在线困难样挖掘适应训练过程。
特别地,我们对前向传播过程计算出的损失进行分类,然后只采用其中的70%作为困难样本。然后我们在后向传播过程中,只计算困难样本的梯度。这也就意味着我们忽略简单样本,这些简单样本对增强训练过程的探测功能不太有帮助。
6)训练数据
因为我们联合执行人脸检测和人脸对齐,因此我们在训练过程中使用四种不同的数据标记。分别为:
6.1负样本:与图片中任何一个ground truth的IOU小于0.3的区域;
6.2正样本:与图片中任何一个ground truth的IOU大于0.65的区域;
6.3部分人脸:IOU介于0.4和0.65之间;
6.4标记人脸:标记5个人脸标记位置的图片;
其中,负样本和正样本用于人脸分类任务(即判别是人脸还是非人脸);正样本和部分人脸用于边界框回归;人脸编辑样本用于人脸标记定位。每一个网络的训练数据可以如下表示:
①P-Net:从WIDER FACE数据集中随机裁剪获取正样本、负样本和部分人脸样本。然后,从CelebA数据裁剪人脸标记数据,需要resize成12×12;
②R-Net:将框架第一阶段的输出的proposal作为R-Net的输入,需要resize成24×24;
③O-Net :输入是经过第二步筛选和refine过的人脸框,同样从原图抠出后统一resize到48*48,成批输入ONet。
后面阶段都是在前面阶段的基础上对训练结果进行调整。
四、测试阶段
如第一节的总体架构,首先使图像生成图像金字塔,生成多尺度的图像,然后输入P-Net(因为P-Net是全卷积网络,该网络的输出的featuremap上的每一个特征点都对应于输入图像上的12×12的区域,因此)。PNet由于尺寸很小,所以可以很快的选出候选区域,但是准确率不高,不同尺度上的判断出来的人脸检测框,然后采用NMS算法,合并候选框,然后根据候选框提取图像,之后缩放到24*24的大小,作为RNet的输入,RNet可以精确的选取边框,一般最后只剩几个边框,最后缩放到48*48的大小,输入ONet,判断后选框是不是人脸,ONet虽然速度较慢,但是由于经过前两个网络,已经得到了高概率的边框,所以输入ONet的图像较少,然后ONet输出精确的边框和关键点信息,只是在第三个阶段上才显示人脸特征定位;前两个阶段只是分类,不显示人脸定点的结果。
参考:https://blog.csdn.net/wfei101/article/details/79935037
五、项目实践
参考项目地址:GitHub
根据参考项目做一些调整,模型实现。
数据集下载:
这里使用的数据集是WIDER FACE以及CelebA。
训练过程如下:
source activate tensorflow
将目录cd到preprocess上
python gen_12net_data.py生成三种pnet数据,
python gen_landmark_aug.py 12 生成pnet的landmark数据,
python gen_imglist_pnet.py整理到一起,
python gen_tfrecords.py 12生成tfrecords文件
将目录cd到train上python train.py 12 训练pnet
将目录cd到preprocess上,
python gen_hard_example.py 12 生成三种rnet数据,
python gen_landmark_aug.py 24 生成rnet的landmark数据,
python gen_tfrecords.py 24生成tfrecords文件
将目录cd到train上python train.py 24 训练rnet
将目录cd到preprocess上,
python gen_hard_example.py 24 生成三种onet数据,
python gen_landmark_aug.py 48 生成onet的landmark数据,
python gen_tfrecords.py 48生成tfrecords文件
将目录cd到train上python train.py 48 训练onet
测试验证过程:
python test.py
结果:
代码理解及讲解如文件中的注释。
参考:https://www.ctolib.com/LeslieZhoa-tensorflow-MTCNN.html
标签:论文 https 使用 mda 讲解 time 大于 lte cep
原文地址:https://www.cnblogs.com/xjlearningAI/p/12391312.html