标签:style size 一起 有一个 分割 吞吐量 span info font
DDB设计的两个问题
1)分段 – 分割关系成“段” ;逻辑上
2)分配 – 将段置放到站点 ;物理存储上
• 目标 – 优化响应时间/吞吐量/费用/…
分段元则
假若有全局关系R 被分段为子关系(片段)集合,
– 完整性,分片之后,不能丢失元素
– 不相交性,每一个元素只能分配到唯一的一个分段
– 重构性,存在函数 g 使得 R = g(F1 , F2 , …, Fn )。
也就是通过分片,能够还原出原来的数据总体
水平分段
把不同性质的元组,分割为不同的分段
基本水平分段
以关系E自身的属性性质为基础,执行“选择”操作,将关系分割成若干个不相交的片段
例如:
对于学生表,根据班级编号这一性质,将学生元组分割多个片段。
如何选择小项谓词
什么小项谓词?


小项谓词就是划分条件的各种可能的组合,比如:
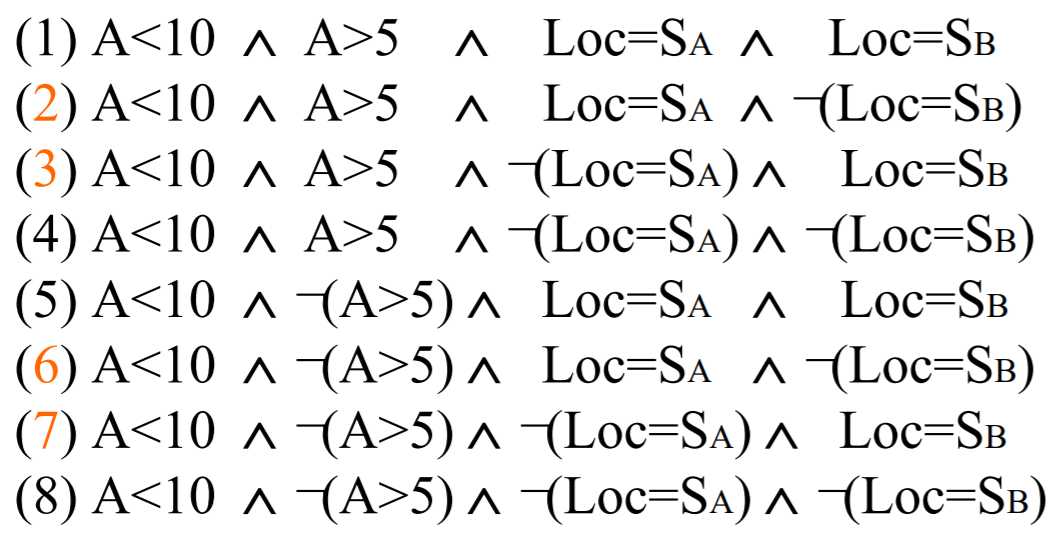
但是上面的小项谓词,相当大一部分都是不符合语义的,因为没有实际的数据对应这些小项谓词。
还是回到刚才的那个问题:如何选择小项谓词集作为分段的依据呢?
