标签:com 图解 += 时间 直接插入 blog 理解 mat 列表
其他排序方法:选择排序、冒泡排序、归并排序、快速排序、插入排序、希尔排序
希尔排序大概就是,选一组递减的整数作为增量序列。最小的增量必须为1:\(D_M>D_{M-1}>...>D_1=1\)
看图更容易理解吧:
(借用一下慕课的浙大数据结构课件。因为课件原本是ppt,而我只有pdf,所以颜色没有上齐,请将就将就emmm)
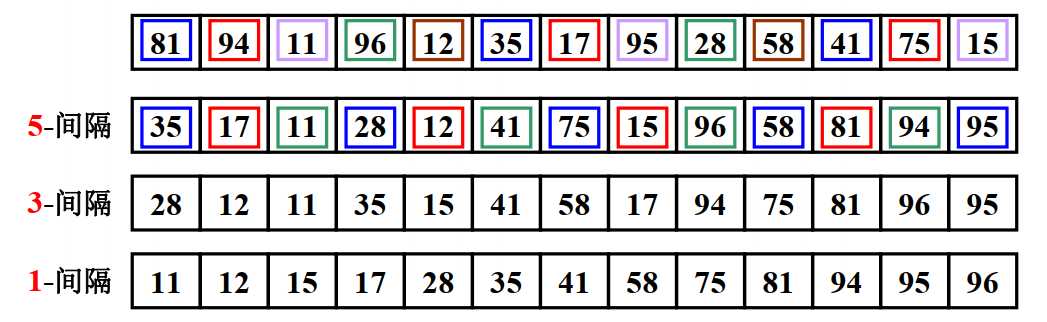
希尔排序快不快主要取决于我们怎么取增量序列,原始希尔排序的取法就是:\(D_M=\lfloor N/2 \rfloor, D_k=\lfloor D_{k+1}/2 \rfloor\)
此增量序列也成为Shell增量序列
原始希尔排序最坏的时间复杂度为\(O(n^2)\)
# 原始希尔排序
# 增量序列为D(M)=N/2, D(k)=D(k+1)/2 向下取整
def shellSort(arr):
size = len(arr)
# 正整数右移一位相当于除以2且向下取整
step = size >> 1
while step > 0:
for i in range(step, size):
j = i
tmp = arr[j]
while j >= step:
if tmp < arr[j - step]:
arr[j] = arr[j - step]
j -= step
else:
break
arr[j] = tmp
step = step >> 1希尔排序的优化主要是针对增量序列的优化。
增量序列如果取得不好,效率比直接插入排序还要低,下面举个例子(直接借用课件了):
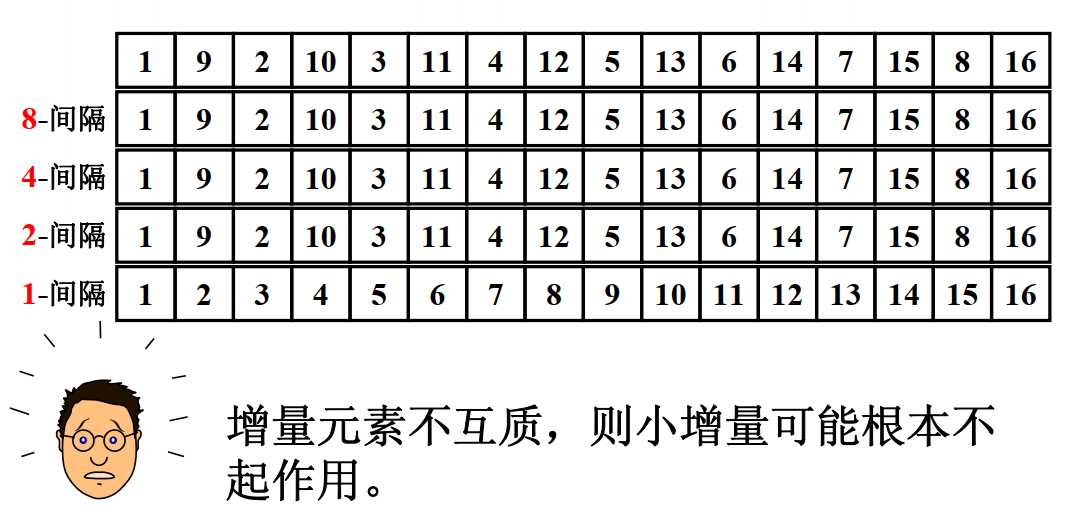
在这个例子里,前几个增量没有起到任何作用(只起到了拖延时间的作用哈哈)。
所以有人就发现了,如果增量之间不互质的话,那有些情况就不管用了。
于是有些大佬们就整出了下面这些增量序列:Hibbard增量序列、Knuth增量序列、Sedgewick增量序列等等
下面主要介绍Hibbard增量序列和Sedgewick增量序列
Hibbard增量序列的取法为\(D_k=2^k-1\):{1, 3, 7, 15, 31, 63, 127, 255, 511, 1023, 2047, 4095, 8191...}
最坏时间复杂度为\(O(N^{3/2})\);平均时间复杂度约为\(O(N^{5/4})\)
先来个Hibbard增量序列的获取代码:
# Hibbard增量序列
# D(i)=2^i?1,i>0
def getHibbardStepArr(n):
i = 1
arr = []
while True:
tmp = (1 << i) - 1
if tmp <= n:
arr.append(tmp)
else:
break
i += 1
return arr排序代码稍微修改一下就行:
# 希尔排序(Hibbard增量序列)
def shellSort(arr):
size = len(arr)
# 获取Hibbard增量序列
stepArr = getHibbardStepArr(size)
