标签:创建表 png sub 设置 bytes ref mamicode tap add
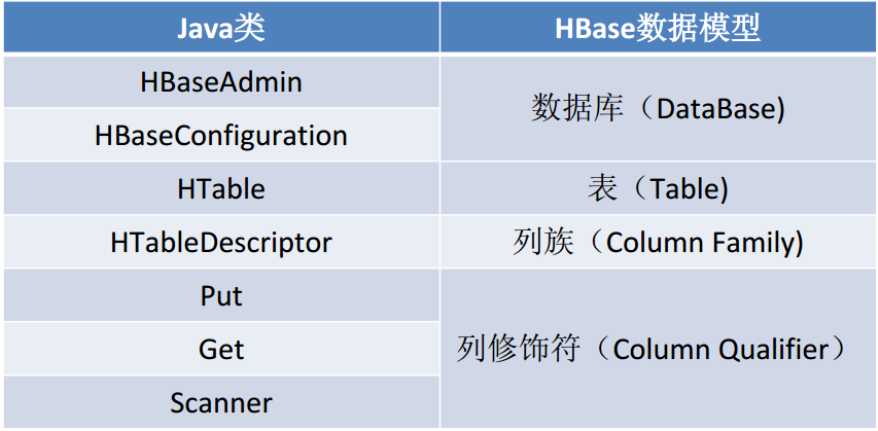
包名 : org.apache.hadoop.hbase.HBaseConfiguration
作用:对HBase进行配置。
使用方法演示样例:
HBaseConfiguration hconfig = new HBaseConfiguration(); hconfig.set("hbase.zookeeper.property.clientPort","2181");
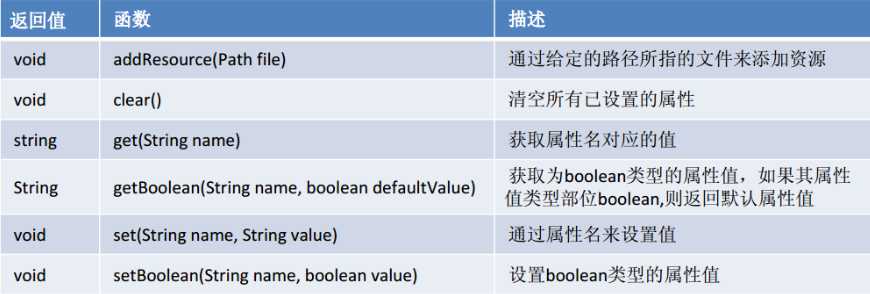
包名 : org.apache.hadoop.hbase.client.HBaseAdmin
作用:提供了一个接口来管理HBase数据库的表信息。
它提供的方法包括:创建表。删除表,列出表项。使表有效或无效,以及加入或删除表列族成员等。
使用方法演示样例:
HBaseAdmin admin = new HBaseAdmin(config); admin.disableTable("tablename")
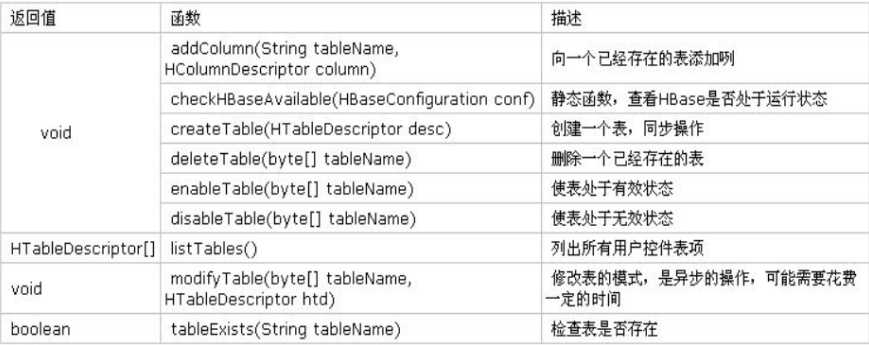
包名: org.apache.hadoop.hbase.HTableDescriptor
作用:包括了表的名字及其相应表的列族。
使用方法演示样例:
HTableDescriptor htd = new HTableDescriptor(table); htd.addFamily(new HcolumnDescriptor("family"));

包名: org.apache.hadoop.hbase.HColumnDescriptor
作用:维护着关于列族的信息,比如版本。压缩设置等。
它通常在创建表或者为表加入列族的时候使用。
列族被创建后不能直接改动。仅仅能通过删除,然后又一次创建的方式。
列族被删除的时候,列族里面的数据也会同一时候被删除。
使用方法演示样例:
HTableDescriptor htd = new HTableDescriptor(tablename); HColumnDescriptor col = new HColumnDescriptor("content:"); htd.addFamily(col);

包名: org.apache.hadoop.hbase.client.HTable
作用:能够用来和HBase表直接通信。此方法对于更新操作来说是非线程安全的。
使用方法演示样例:
HTable table = new HTable(conf, Bytes.toBytes(tablename)); ResultScanner scanner = table.getScanner(family);

包名: org.apache.hadoop.hbase.client.HTablePool
作用:能够解决HTable存在的线程不安全问题。同一时候通过维护固定数量的HTable对象,能够在程序执行期间复用这些HTable资源对象。
说明:
1. HTablePool能够自己主动创建HTable对象,并且对客户端来说使用上是全然透明的。能够避免多线程间数据并发改动问题。
2. HTablePool中的HTable对象之间是公用Configuration连接的,能够能够降低网络开销。
HTablePool的使用非常easy:每次进行操作前。通过HTablePool的getTable方法取得一个HTable对象,然后进行put/get/scan/delete等操作,最后通过HTablePool的putTable方法将HTable对象放回到HTablePool中。

/** * A simple pool of HTable instances. * * Each HTablePool acts as a pool for all tables. To use, instantiate an * HTablePool and use {@link #getTable(String)} to get an HTable from the pool. * * This method is not needed anymore, clients should call HTableInterface.close() * rather than returning the tables to the pool * * Once you are done with it, close your instance of {@link HTableInterface} * by calling {@link HTableInterface#close()} rather than returning the tables * to the pool with (deprecated) {@link #putTable(HTableInterface)}. * * <p> * A pool can be created with a <i>maxSize</i> which defines the most HTable * references that will ever be retained for each table. Otherwise the default * is {@link Integer#MAX_VALUE}. * * <p> * Pool will manage its own connections to the cluster. See * {@link HConnectionManager}. * @deprecated as of 0.98.1. See {@link HConnection#getTable(String)}. */ @InterfaceAudience.Private @Deprecated public class HTablePool implements Closeable { }
包名: org.apache.hadoop.hbase.client.Put
作用:用来对单个行执行加入操作。
使用方法演示样例:
HTable table = new HTable(conf,Bytes.toBytes(tablename)); Put p = new Put(brow);//为指定行创建一个Put操作 p.add(family,qualifier,value); table.put(p);
包名: org.apache.hadoop.hbase.client.Get
作用:用来获取单个行的相关信息。
使用方法演示样例:
HTable table = new HTable(conf, Bytes.toBytes(tablename)); Get g = new Get(Bytes.toBytes(row)); table.get(g);
包名: org.apache.hadoop.hbase.client.Result
作用:存储Get或者Scan操作后获取表的单行值。
使用此类提供的方法能够直接获取值或者各种Map结构( key-value对)。
