标签:无法 重复 name inter card enc pytho remove 报错
集合、list、tuple、dict一样都可以存放多个值,但是集合主要用于:去重、关系运算
friends1 = ["zero", "kevin", "jason", "egon"]
friends2 = ["Jy", "ricky", "jason", "egon"]
l = []
for x in friends1:
if x in friends2:
l.append(x)
print(l)
['jason', 'egon']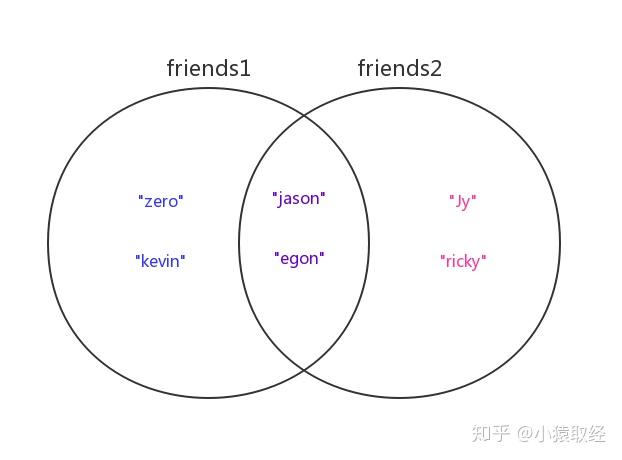
# 1.合集/并集(|):求两个用户所有的好友(重复好友只留一个)
>>> friends1 | friends2
{'kevin', 'ricky', 'zero', 'jason', 'Jy', 'egon'}
# 2.交集(&):求两个用户的共同好友
>>> friends1 & friends2
{'jason', 'egon'}
# 3.差集(-):
>>> friends1 - friends2 # 求用户1独有的好友
{'kevin', 'zero'}
>>> friends2 - friends1 # 求用户2独有的好友
{'ricky', 'Jy'}
# 4.对称差集(^) # 求两个用户独有的好友们(即去掉共有的好友)
>>> friends1 ^ friends2
{'kevin', 'zero', 'ricky', 'Jy'}
# 5.值是否相等(==)
>>> friends1 == friends2
False
# 6.父集:一个集合是否包含另外一个集合
# 6.1 包含则返回True
>>> {1,2,3} > {1,2}
True
>>> {1,2,3} >= {1,2}
True
# 6.2 不存在包含关系,则返回False
>>> {1,2,3} > {1,3,4,5}
False
>>> {1,2,3} >= {1,3,4,5}
False
# 7.子集
>>> {1,2} < {1,2,3}
True
>>> {1,2} <= {1,2,3}
True集合去重复有局限性:
# 1. 只能针对不可变类型
# 2. 集合本身是无序的,去重之后无法保留原来的顺序>>> l=['a','b',1,'a','a']
>>> s=set(l)
>>> s # 将列表转成了集合
{'b', 'a', 1}
>>> l_new=list(s) # 再将集合转回列表
>>> l_new
['b', 'a', 1] # 去除了重复,但是打乱了顺序
# 针对不可变类型,并且保证顺序则需要我们自己写代码实现,例如
l=[
{'name':'lili','age':18,'sex':'male'},
{'name':'jack','age':73,'sex':'male'},
{'name':'tom','age':20,'sex':'female'},
{'name':'lili','age':18,'sex':'male'},
{'name':'lili','age':18,'sex':'male'},
]
new_l=[]
for dic in l:
if dic not in new_l:
new_l.append(dic)
print(new_l)
# 结果:既去除了重复,又保证了顺序,而且是针对不可变类型的去重
[
{'age': 18, 'sex': 'male', 'name': 'lili'},
{'age': 73, 'sex': 'male', 'name': 'jack'},
{'age': 20, 'sex': 'female', 'name': 'tom'}
]定义:在{}内用逗号分隔开多个元素,集合具备以下三个特点:
1:每个元素必须是不可变类型
2:集合内没有重复的元素
3:集合内元素无序s = {1,2,3,4} # 本质 s = set({1,2,3,4})
