标签:包括 变量 第一步 装饰器 %s 语言 sea 另一个 并发
在函数内部,可以调用其他函数。但是在一个函数在内部调用自身,这个函数被称为递归函数
def calc(n): print(n) if int(n/2) == 0: #结束符 return n return calc(int(n/2)) #调用函数自身 m = calc(10) print(‘----->‘,m) #输出结果 10 5 2 1 -----> 1 #最后返回的值
1. 必须有一个明确的结束条件
2. 每次进入更深一层递归时,问题规模相比上次递归都应有所减少
3. 递归效率不高,递归层次过多会导致栈溢出(在计算机中,函数调用是通过栈(stack)这种数据结构实现的,每当进入一个函数调用,栈就会加一层栈帧,每当函数返回,栈就会减一层栈帧。由于栈的大小不是无限的,所以,递归调用的次数过多,会导致栈溢出)
堆栈详情:http://www.cnblogs.com/lln7777/archive/2012/03/14/2396164.html
1+2+3+4+.....+100的例子,代码如下:

def add_to_100(n): if n == 0: return n return n + add_to_100(n - 1) n = add_to_100(100) print(n) # 输出结果 5050
二分查找,代码如下:
1 def binary_search(dataset, find_num): 2 print(dataset) 3 4 if len(dataset) > 1: 5 mid = int(len(dataset) / 2) 6 if dataset[mid] == find_num: # find it 7 print("找到数字", dataset[mid]) 8 elif dataset[mid] > find_num: # 找的数在mid左面 9 print("\033[31;1m找的数在mid[%s]左面\033[0m" % dataset[mid]) 10 return binary_search(dataset[0:mid], find_num) 11 else: # 找的数在mid右面 12 print("\033[32;1m找的数在mid[%s]右面\033[0m" % dataset[mid]) 13 return binary_search(dataset[mid + 1:], find_num) 14 else: 15 if dataset[0] == find_num: # find it 16 print("找到数字啦", dataset[0]) 17 else: 18 print("没的分了,要找的数字[%s]不在列表里" % find_num) 19 20 21 binary_search(data, 66) 22 23 24 #输出结果 25 [1, 3, 6, 7, 9, 12, 14, 16, 17, 18, 20, 21, 22, 23, 30, 32, 33, 35] 26 找的数在mid[18]右面 27 [20, 21, 22, 23, 30, 32, 33, 35] 28 找的数在mid[30]右面 29 [32, 33, 35] 30 找的数在mid[33]右面 31 [35] 32 没的分了,要找的数字[66]不在列表里
匿名函数就是不需要显式的指定函数,跟普通函数的最大区别就是不用特意用def 关键字去定义
# 这段代码 def calc(n): return n ** n print(calc(10)) # 换成匿名函数 calc = lambda n: n ** n print(calc(10))
匿名函数主要是和其它函数搭配使用,可以优化代码,如下:
res = map(lambda x:x**2,[1,5,7,4,8]) for i in res: print(i)
嵌套函数,顾名思义就是函数里面套函数,在一个函数的函数体内,用def 去声明一个函数,而不是去调用其他函数,称为嵌套函数
name = "apple" def change_name(): name = "apple1" def change_name2(): name = "apple2" print("第3层打印", name) change_name2() # 调用内层函数 print("第2层打印", name) change_name() print("最外层打印", name)
注:主要用于装饰器
变量可以指向函数(把函数名,即函数的栈内存地址当成变量的值,函数名作为变量),函数的参数能接收变量,那么一个函数就可以接收另一个函数作为参数,说白了,高阶函数功能就是:把函数本身当做一个参数,传到另一个函数中,然后在这个函数中做处理,这种函数就称之为高阶函数:
