标签:请求 细节 条目 chm 内容 节点 wiki Raft算法 atlassian
上一篇讲述了什么是分布式一致性问题,以及它难在哪里,liveness和satefy问题,和FLP impossibility定理。有兴趣的童鞋可以看看分布式系统一致性问题与Raft算法(上)。
这一节主要介绍raft算法是如何解决分布式系统中一致性问题的。说起raft大家可能比较陌生,但zookeeper应该都比较熟悉了,zookeeper的ZAB协议可以说和raft算法是非常相似的。
再PS:本篇的重点是介绍raft算法的逻辑,所以有些细节会选择性得忽略,不然就太长了。对具体实现细节有兴趣的童鞋更应该去看看具体的论文。文末附上MIT6.824的地址以及raft中英文论文,有需求可以自取。
要说raft算法,那就不得不先说paxos算法。在raft算法问世之前,paxos算法可以说一直就是分布式一致性的代名词。但paxos有两个主要问题:
针对第一点,尽管有很多人试图降低它的复杂程度,但依旧改变不了它难以理解的事实。而第二点就致命了,首先paxos算法能解决分布式系统的共识问题,这个是已经被证明了的。但要将paxos算法实际应用起来,往往需要修改其算法结构,但很可能修改后算法就变了模样,也就是说修改后的paxos算法与原先的paxos算法相比有存在缺陷的可能,并且难以证明。
raft算法就是为了解决paxos的缺陷而产生的。它更加易于理解,并且能够达到paxos算法的相同功能,也就是能够解决分布式系统的一致性问题。
那么下面介绍下raft的具体实现吧。
raft的整体架构先从这张图看起,这是raft论文里面的图。
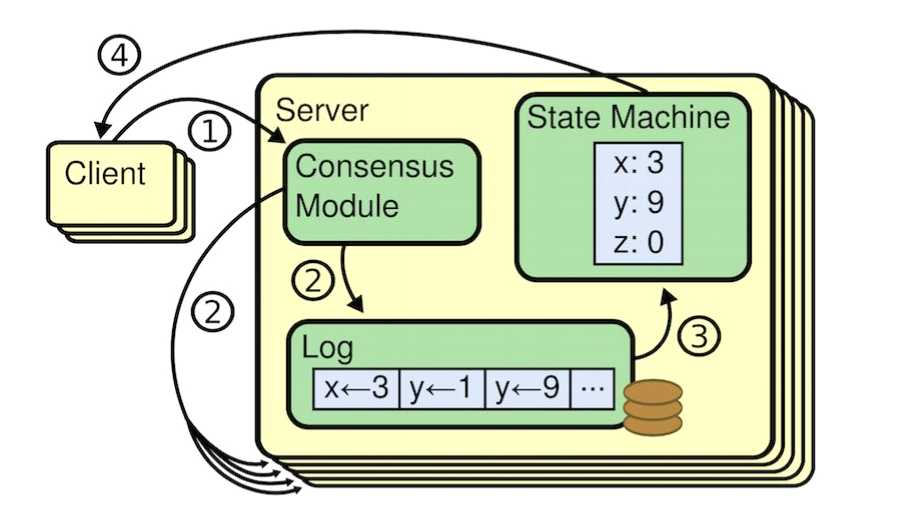
这张图揭示了客户端向服务器发送请求的流程,我们先简单介绍下图的内容,再分析下整个流程。左边的是客户端,右边的是服务端(分布式系统,即有N个节点)。客户端负责发送请求更改分布式系统中的状态(变量),服务端负责接收信息,并让系统中所有节点就某个状态达成共识。
服务端也就是分布式系统环境,由一个leader组成,多个follower构成。leader负责接收消息并同步给其他节点,以及负责解决节点信息不一致的问题,具体怎么解决后面会说。而follwer负责接收leader的消息以及当接收不到消息的时候,试图让自己成为leader。
那么整个流程大概是这样:
这就是大概的流程,当然其中省略了很多细节。那么现在,我们来看看具体的内部流程。
简单得说,raft通过一个选定一个系统唯一的领导者(其他节点为追随者),由它来负责管理各个节点(包括自己)的日志信息,来实现一致性。那么这样就有了两个问题,第一个是唯一的领导者选举,第二个是保证每个节点日志的一致性,我们逐个来说。
注意这里只会讲解大概的思路,尽量不去太深入到细节中去,还是那句话,对具体实现细节感兴趣的童鞋推荐看原论文(文末附)。