仍然是以例子来说话:

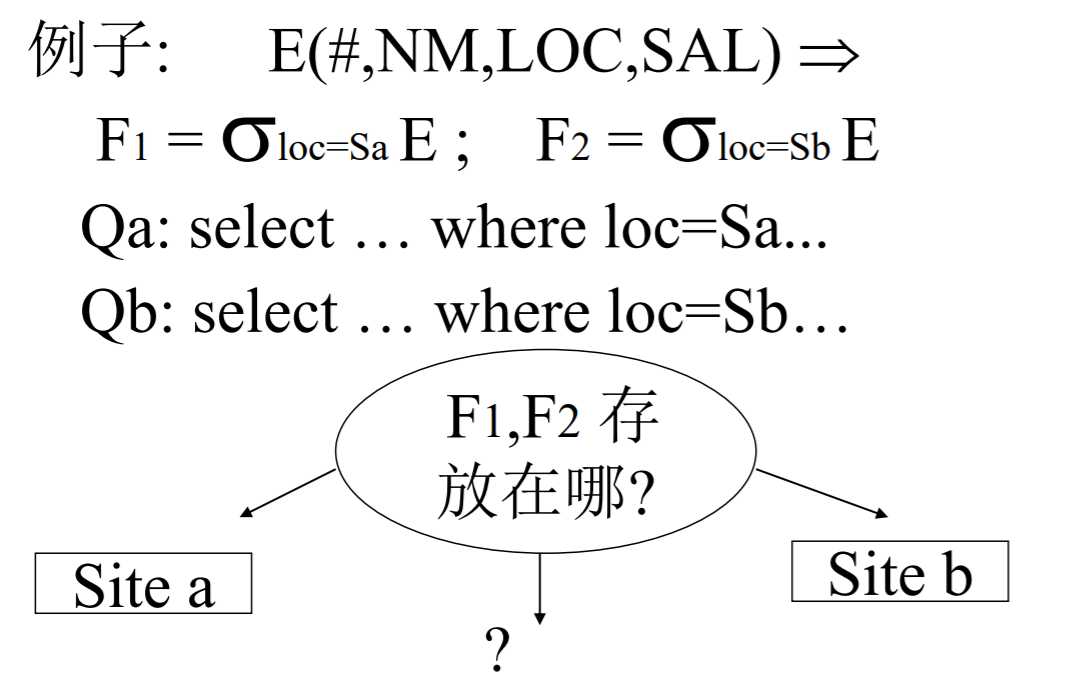
应用a访问Loc = Sa 的元组;应用b则访问Loc = Sb的元组。

(1)不分段
(2)按照{Loc = sa,loc = sb}来分段,分两段
(3)按照{loc = sa,loc = sb,sal < 10}来分段,分4端;
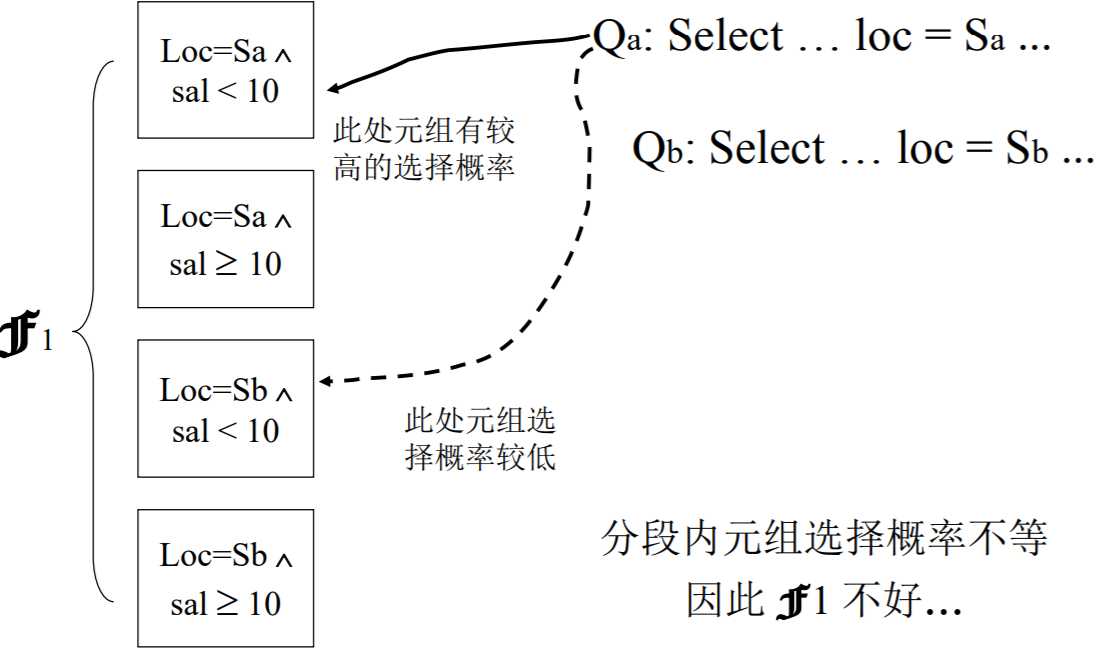
只有一个分段的话,对一个特定的应用,分组内的元组选择概率不相等,因此不好。比如:对于应用a,它只会选择loc = sa的元组,而不选择loc = sb的元组。元组选择的概率不等,因此不好。
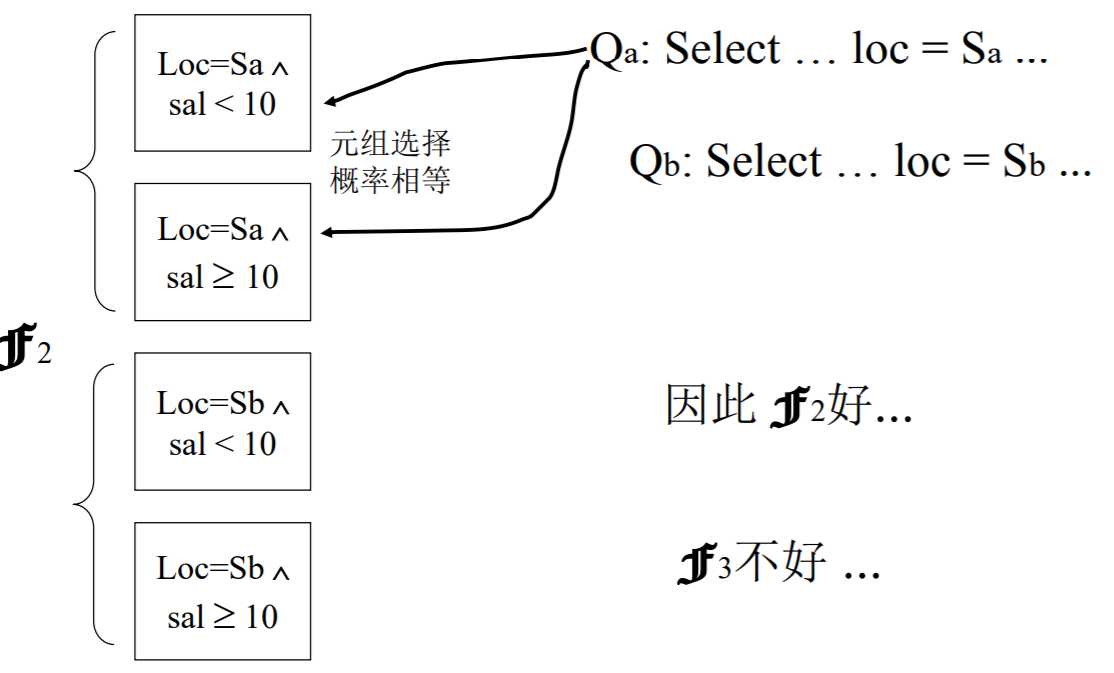