# 普通函数 def test_1(a, b): return a + b # 高阶函数 def test_2(a, b, f): return f(a) + f(b) print("-----test_1-----") res = test_1(1, -3) print(res) print("-----test_2-----") res = test_2(1, -3, abs) # 把abs这个内置函数当做参数传进去 print(res) # 输出结果 -----test_1----- -2 -----test_2----- 4
import time as t def bar(): t.sleep(3) print("in the bar") def test1(func): print(func) start_time = t.time() func() stop_time = t.time() print("the func run the is %s" % (stop_time - start_time)) # 没有修改bar的代码 test1(bar) # 把bar函数名当做实参传到test1中 #输出结果 <function bar at 0x01220810> #bar函数的内存地址 in the bar the func run the is 3.0000081062316895
import time as t def bar(): t.sleep(3) print("in the bar") def test2(func): print(func) return func #返回函数的内存地址 #调用test2函数 bar = test2(bar) bar() #没有bar函数改变调用方式 #输出结果 <function bar at 0x03570810> #bar函数的内存地址 in the bar
注:主要用于装饰器
五、函数式编程介绍
函数是Python内建支持的一种封装,我们通过把大段代码拆成函数,通过一层一层的函数调用,就可以把复杂任务分解成简单的任务,这种分解可以称之为面向过程的程序设计。函数就是面向过程的程序设计的基本单元。
函数式编程中的函数这个术语不是指计算机中的函数(实际上是Subroutine),而是指数学中的函数,即自变量的映射。也就是说一个函数的值仅决定于函数参数的值,不依赖其他状态。比如sqrt(x)函数计算x的平方根,只要x不变,不论什么时候调用,调用几次,值都是不变的。
Python对函数式编程提供部分支持。由于Python允许使用变量,因此,Python不是纯函数式编程语言。
一、定义
简单说,"函数式编程"是一种"编程范式"(programming paradigm),也就是如何编写程序的方法论。
主要思想是把运算过程尽量写成一系列嵌套的函数调用。举例来说,现在有这样一个数学表达式:
(1 + 2) * 3 - 4
传统的过程式编程,可能这样写:
var a = 1 + 2; var b = a * 3; var c = b - 4;
函数式编程要求使用函数,我们可以把运算过程定义为不同的函数,然后写成下面这样:
var result = subtract(multiply(add(1,2), 3), 4);
再演进以下,可以变成这样:
add(1,2).multiply(3).subtract(4)
函数式编程只是介绍,python 并不适合函数式编程,Erlang,Haskell更适合
装饰器本质是函数,是用来装饰其他函数,顾名思义就是,为其他的函数添加附件功能的。
不能修改被装饰函数的源代码
不能修改被装饰函数的调用方式
def logging(): print("logging...") # 正确写法,没有修改源码 def test1(): pass # 错误写法,不能修改源码 def test1(): pass logging() # 调用方式,也不能被修改 test1()
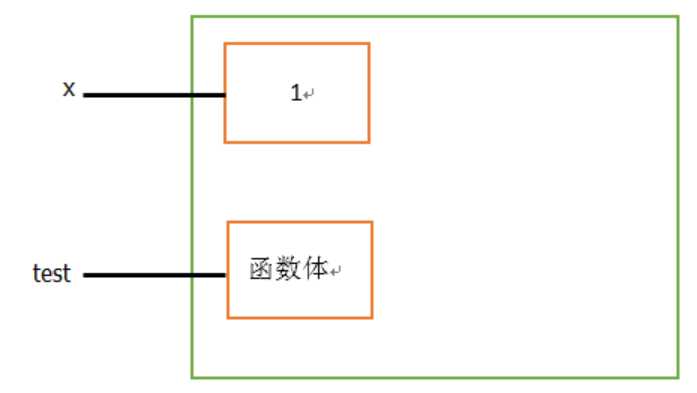
python的内存机制,看如下代码:
#变量 x = 1 #函数 def test(): pass
在内存图中是这样表示的:
x、test 是变量名,保存在栈内存中,1、函数体 保存在堆内存中
装饰器实现过程:
第一步:原始代码
def home(): print("----首页----") def TV(): print("----TV----") def music(): print("----music----")
第二步:想给部分模块加个登陆认证
user_status = False # 用户登录了就把这个改成True def login(): _username = "ABC" # 假装这是DB里存的用户信息 _password = "12345" # 假装这是DB里存的用户信息 global user_status if user_status == False: username = input("user:") password = input("pasword:") if username == _username and password == _password: print("welcome login....") user_status = True else: print("wrong username or password!") else: print("用户已登录,验证通过...") def home(): print("----首页----") def TV(): login() # 执行前加上验证 print("----TV----") def music(): print("----music----")
