标签:spl beat 编码 数据 默认 工具 net info match
一、正则常用的方法
1.match:从开始位置开始查找,一次匹配
2.sear?ch:从任何位置查找,一次匹配
3.findall?:全部匹配,返回列表
4.finditer?:全部匹配,返回迭代器
5.?split:分割字符串,返回列表
?6.sub:替换
7.匹配中文
中文unicode编码[u4e00-u9fa5]
8.贪婪算法和非贪婪算法
?贪婪模式:在整个表达式匹配成功的前提下,尽可能的多的匹配
?非贪婪模式:在整个表达式匹配成功的前提下,尽可能的少的匹配
python中默认时贪婪模式
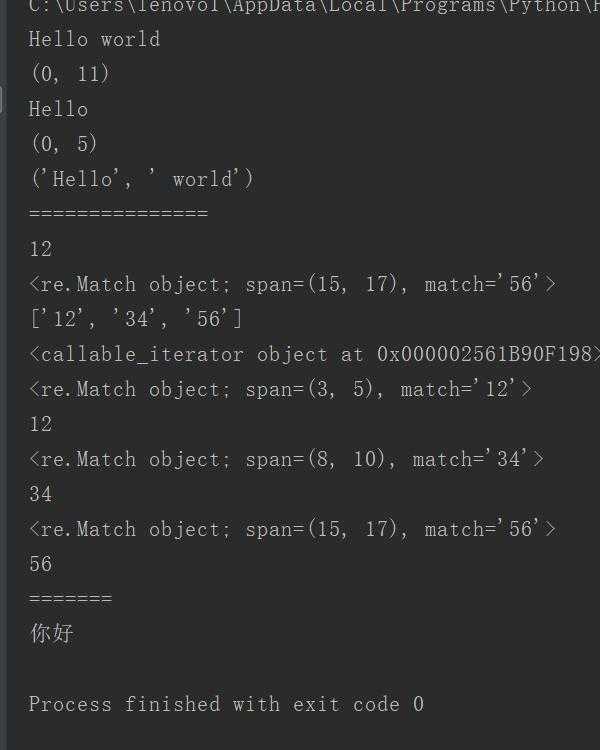
import re ? s = r"([a-z]+)( [a-z]+)" pattern = re.compile(s,re.I) ? m = pattern.match("Hello world wide web") #group(0)表示返回匹配成功的整个字串 s = m.group(0) print(s) #返回匹配成功的整个子串的跨度 a = m.span(0) print(a) #group(1)表示返回的第一个分组匹配成功的字串 s = m.group(1) print(s) #span(1)返回匹配成功的第一个子串的跨度 a = m.span(1) print(a) #groups()返回的是匹配的所有分组子串都输出出来,不包含整个匹配的子串 b = m.groups() print(b) print("===============") string = r"\d+" pattern = re.compile(string) m = pattern.search("one12two34three56")#返回第一个查找到的结果 print(m.group(0))#这里的0不写也没有关系,不写就是默认为0 m = pattern.search("one12two34three56",10,40)#从字符串的第十个位置进行查找,第四十结束,这里不够四十,那就直接到字符串结束位置即可 print(m) ? m = pattern.findall("one12two34three56")#以列表的形式返回所有的结果 print(m) ? m = pattern.finditer("one12two34three56") print(m) for i in m: print(i) print(i.group()) ? print("=======") string2 = u"你好,世界" pattern = re.compile(r"[\u4e00-\u9fa5]+") print(pattern.search("你好,世界杯").group())
二、BeatuifulSoup4 --CSS选择器
1.现在使用BeautifulSoup4
2.?参考链接:https://beautifulsoup.readthedocs.io/zh_CN/latest/
3.?几个常用的提取工具的比较:
(1)?正则:很快,不好用,不允许安装
(2)beautifulsoup:慢,但是使用简单,安装简单
(3)lxml?:比较快,使用简单,但是安装一般
from urllib import request from bs4 import BeautifulSoup url = "http://www.baidu.com" rsp = request.urlopen(url) content = rsp.read() soup = BeautifulSoup(content,"html") #bs自动转码 content = soup.prettify() print(content)
三、源码
Reptitle12_1_TRegularExpression.py
Reptile12_2_BeautifulSoup.py
https://github.com/ruigege66/PythonReptile/blob/master/Reptitle12_1_TRegularExpression.py
https://github.com/ruigege66/PythonReptile/blob/master/Reptile12_2_BeautifulSoup.py
2.CSDN:https://blog.csdn.net/weixin_44630050
3.博客园:https://www.cnblogs.com/ruigege0000/
4.欢迎关注微信公众号:傅里叶变换,个人公众号,仅用于学习交流,后台回复”礼包“,获取大数据学习资料

Python爬虫连载12-爬虫正则表示式、BeautifulSoup初步
标签:spl beat 编码 数据 默认 工具 net info match
原文地址:https://www.cnblogs.com/ruigege0000/p/12424082.html