标签:复杂度 tail 模式匹配 友好 pre blog 目录 信息 例子
KMP 算法,又称模式匹配算法,能够在线性时间内判定字符串 \(A[1-N]\) 是否为字符串 \(B[1-M]\) 的子串。
对于刚刚接触 KMP 的同学来说,理解起来比较困难,难以理解 \(next[]\) 数组的实际意义。
当然你要硬背 KMP 也没人拦着你,因为代码确实就十几行
但是其实并没有那么难懂,产生畏惧情绪更是不必要的,现在谈谈 KMP。
Knuth-Morris-Pratt 字符串查找算法,简称为 “KMP算法”。
这个算法由Donald Knuth、Vaughan Pratt、James H. Morris三人于1977年联合发表,故取这3人的姓氏命名此算法。
主要的难点和中心点就是 \(next[]\) 数组和 \(f[]\) 数组的求解,其中又以 \(next[]\) 为重。
下文将展开详细的叙述。
首先,暴力很好想,就是枚举比较,时间 \(O(NM)\) 。 (这个应该都会吧)
但是,谁都会发现这种算法的效率很低,但原因是什么,请看下图。
其中 \(txt\) 是原字符串,\(pat\) 是子串。
很明显,pat 中根本没有字符 c,根本没必要回退指针 i,暴力解法明显多做了很多不必要的操作。
KMP 算法的不同之处在于,它会花费空间来记录一些信息,在上述情况中就会显得很聪明:
再比如类似的 \(txt = "aaaaaaab"\) \(pat = "aaab"\)。
暴力解法还会和上面那个例子一样蠢蠢地回退指针 i,而 KMP 算法又会耍聪明:
综上,KMP 快速的原因是:避免了不必要的多余匹配。
而且,KMP 算法不仅能更高效、更准确的处理这个问题,还可以提供一些额外的信息。
具体的讲,KMP 算法共分为两步:
是不是发现两者很相像(所以代码也很像),下面我们将详细讲解 \(next[]\) 数组的求解方法。
可能很多同学看到上面两个步骤就昏倒,其实也没有那么难,通俗的讲 \(next\) 就是最长前缀后缀(好像没有很通俗)
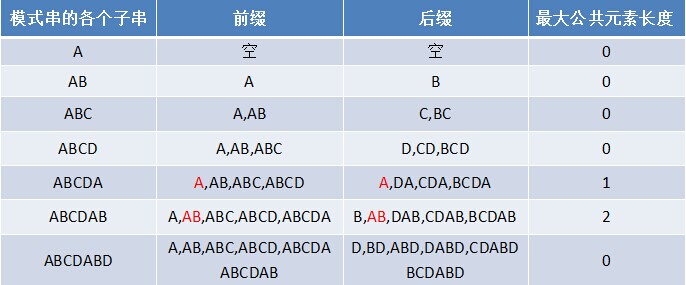
如果给定的模式串 \(A=“ABCDABD”\),从左至右遍历整个模式串,其各个子串的前缀后缀分别如下表格所示:
也就是说,原模式串子串对应的各个前缀后缀的公共元素的最大长度表为(下简称《最大长度表》):
根据这个表可以得出下述结论:
失配时,模式串向右移动的位数为:已匹配字符数 - 失配字符的上一位字符所对应的最大长度值记住这是很重要的一个结论,证明比较繁琐,可以自行百度,但我是直接记住的。(只在记不住就靠数学能力吧)
这只是通俗的讲,真正的引理是:
若 \(j_0\) 是 \(next[i]\) 的“候选项”,即 \(j_0<i\) 且 \(A[i-j_0+1\)~\(i]\) = \(A[1\)~\(i]\) ,则小于 \(j_0\) 的最大的 \(next[i]\) 的“候选项”是 \(next[j_0]\) 。换句话说,\(next[j_0]+1\)~\(j_0-1\) 之间的数都不是 \(next[i]\) 的“候选项”。
请读者务必确定理解这条引理之后再往下看,实在不行可以借助百度以及其他资料。
简单说就是根据递归求法求解答案。
假设已求出 \(next[i-1]\) 的值,则 \(next[i-1]\) 的所有候选项为 \(next[i-1]\),\(next[next[i-1]]\),\(next[next[next[i-1]]]\)等。
\(j\) 是 \(next[i]\) 的候选项的前提是 \(j-1\) 是 \(next[i-1]\) 的候选项。
(\(A[i-j+1\)~\(i]\) = \(A[1\)~\(j]\) 的前提是 \(A[i-j+1\)~\(i-1]\) = \(A[1\)~\(j-1]\))
因此在计算 \(next[i]\) 是只需要把 \(next[i-1]+1\),\(next[next[i-1]]+1\),\(next[next[next[i-1]]]+1\)等作为候选项即可。
具体看代码:
next[1]=0;
for(int i=2,j=0;i<=n;i++){
while(j>0 && a[i]!=a[j+1]) j=next[j];
if(a[i]==a[j+1]) j++;
next[i]=j;
}因为定义的相似性,两者代码几乎一样。
for(int i=1,j=0;i<=m;i++){
while(j>0 &&(j==n || b[i]!=a[j+1])) j=next[j];
if(b[i]==a[j+1]) j++;
f[i]=j;
//if(f[i]==n) 此时就是 A 在 B 中的某次出现
}就是模板题而已。
下面给出完整代码:
#include<cstdio>
#include<algorithm>
#include<cstring>
#include<iostream>
#define maxn 1000010
using namespace std;
int l1,l2,next[maxn],f[maxn];
char s1[maxn],s2[maxn];
int main(){
cin>>s1+1;
cin>>s2+1;
l1=strlen(s1+1);
l2=strlen(s2+1);
next[1]=0;
for(int i=2,j=0;i<=l2;i++){
while(j>0 && s2[i]!=s2[j+1]){
j=next[j];
}
if(s2[j+1]==s2[i]) j++;
next[i]=j;
}
for(int i=1,j=0;i<=l1;i++){
while(j>0 &&(j==l1 || s1[i]!=s2[j+1])){
j=next[j];
}
if(s1[i]==s2[j+1]) j++;
f[i]=j;
}
for(int i=1;i<=l1;i++)
if(f[i]==l2) printf("%d\n",i-l2+1);
for(int i=1;i<=l2;i++)
printf("%d ",next[i]);
return 0;
} KMP 算法到这里就结束了,这篇文章可能对初学者不太友好,不过也可以加深理解吧。
其时间复杂度为:\(O(N+M)\) 。
当然你,其复杂度是可以优化的,而且也有更优的算法,时候回继续 \(Update\)。
注:
全篇完。
标签:复杂度 tail 模式匹配 友好 pre blog 目录 信息 例子
原文地址:https://www.cnblogs.com/lpf-666/p/12448119.html