虽然这样实现了认证功能,但是修改了被装饰函数的源代码,违背了装饰器的原则”不能修改被装饰函数的源代码“
第三步:代码改进,使用高阶函数理念,把函数名当参数传递给认证函数login,这样可以不修改被装饰函数源代码的情况下完成登陆认证
user_status = False # 用户登录了就把这个改成True def login(func): _username = "ABC" # 假装这是DB里存的用户信息 _password = "12345" # 假装这是DB里存的用户信息 global user_status if user_status == False: username = input("user:") password = input("pasword:") if username == _username and password == _password: print("welcome login....") user_status = True else: print("wrong username or password!") if user_status == True: print("用户已登录,验证通过...") func() #只要验证通过了,就调用相应功能 def home(): print("----首页----") def TV(): print("----TV----") def music(): print("----music----") login(TV) #需要验证就调用 login,把需要验证的功能 当做一个参数传给login
虽然这样可以不修改被装饰函数源代码的情况下完成登陆认证,但是违背了装饰器原则”修改了被装饰函数的调用方式“,本来被装饰函数只需要TV()就可调用,现在变成了login(TV)
第四步:代码改进,使用匿名函数理念,将login(TV)变成 TV = login(TV) ,将函数当成值,赋值给变量名TV,跟关键字def 重新定义了TV是一样的效果,不过这样还有一个问题, TV = login(TV)这个赋值过程中,就把函数TV给调用了,用户自己还没有调用,就自己自动调用肯定是不对的,这个时候需要用到嵌套函数的理念了,在认证函数login里面的再定义一个新函数login_inner,在login函数return(返回)login_inner函数名(对是return login_inner, 不是return login_inner(), 因为return 函数名 返回的是函数在栈内容的内存地址,return 函数名+() 返回的是该函数的执行结果) 这样在TV = login(TV)赋值的时候,TV赋值的就不是 login(TV)的执行结果了,赋值的值是login_inner的内存地址,等用户再调用的时候 就是TV(),这样就没有改变被装饰函数的调用方式了。
user_status = False #用户登录了就把这个改成True def login(func): #在login 里面增加一个嵌套函数,保证tv = login(tv)的时候 不会自己自动调用 tv函数 def login_inner(): _username = "ABC" #假装这是DB里存的用户信息 _password = "12345" #假装这是DB里存的用户信息 global user_status if user_status == False: username = input("user:") password = input("pasword:") if username == _username and password == _password: print("welcome login....") user_status = True else: print("wrong username or password!") if user_status == True: print("用户已登录,验证通过...") func() #只要验证通过了,就调用相应功能 return login_inner # return 函数名 返回的是函数在栈内容的内存地址,return 函数名+() 返回的是该函数的执行结果 def home(): print("----首页----") def TV(): print("----TV----") def music(): print("----music----") home() #login(TV) #改成下面的方式,这样就不会改变调用方式了 TV = login(TV) TV()
每次使用装饰器都这么麻烦?需要使用匿名函数重新赋值再调用?