包名: org.apache.hadoop.hbase.client.ResultScanner
作用:存储Get或者Scan操作后获取表的单行值。
使用此类提供的方法能够直接获取值或者各种Map结构( key-value对)。
package cn.itcast.bigdata.hbase;
import java.util.List;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.Cell;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.HColumnDescriptor;
import org.apache.hadoop.hbase.HTableDescriptor;
import org.apache.hadoop.hbase.KeyValue;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Delete;
import org.apache.hadoop.hbase.client.Get;
import org.apache.hadoop.hbase.client.HBaseAdmin;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.client.ResultScanner;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.filter.BinaryComparator;
import org.apache.hadoop.hbase.filter.BinaryPrefixComparator;
import org.apache.hadoop.hbase.filter.ByteArrayComparable;
import org.apache.hadoop.hbase.filter.ColumnPrefixFilter;
import org.apache.hadoop.hbase.filter.CompareFilter.CompareOp;
import org.apache.hadoop.hbase.filter.FamilyFilter;
import org.apache.hadoop.hbase.filter.Filter;
import org.apache.hadoop.hbase.filter.MultipleColumnPrefixFilter;
import org.apache.hadoop.hbase.filter.PrefixFilter;
import org.apache.hadoop.hbase.filter.QualifierFilter;
import org.apache.hadoop.hbase.filter.RegexStringComparator;
import org.apache.hadoop.hbase.filter.RowFilter;
import org.apache.hadoop.hbase.filter.SingleColumnValueFilter;
import org.apache.hadoop.hbase.filter.SubstringComparator;
import org.apache.hadoop.hbase.master.TableNamespaceManager;
import org.apache.hadoop.hbase.util.Bytes;
import org.junit.Before;
import org.junit.Test;
public class HbaseDemo { private Configuration conf = null; @Before public void init(){ conf = HBaseConfiguration.create(); conf.set("hbase.zookeeper.quorum", "weekend05,weekend06,weekend07"); } @Test public void testDrop() throws Exception{ HBaseAdmin admin = new HBaseAdmin(conf); admin.disableTable("account"); admin.deleteTable("account"); admin.close(); } @Test public void testPut() throws Exception{ HTable table = new HTable(conf, "person_info"); Put p = new Put(Bytes.toBytes("person_rk_bj_zhang_000002")); p.add("base_info".getBytes(), "name".getBytes(), "zhangwuji".getBytes()); table.put(p); table.close(); } @Test public void testGet() throws Exception{ HTable table = new HTable(conf, "person_info"); Get get = new Get(Bytes.toBytes("person_rk_bj_zhang_000001")); get.setMaxVersions(5); Result result = table.get(get); List<Cell> cells = result.listCells(); // result.getValue(family, qualifier); 可以从result中直接取出一个特定的value //遍历出result中所有的键值对 for(KeyValue kv : result.list()){ String family = new String(kv.getFamily()); System.out.println(family); String qualifier = new String(kv.getQualifier()); System.out.println(qualifier); System.out.println(new String(kv.getValue())); } table.close(); } /** * 多种过滤条件的使用方法 * @throws Exception */ @Test public void testScan() throws Exception{ HTable table = new HTable(conf, "person_info".getBytes()); Scan scan = new Scan(Bytes.toBytes("person_rk_bj_zhang_000001"), Bytes.toBytes("person_rk_bj_zhang_000002")); //前缀过滤器----针对行键 Filter filter = new PrefixFilter(Bytes.toBytes("rk")); //行过滤器 ByteArrayComparable rowComparator = new BinaryComparator(Bytes.toBytes("person_rk_bj_zhang_000001")); RowFilter rf = new RowFilter(CompareOp.LESS_OR_EQUAL, rowComparator); /** * 假设rowkey格式为:创建日期_发布日期_ID_TITLE * 目标:查找 发布日期 为 2014-12-21 的数据 */ rf = new RowFilter(CompareOp.EQUAL , new SubstringComparator("_2014-12-21_")); //单值过滤器 1 完整匹配字节数组 new SingleColumnValueFilter("base_info".getBytes(), "name".getBytes(), CompareOp.EQUAL, "zhangsan".getBytes()); //单值过滤器2 匹配正则表达式 ByteArrayComparable comparator = new RegexStringComparator("zhang."); new SingleColumnValueFilter("info".getBytes(), "NAME".getBytes(), CompareOp.EQUAL, comparator); //单值过滤器2 匹配是否包含子串,大小写不敏感 comparator = new SubstringComparator("wu"); new SingleColumnValueFilter("info".getBytes(), "NAME".getBytes(), CompareOp.EQUAL, comparator); //键值对元数据过滤-----family过滤----字节数组完整匹配 FamilyFilter ff = new FamilyFilter( CompareOp.EQUAL , new BinaryComparator(Bytes.toBytes("base_info")) //表中不存在inf列族,过滤结果为空 ); //键值对元数据过滤-----family过滤----字节数组前缀匹配 ff = new FamilyFilter( CompareOp.EQUAL , new BinaryPrefixComparator(Bytes.toBytes("inf")) //表中存在以inf打头的列族info,过滤结果为该列族所有行 ); //键值对元数据过滤-----qualifier过滤----字节数组完整匹配 filter = new QualifierFilter( CompareOp.EQUAL , new BinaryComparator(Bytes.toBytes("na")) //表中不存在na列,过滤结果为空 ); filter = new QualifierFilter( CompareOp.EQUAL , new BinaryPrefixComparator(Bytes.toBytes("na")) //表中存在以na打头的列name,过滤结果为所有行的该列数据 ); //基于列名(即Qualifier)前缀过滤数据的ColumnPrefixFilter filter = new ColumnPrefixFilter("na".getBytes()); //基于列名(即Qualifier)多个前缀过滤数据的MultipleColumnPrefixFilter byte[][] prefixes = new byte[][] {Bytes.toBytes("na"), Bytes.toBytes("me")}; filter = new MultipleColumnPrefixFilter(prefixes); //为查询设置过滤条件 scan.setFilter(filter); scan.addFamily(Bytes.toBytes("base_info")); ResultScanner scanner = table.getScanner(scan); for(Result r : scanner){ /** for(KeyValue kv : r.list()){ String family = new String(kv.getFamily()); System.out.println(family); String qualifier = new String(kv.getQualifier()); System.out.println(qualifier); System.out.println(new String(kv.getValue())); } */ //直接从result中取到某个特定的value byte[] value = r.getValue(Bytes.toBytes("base_info"), Bytes.toBytes("name")); System.out.println(new String(value)); } table.close(); } @Test public void testDel() throws Exception{ HTable table = new HTable(conf, "user"); Delete del = new Delete(Bytes.toBytes("rk0001")); del.deleteColumn(Bytes.toBytes("data"), Bytes.toBytes("pic")); table.delete(del); table.close(); } public static void main(String[] args) throws Exception { Configuration conf = HBaseConfiguration.create(); // conf.set("hbase.zookeeper.quorum", "weekend05:2181,weekend06:2181,weekend07:2181"); HBaseAdmin admin = new HBaseAdmin(conf); TableName tableName = TableName.valueOf("person_info"); HTableDescriptor td = new HTableDescriptor(tableName); HColumnDescriptor cd = new HColumnDescriptor("base_info"); cd.setMaxVersions(10); td.addFamily(cd); admin.createTable(td); admin.close(); } }
标签:创建表 png sub 设置 bytes ref mamicode tap add
原文地址:https://www.cnblogs.com/ssyfj/p/12403751.html