# 因为要倒着使用序列里的增量,所以这里用了reversed
for step in reversed(stepArr):
for i in range(step, size):
j = i
tmp = arr[j]
while j >= step:
if tmp < arr[j - step]:
arr[j] = arr[j - step]
j -= step
else:
break
arr[j] = tmp至于为什么要用python内置函数reversed(),而不用其它方法,是因为reversed()返回的是迭代器,占用内存少,效率比较高。
如果先使用stepArr.reverse(),再用range(len(arr))的话,效率会比较低;
而且实测reversed也比range(len(arr) - 1, -1, -1)效率高,故使用reversed();
还有就是先stepArr.sort(reverse=True),再用range(len(arr)),同样效率低。
这几种方法比较的测试代码在这里,有兴趣的朋友可以看看:Python列表倒序输出及其效率
Sedgewick增量序列的取法为\(D=9*4^i-9*2^i+1\)或\(4^i-3*2^i+1\):{1, 5, 19, 41, 109, 209, 505, 929, 2161...}
最坏时间复杂度为\(O(N^{4/3})\);平均时间复杂度约为\(O(N^{7/6})\)
Sedgewick增量序列的获取代码:
# Sedgewick增量序列
# D=9*4^i-9*2^i+1 或 4^(i+2)-3*2^(i+2)+1 , i>=0
# 稍微变一下形:D=9*(2^(2i)-2^i)+1 或 2^(2i+4)-3*2^(i+2)+1 , i>=0
def getSedgewickStepArr(n):
i = 0
arr = []
while True:
tmp = 9 * ((1 << 2 * i) - (1 << i)) + 1
if tmp <= n:
arr.append(tmp)
tmp = (1 << 2 * i + 4) - 3 * (1 << i + 2) + 1
if tmp <= n:
arr.append(tmp)
else:
break
i += 1
return arr排序代码稍微修改一下就行:
# 希尔排序(Sedgewick增量序列)
def shellSort(arr):
size = len(arr)
# 获取Sedgewick增量序列
stepArr = getSedgewickStepArr(size)
for step in reversed(stepArr):
for i in range(step, size):
j = i
tmp = arr[j]
while j >= step:
if tmp < arr[j - step]:
arr[j] = arr[j - step]
j -= step
else:
break
arr[j] = tmp其他排序方法:选择排序、冒泡排序、归并排序、快速排序、插入排序、希尔排序
标签:com 图解 += 时间 直接插入 blog 理解 mat 列表
原文地址:https://www.cnblogs.com/minxiang-luo/p/12392634.html