第五步:其实可以把TV =login(TV),的赋值过程简化成在被装饰函数前@login 就好了,如下列代码:
user_status = False #用户登录了就把这个改成True def login(func): #在login 里面增加一个嵌套函数,保证tv = login(tv)的时候 不会自己自动调用 tv函数 def login_inner(): _username = "ABC" #假装这是DB里存的用户信息 _password = "12345" #假装这是DB里存的用户信息 global user_status if user_status == False: username = input("user:") password = input("pasword:") if username == _username and password == _password: print("welcome login....") user_status = True else: print("wrong username or password!") if user_status == True: print("用户已登录,验证通过...") func() #只要验证通过了,就调用相应功能 return login_inner # return 函数名 返回的是函数在栈内容的内存地址,return 函数名+() 返回的是该函数的执行结果 def home(): print("----首页----") @login def TV(): print("----TV----") def music(): print("----music----") home() TV()
import time as t # 定义装饰器函数 def timmer(func): # 把test1这个函数名作为参数传递进来 func=test1 # 定义装饰器中的内置函数 def deco(): start_time = t.time() func() # 相当于运行test1() stop_time = t.time() print("the func run time is %s" % (stop_time - start_time)) return deco # 装饰test1函数 @timmer # 相当于test1 = timmer(test1) def test1(): t.sleep(3) print("in the test1") # 直接执行test1函数 test1() #输出结果 in the test1 the func run time is 3.000622272491455
import time as t def timmer(func): # timmer(test1) func=test1 # 因为之前返回的是这个嵌套数的内存地址,如果这个嵌套函数不传入参数#的话,里面的func,就是被装饰函数本身就没有参数,这样就会报错 def deco(*args, **kwargs): # 传入非固定参数 start_time = t.time() func(*args, **kwargs) # 传入非固定参数 stop_time = t.time() print("the func run time is %s" % (stop_time - start_time)) return deco # 不带参数 @timmer # 相当于test1 = timmer(test1) def test1(): t.sleep(3) print("in the test1") # 带参数 @timmer def test2(name, age): print("name:%s,age:%s" % (name, age)) # 调用 test1() test2("zhangsan", 22) #输出结果 #test1 in the test1 the func run time is 3.0009164810180664 #test2 name:zhangsan,age:22 the func run time is 0.0
def timmer(func): # timmer(test1) func=test1 def deco(*args, **kwargs): res = func(*args, **kwargs) # 这边传入函数结果赋给res return res # 返回res return deco @timmer def test1(): # test1 = timmer(test1) print("in the test1") return "from the test1" # 执行函数test1有返回值 res = test1() print(res) #输出结果 in the test1 from the test1
# 本地验证 user, passwd = "zhangsan", "abc123" def auth(auth_type): # 传递装饰器的参数 print("auth func:", auth_type) def outer_wrapper(func): # 将被装饰的函数作为参数传递进来 def wrapper(*args, **kwargs): # 将被装饰函数的参数传递进来 print("wrapper func args:", *args, **kwargs) username = input("Username:").strip() password = input("Password:").strip() if auth_type == "local": if user == username and passwd == password: print("\033[32mUser has passed authentication\033[0m") res = func(*args, **kwargs) print("--after authentication") return res else: exit("Invalid username or password") elif auth_type == "ldap": pass return wrapper return outer_wrapper def index(): print("welcome to index page") @auth(auth_type="local") # 带参数装饰器 def home(): print("welcome to home page") return "from home" @auth(auth_type="ldap") # 带参数装饰器 def bbs(): print("welcome to bbs page") index() home() bbs()
通过列表生成式,直接去创建一个列表。但是收到内存的限制,列表的容量是有限的。如果我们在创建一个包含100万个元素的列表,甚至更多,不仅占用了大量的内存空间,而且如果我们仅仅需要访问前面几个元素时,那后面很大一部分的占用的空间都白白浪费掉了。这个并不是我们所希望看到的。所以就诞生了一个新的名词叫生成器:generator。
生成器的作用:列表的元素按某种算法推算出来,我们在后续的循环中不断推算出后续的元素,在python中,这种一边循环一边计算的机制,称之为生成器(generator)。