对于分成四个分段的方案,由于对于同一个应用,两个分段选择的概率是相等的,这样也不好。
所以最理想的情形是:对每个特定的应用,最好能把它所要访问的所有元组集中在一个分段,而且只是一个分段(小项性)
导出分段
从另一个关系的属性性质或水平分段推导出来。
比如有选课表和学生表,
SC(S#, C#, GRADE)
S ( S#, SNAME. AGE, SEX)
按照学生表中的性别属性,将SC表拆分成两个分段,SC1,SC2,分别存储的是男生和女生的选课信息。

一般如何来实现导出分段呢?半连接操作

也就是在连接操作的基础上,进行投影操作,筛选出R的属性。它的意义在于在R中筛选出能够与S进行连接的元组而过滤出无用的元组。
以学生-选课表为例,先将学生表根据性别划分成两个分段S1,S2,再让SC分别与S1和S2进行半连接操作即可。
注意:导出分段的完整性和不相交性不能得到保证,除非(学生表是导出表,选课表是被导出表):
1)导出属性在导出表中是主键;
2)满足引用约束(属性如果存在于被导出表,则必须也存在于导出表);
垂直分段
通过“投影”操作把一个全局关系的属性分成若干组 。垂直分段的基本目标是将使用频繁的属性聚集在一起。
垂直分段,保证重构性的方式就是在每个分段中都保留主关键字。这样,通过自然连接操作可重构出原来的数据整体。
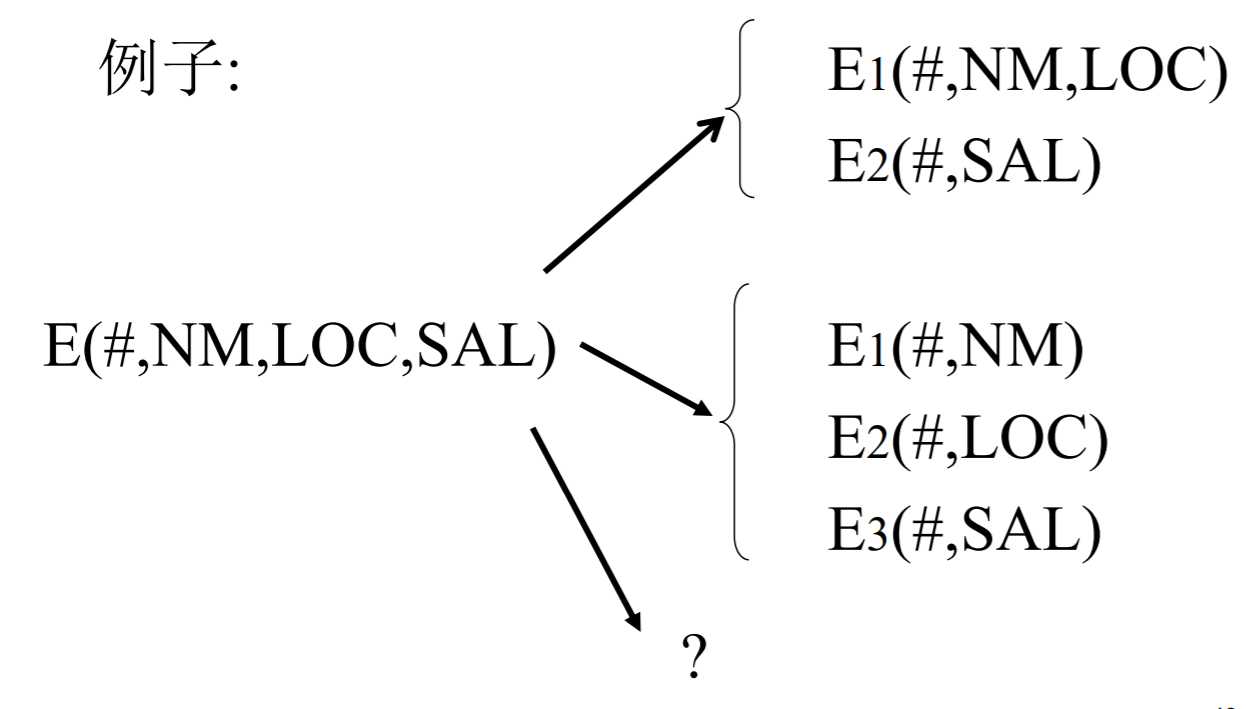
如何来进行垂直分段?
通过属性的亲和矩阵