先大概介绍下领导者选举的流程。首先,leader会周期性得发送心跳(非固定周期,就是说可能间隔10ms发心跳给a,15毫秒发心跳给b,再间隔8ms发给a),维系自己的地位。当某个追随者在时间内没接收到leader的心跳的时候,它就会知道leader挂了,这个时候追随者就会尝试推举自己成为领导者(成为候选人),并发送请求让其他追随者投票给自己。其他追随者通过某种规则判断该候选人有没有“资质”,有则投票给他,否则不投票。最终,当超过半数的追随者认同该候选人,那么它就成为了新的leader。
在这个过程中,主要面临的也是两个问题,
处理这个问题,在raft算法中,引入了一个任期的概念。任期从0开始,随着leader的更迭逐渐递增,通过这个任期的概念,解决了多数分布式系统内部不一致的问题。
比如说一个leader挂掉或不可达的时候,会有一个追随者试图成为新leader,这时候它的任期会自动加1。还记得吗,竞选leader的节点需要发送请求给每一个追随者投票,这个请求信息中就包含新的任期,追随者接收信息对比发现请求里面的任期比自己的大,便会更新自己的任期。
这样一来,上面说到的僵尸节点问题就解决了,当旧的leader(僵尸leader)重新返回后,发送心跳给追随者,追随者发现心跳请求里面的任期比自己还低,便不再鸟它。旧的leader发现没人鸟自己,也就明白了自己已经不再是leader,所以就变成了追随者。
如果你足够细心,你会发现这个逻辑里面还隐藏着一个问题。要是某个任期在竞选leader的时候,没有获取到足够的选票,也就是系统内大多数节点不认可它该怎么办呀?很简单,这个任期就会变成一个空任期,会直接开始下一个任期的领导者选举。至于投票不投票的逻辑,这是我们接下来要说的。
我们在上面说了,每个节点会维持一个存放日志的list。其实这个list不止存放日志,它还存放了每条日志对应的任期。类似
[(‘状态5‘,‘任期0‘),(‘状态10‘,‘任期0‘),(‘状态14‘,‘任期1‘)]
这样的列表。
我们知道当追随者试图成为leader(也就是候选人)的时候,会广播投票请求,请求里面就包含了竞选者日志list中最后一条日志的索引,以及对应的任期。每个进行投票的追随者会与自身的日志list比较,如果索引比自身list的最后索引小,那么说明候选人的日志没自己的新,这时候追随者会拒绝投票。
这样的特性能够保证系统尽可能得选出日志最新的节点,为什么说尽可能?因为依旧存在可能丢失状态。比如leader接收到请求,还没发给其他节点,或只发给少数节点。那么没来得及完成处理的这些请求就可能丢失,但即便这样,系统在最终依旧会能维持一致,只是并非最新更改的状态值,或者说有部分数据任然会丢失。
首先,所有的状态改变(可以理解为变量值改变)都是由leader执行,然后将这一改变辐射到所有的追随者。每个节点都维持一个存日志的list,用以存储每一条改变状态的信息。
leader接收客户端的操作指令后,先追加这一指令到自己的日志list,然后会将指令发送给追随者,追随者主要目的就是接收这些指令,并追加到自己日志list中。leader负责管理和检测追随者的日志list是否和自己的一致,由此实现整个分布式系统的一致性。
在这个过程,主要也是有几个问题需要解决:
在介绍日志一致性前,需要明白这样两个事实:
如果在不同的节点的日志list中,两个条目拥有相同的索引和任期号,那么他们存储了相同的指令。
如果在不同的节点的日志list中,两个条目拥有相同的索引和任期号,那么他们之前的所有日志条目也全部相同。
也就是说,两个节点各自有一个list保存日志,如果两个节点各自的list中的某个索引相同点,任期也相同,那么说明它前面的内容都是一致的。
解决日志一致性这个问题其实不难,就是当leader将客户端的指令辐射出去的时候,要等到所有追随者状态确认后再执行下一条客户端指令,典型的用效率换取准确性。这里的状态确认只有三种,成功,失败和连接不上客户端。注意失败和连接不上是两种情况,失败有可能是因为某些日志数据不一致,这时就需要找到追随者日志list中与一致的那个点,然后覆盖掉后面不一致的数据。最极端的情况就是发现追随者全部都和leader的日志list不一致,那么就会将leader的list全部覆盖追随者的日志list,这种做法也叫做强制复制。
而连接不上则可能是因为追随者正忙,或者它真的挂掉了。上一篇讲过,要在异步的网络通信中真正识别这两种情况几乎是不可能的。这时候,我们可以直接认为它挂掉了,如果发现其实没挂,那么直接按照僵尸节点的逻辑来处理。
当发现追随者节点不可达的时候,会将它标记为僵尸节点(论文里是说无限重试,但实际操作发现无限重试存在一些问题),等待该追随者重启。这样一来,当僵尸节点重新恢复时最大的问题其实就是它的任期和日志list远落后于leader。
解决这些问题的方法其实上面都讲到了,每次leader请求,追随者会比较任期,发现自己任期低会自动更新。如果是日志list,那么会找到与leader日志list一致的那个索引,然后覆盖后面的全部list。
最后再来结合具体的例子看看吧。
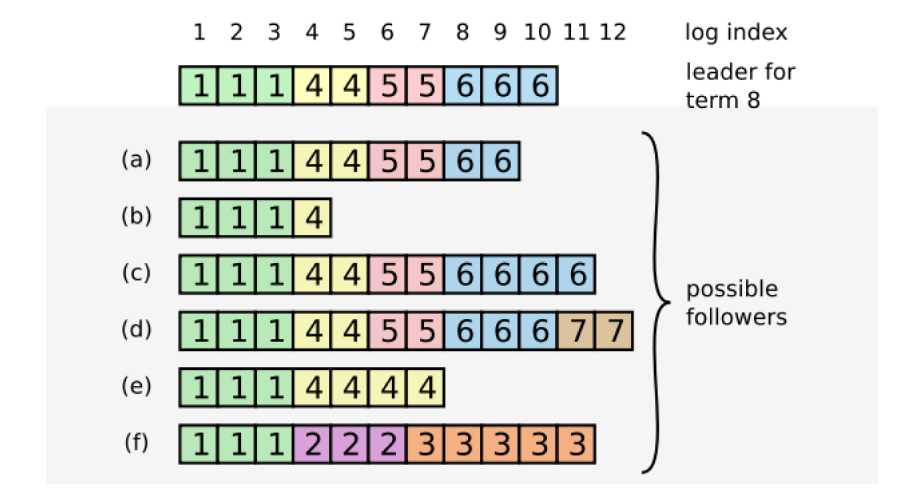
灰色方框之上的是一个刚担任leader的节点。a,b,c,到f是不同的几个follower节点,每个节点后面的那行代表日志list,里面的数字表示任期。
当一个leader当选的时候,a,b,...到f基本涵盖了可能的情况。a和b表示追随者缺少部分日志,那么这时候追加就行。c和d表示r日志过多,那么要删除索引11以及之后的日志,让日志和leader保持一致。e和f表明r日志list有不一致的内容,即某些地方任期不一致,这时候e会找到索引相同的最后一个节点(这里是5),覆盖后面的内容,f也是同样的道理。
OK,以上就是raft算法维持分布式系统一致性的基本思路,当然还有一些额外的内容,比如防止日志list过长而可以采用的checkpoint技术,以及客户端实现exctly once语义的方法,这些比较细节的内容就不多说了。这篇文章的目的还是希望起到抛砖引玉的作用而已。
以上~
标签:请求 细节 条目 chm 内容 节点 wiki Raft算法 atlassian
原文地址:https://www.cnblogs.com/listenfwind/p/12390489.html