>>> m=[i*2 for i in range(10)] >>> print(m) [0, 2, 4, 6, 8, 10, 12, 14, 16, 18] #生成一个list >>> n = (i*2 for i in range(10)) >>> print(n) <generator object <genexpr> at 0x031A21F0> #生成一个generator
如果需要访问生成器n中的值,python2是通过next()方法去获得generator的下一个返回值,python3是通过__next__()去获得generator的下一个返回值:
#python 3的访问方式用__next__() >>> n.__next__() 0 >>> n.__next__() 2 >>> n.__next__() 4 >>> n.__next__() 6 >>> n.__next__() 8 >>> n.__next__() #没有元素时,则会抛出抛出StopIteration的错误 Traceback (most recent call last): File "<pyshell#4>", line 1, in <module> n.__next__() StopIteration #python2的访问方式用next() >>> n.next() #可以用n.next() 0 >>> next(n) #也可以用next(n) 2 >>> n.next() 4 >>> n.next() 6 >>> n.next() 8 >>> n.next() #没有元素时,则会抛出抛出StopIteration的错误 Traceback (most recent call last): File "<pyshell#4>", line 1, in <module> n.next() StopIteration
①generator保存的是算法,每次调用next方法时,就会计算下一个元素的值,直到计算到最后一个元素,如果没有更多元素,则会抛出StopIteration的错误。
②generator只记住当前位置,它访问不到当前位置元素之前和之后的元素,之前的数据都没有了,只能往后访问元素,不能访问元素之前的元素。
使用next方法去一个一个访问,不切实际,正确的方法是使用for循环去访问,因为generator也是可迭代对象,代码如下:
res = (i*2 for i in range(3)) #创建一个生成器 print(res) for i in res: #迭代生成器中的元素 print(i) #输出结果 <generator object <genexpr> at 0x03A121F0> 0 2 4
推算比较简单,但是推算的算法比较复杂,用类似列表生成式的for循环无法实现,那怎么办呢?比如下面一个例子,用列表生成式无法实现。
实现原理:除第一个和第二个数外,任意一个数都可由前两个数相加得到:1, 1, 2, 3, 5, 8, 13, 21, 34, ...,代码如下:
def fib(max): n, a, b = 0, 0, 1 while n < max: print(b) a, b = b, a + b n = n + 1 return fib(5)
虽然根据这种逻辑推算非常类似一个生成器(generator),但是其本质还是函数,下面演示通过关键字yield将函数转换成生成器。
def fib(max): n, a, b = 0, 0, 1 while n < max: yield b # 用yield替换print,把fib函数转化成一个生成器 a, b = b, a + b n = n + 1 return "----done---"
这就是生成器(generator)另外一种定义方法。如果一个函数中包含yield关键字,那么这个函数就不是一个普通的函数,而是一个生成器(generator)
f = fib(5) print(f) #输出结果 <generator object fib at 0x00DB29B0>
注:变成generator的函数,在每次调用next()的时候执行,遇到yield语句返回,再次执行时从上次返回的yield语句处继续执行。
f = fib(5) print(f.__next__()) print(f.__next__()) print(f.__next__()) print("我在干别的事情") print(f.__next__()) print(f.__next__()) # 访问的是最后一个元素 print(f.__next__()) # 没有多余的元素 #输出结果 Traceback (most recent call last): 1 1 2 我在干别的事情 3 5 print(f.__next__()) # 没有多余的元素 StopIteration: ----done---
小结:
①访问生成器中的元素,不用是连续的,我可以中间去执行其他程序,向想什么时候执行,可以再回头去执行。
②return在这边作用就是当发生异常时,会打印ruturn后面的值。
生成器除了能节省资源,还能提高工作效率,如下列例子
A、第一个__next__方法
def consumer(name): print("%s 准备吃包子啦!" % name) while True: baozi = yield print("包子[%s]来了,被[%s]吃了" % (baozi, name)) c = consumer("zhangsan") c.__next__() #输出结果 zhangsan 准备吃包子啦
B、再加一个__next__方法
def consumer(name): print("%s 准备吃包子啦!" % name) while True: baozi = yield print("包子[%s]来了,被[%s]吃了" % (baozi, name)) c = consumer("zhangsan") c.__next__() c.__next__() #输出结果 zhangsan 准备吃包子啦! 包子[None]来了,被[zhangsan]吃了
A方案没有执行"print("包子[%s]来了,被[%s]吃了"%(baozi,name))",这段代码,接下来我们就来调试一下。
第一步:生成一个生成器

第二步:执行第一个__next__()方法进入函数,执行到yield时中断,把返回值返回给baozi这个变量:
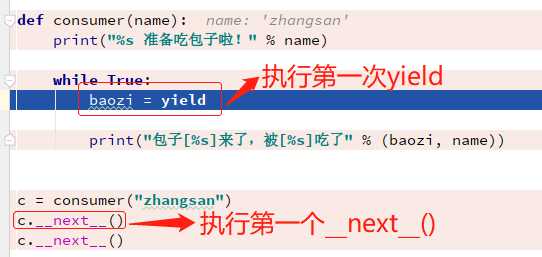
第三步:开始执行下面的程序,也就执行到了第二个__next__()方法,直接跳转到yield这边,继续上一次的中断往下执行,这样就执行了yield下面的程序,当再次执行到yield关键字时,则继续中断,并且把返回值赋给baozi关键字,如果下面没有其他程序,则程序结束。

小结:
def consumer(name): print("%s 准备吃包子啦!" % name) while True: baozi = yield print("包子[%s]来了,被[%s]吃了" % (baozi, name)) c = consumer("zhangsan") c.__next__() # 不使用__next__()方法会报错 b1 = "肉松馅" c.send(b1) # 调用yield,同时给yield传一个值 b2 = "韭菜馅" c.send(b2) #输出结果 zhangsan 准备吃包子啦! 包子[肉松馅]来了,被[zhangsan]吃了 包子[韭菜馅]来了,被[zhangsan]吃了
从上面可以看出send()和__next__()方法的区别:
为什么给消费者传值时,必须先执行__next__()方法?