就是找出所有这样的应用:它既访问了判断A1又访问了片段A2,把他们的频率之和相加。
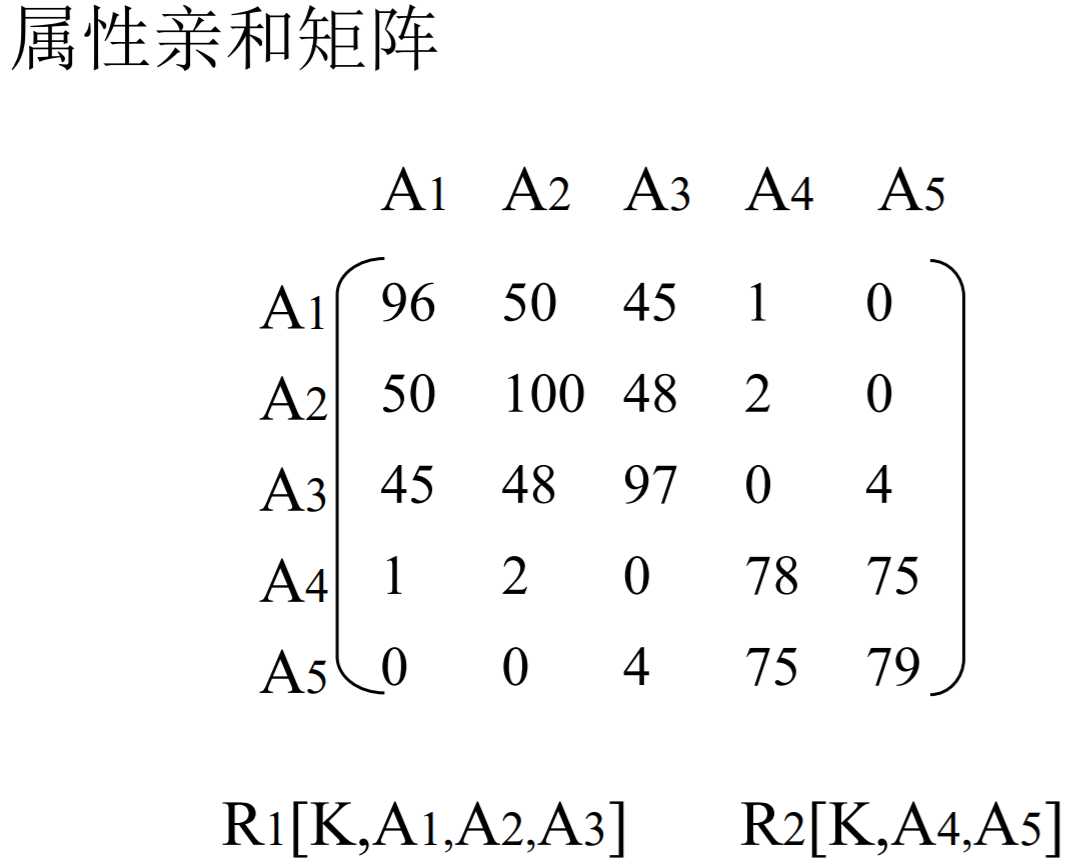
要通过行列调整寻找分割点
混合分段
先水平分段,再垂直分段;
先垂直分段,再水平分段。
分配
在满足用户需求的前提下, 把设计好的数 据片段分配到相应的站点上存储
分配的有关问题
查询来源
通讯费用? 结果大小, 关系,…
存储容量, 存储费用? 分段大小?
站点处理能力?
查询处理策略? – 连接操作算法 – 查询结果收集站点
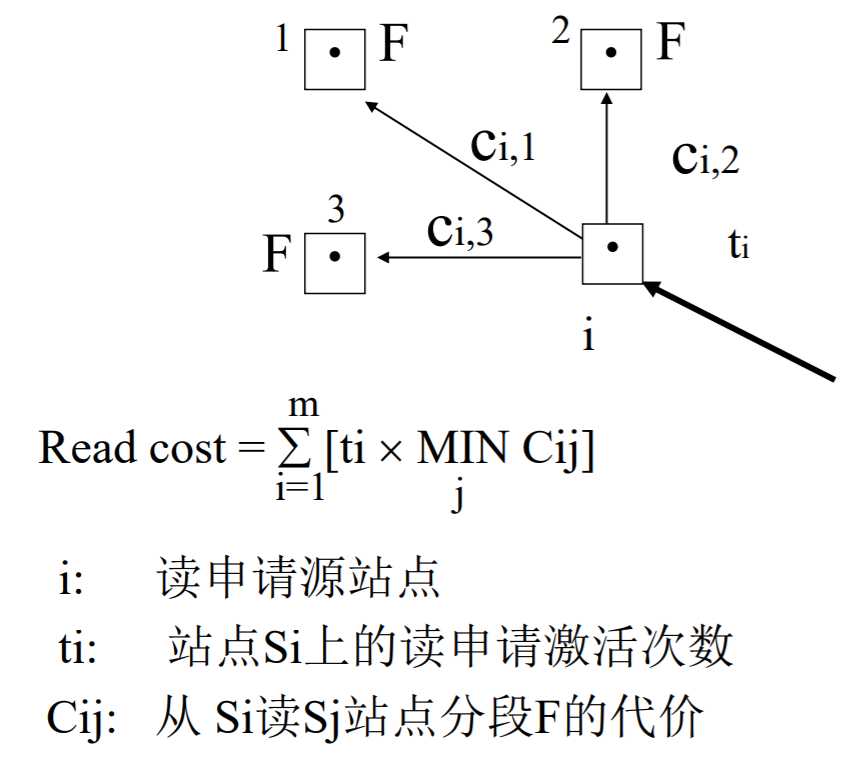
简化模型如下:

读的代价为:
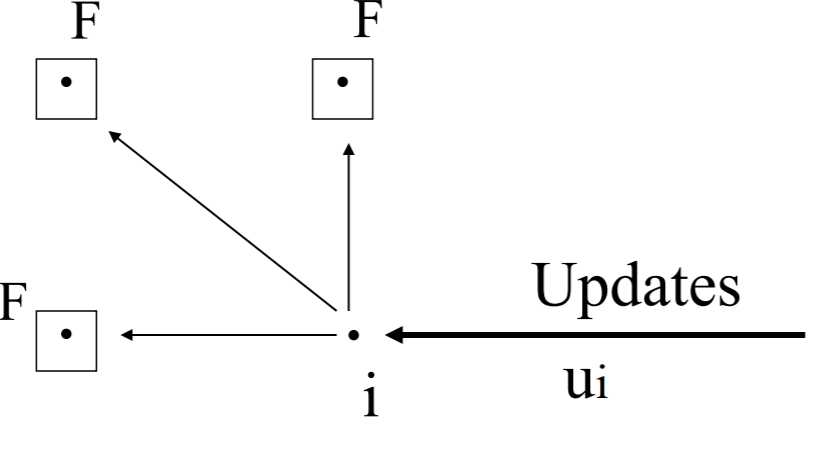
写代价:

存储代价如下:

最后得目标函数:
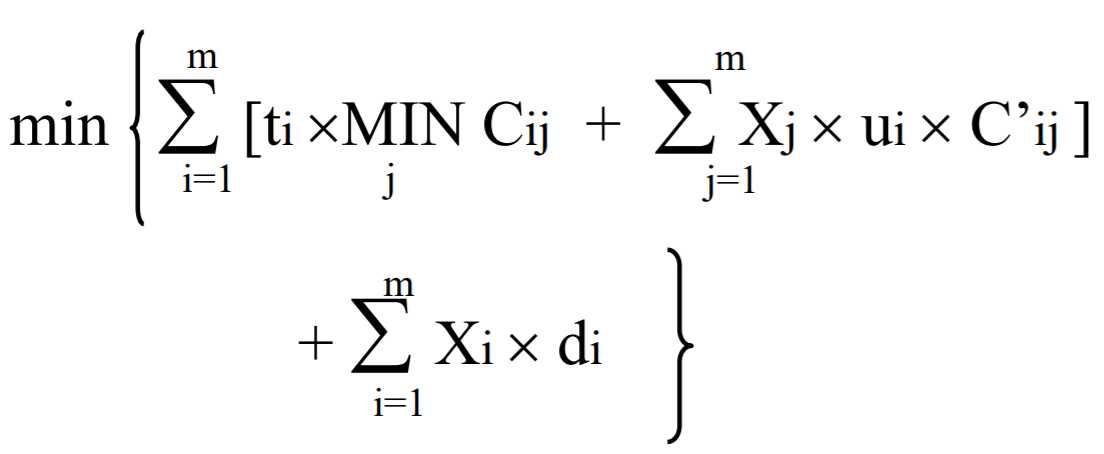
要计算出这个目标函数的值,是一个NP难问题。
所以采用一个简单的法则:尽可能将片段分配在被局部访问位置,即尽量做到本地化的访问。
最佳适应方法

充分考虑到了应用的访问次数,哪个站点的B最大,就把片段分配到哪个站点。
所有得益站点方法
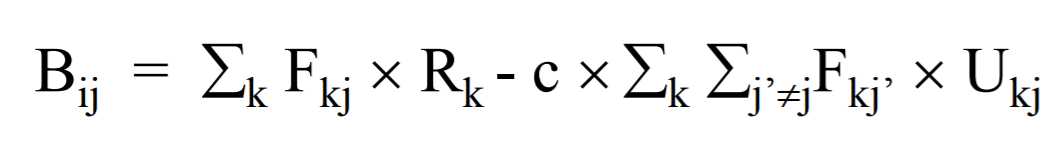
进一步考虑到了写的代价。
标签:style size 一起 有一个 分割 吞吐量 span info font
原文地址:https://www.cnblogs.com/chxyshaodiao/p/12460427.html