# 注意1:列表类型是索引对应值,字典是key对应值,均可以取得单个指定的值,而集合类型既没有索引也没有key与值对应,所以无法取得单个的值,而且对于集合来说,主要用于去重与关系元素,根本没有取出单个指定值这种需求。
# 注意2:{}既可以用于定义dict,也可以用于定义集合,但是字典内的元素必须是key:value的格式,现在我们想定义一个空字典和空集合,该如何准确去定义两者?
d = {} # 默认是空字典
s = set() # 这才是定义空集合了解
s = {} # 默认是空字典
print(type(s))定义空集合
s = set()
print(s, type(s))# 但凡能被for循环的遍历的数据类型(强调:遍历出的每一个值都必须为不可变类型)都可以传给set()转换成集合类型
s = set([1,2,3,4])
s1 = set((1,2,3,4))
s2 = set({'name':'jason',})
s3 = set('egon')
s,s1,s2,s3
{1, 2, 3, 4} {1, 2, 3, 4} {'name'} {'e', 'o', 'g', 'n'}=========================关系运算符=========================
两者共同的好友
friends1 = {"zero", "kevin", "jason", "egon"}
friends2 = {"Jy", "ricky", "jason", "egon"}
res = friends1 & friends2
print(res)
print(friends1.intersection(friends2))
{'jason', 'egon'}
{'jason', 'egon'}两者所有的好友
friends1 = {"zero", "kevin", "jason", "egon"}
friends2 = {"Jy", "ricky", "jason", "egon"}
print(friends1 | friends2)
print(friends1.union(friends2))
{'egon', 'zero', 'jason', 'kevin', 'Jy', 'ricky'}
{'egon', 'zero', 'jason', 'kevin', 'Jy', 'ricky'}取friends1独有的好友
friends1 = {"zero", "kevin", "jason", "egon"}
friends2 = {"Jy", "ricky", "jason", "egon"}
print(friends1 - friends2)
print(friends1.difference(friends2))
{'kevin', 'zero'}
{'kevin', 'zero'}取friends2独有的好友
friends1 = {"zero", "kevin", "jason", "egon"}
friends2 = {"Jy", "ricky", "jason", "egon"}
print(friends2 - friends1)
print(friends2.difference(friends1))
{'ricky', 'Jy'}
{'ricky', 'Jy'}求两个用户独有的好友们(即去掉共有的好友)
friends1 = {"zero", "kevin", "jason", "egon"}
friends2 = {"Jy", "ricky", "jason", "egon"}
print(friends1 ^ friends2)
print(friends1.symmetric_difference(friends2))
{'ricky', 'Jy', 'kevin', 'zero'}
{'ricky', 'Jy', 'kevin', 'zero'}不存在包含关系,下面比较均为False
s1 = {1, 2, 3}
s2 = {1, 2, 4}
print(s1 > s2)
print(s1 < s2)
False
Falses1 = {1, 2, 3}
s2 = {1, 2}
print(s1 > s2) # 当s1大于或等于s2时,才能说是s1是s2他爹
print(s1.issuperset(s2))
print(s2.issubset(s1)) # s2 < s2 =>True
True
True
Trues1 = {1, 2, 3}
s2 = {1, 2, 3}
print(s1 == s2) # s1与s2互为父子
print(s1.issuperset(s2))
print(s2.issuperset(s1))
True
True
True其他内置方法
需要掌握的内置方法1:discard
s={1,2,3}
s.discard(4) # 删除元素不存在do nothing
print(s)
s.remove(4) # 删除元素不存在则报错需要掌握的内置方法2:update
s = {1, 2, 3}
s.update({1, 3, 5})
print(s)
{1, 2, 3, 5}需要掌握的内置方法3:pop
s = {1, 2, 3}
res = s.pop()
print(res)
1需要掌握的内置方法4:add
s = {1, 2, 3}
s.add(4)
print(s)
{1, 2, 3, 4}标签:无法 重复 name inter card enc pytho remove 报错
原文地址:https://www.cnblogs.com/x945669/p/12471948.html