因为如果不执行一个__next__()方法,只是把函数变成一个生成器,你只有__next__()一下,才能走到第一个yield,然后就返回了,调用下一个send()传值时,才会发包子。
yield还有一个更强大的功能,就是:单线程实现并发效果。
import time def consumer(name): print("%s 准备吃包子啦!" % name) while True: baozi = yield print("包子[%s]来了,被[%s]吃了" % (baozi, name)) def producer(name): c = consumer("A") c2 = consumer("B") c.__next__() c2.__next__() print("老子准备吃包子啦!") for i in range(10): time.sleep(1) print("做了一个包子,分两半") c.send(i) c2.send(i) producer("zhangsan")
8.1.1、for循环数据类型
8.1.2、定义
可迭代对象(Iterable):直接用于for循环遍历数据的对象
8.1.3、用isinstance()方法判断一个对象是否是Iterable对象
>>> from collections import Iterable >>> print(isinstance([],Iterable)) #列表 True >>> print(isinstance((),Iterable)) #元组 True >>> print(isinstance({},Iterable)) #字典 True >>> print(isinstance(‘abc‘,Iterable)) #字符串 True >>> print(isinstance(100,Iterable)) #整型
注:生成器不但可以作用于for循环,还可以被__next__()函数不断调用,并且返回下一个值,直到最后抛出StopIteration错误表示无法继续返回下一个值而抛出的异常。
8.2.1、定义
迭代器(Iterator):可以用__next__()函数调用并不断的返回下一个值的对象称为迭代器。
8.2.2、用isinstance()方法判断一个对象是否是Iterator对象
>>> from collections import Iterator >>> print(isinstance((i*2 for i in range(5)),Iterator)) #生成器 True >>> print(isinstance([],Iterator)) #列表 False >>> print(isinstance({},Iterator)) #字典 False >>> print(isinstance(‘abc‘,Iterator)) #字符串 False
通过上面的例子可以看出,生成器都是Iterator对象,但是list、dict、str虽然是Iterable对象,却不是Iterator对象。
8.2.3、iter()函数
功能:把list、dict、str等Iterable对象变成Iterator对象。
>>> from collections import Iterator >>> print(isinstance(iter([]),Iterator)) True >>> print(isinstance(iter({}),Iterator)) True
8.2.4、为什么list、dict、str等数据类型不是Iterator?
这是因为python的Iterator对象表示的是一个数据流,Iterator对象可以被__next__()函数调用并不断返回下一个数据,直到没有数据时抛出StopIteration错误。可以把这个数据流看做是一个有序序列,但我们却不能提前知道序列的长度,只能不断通过__next__()函数实现按需计算下一个数据,所以Iterator的计算是惰性的,只有在需要返回下一个数据时才会计算。
注:Iterator甚至可以表示一个无限大的数据流,例如:全体自然数。而使用list是永远不可能存储全体自然数的。
小结:
Iterable类型。Iterator类型,它们表示一个惰性计算的序列。Iterable但是不是Iteratoriter()函数获得一个Iterator对象。python--递归函数、匿名函数、嵌套函数、高阶函数、装饰器、生成器、迭代器
标签:包括 变量 第一步 装饰器 %s 语言 sea 另一个 并发
原文地址:https://www.cnblogs.com/doumingyi/p/12452896.html
