标签:www ade for idt chrome art ret 字段 继承
1.创建爬虫

1 cmd-cd desktop scrapy startproject top250
2.修改访问表头UA
将setting文件里的USER_AGENT和COOKIES_ENABLED前面的#去掉
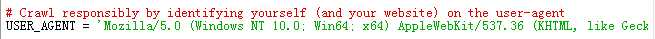
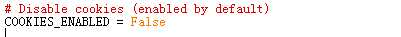
3.定义item容器
1 # -*- coding: utf-8 -*- 2 # Define here the models for your scraped items 3 # 4 # See documentation in: 5 # https://docs.scrapy.org/en/latest/topics/items.html 6 import scrapy 7 class Top250Item(scrapy.Item): 8 # define the fields for your item here like: 9 # name = scrapy.Field() 10 title=scrapy.Field() 11 link=scrapy.Field() 12 desc=scrapy.Field()
4.打开top250\top250\spiders,创建新文件top250spider.py
1 import scrapy 2 class DmozSpider(scrapy.Spider):#继承自类 3 name="dmoz"#必须唯一 4 allowed_domains=["dmoz-odp.org"]#爬取的网址(域名)范围,是一个列表 5 start_urls=[ 6 "https://www.dmoz-odp.org/Computers/Programming/" 7 ]#开始页面,当前页面 8 def parse(self,response):#定义一个方法用于分析,唯一参数response 9 filename=response.url.split("/")[-2]#写并保存一个文件 10 with open(filename,"wb")as f: 11 f.write(response.body)#返回网页的body内容
1 #!/usr/bin/python3 2 #-*-coding:UTF-8-*- 3 import scrapy 4 import sys 5 import time 6 sys.path.append("..") 7 from top250.items import Top250Item 8 9 class Top250Spider(scrapy.Spider): 10 name="top250" 11 allowed_domains=["www.douban.com"] 12 start_urls=["https://movie.douban.com/top250"] 13 custom_settings = { 14 "DEFAULT_REQUEST_HEADERS":{ ‘User-Agent‘: ‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36‘}, 15 } 16 yield item 17 def parse(self,response): 18 sel=scrapy.selector.Selector(response)#response为参数 19 sites=sel.xpath("//li/div/div[2]") 20 items=[] 21 for site in sites: 22 item=Top250Item() 23 item[‘title‘]=site.xpath("div[1]/a/span[1]/text()").extract() 24 item[‘link‘]=site.xpath("div[1]/a/@href/text()").extract() 25 item[‘desc‘]=site.xpath("div[2]/div/text()").extract() 26 items.append(item) 27 return items
5.在cmd窗口中cd top250
1 scrapy crawl dmoz(domz为在spider文件夹中dmozspider的name,显示200则成功,在tutorial1文件夹中出现一个新的文件(内部是该网页的源代码)
1 输入scrapy shell “url”(url为网址链接,显示view response in a browser即为成功)
1 response.body(显示该url网页的所有代码) 2 response.headers
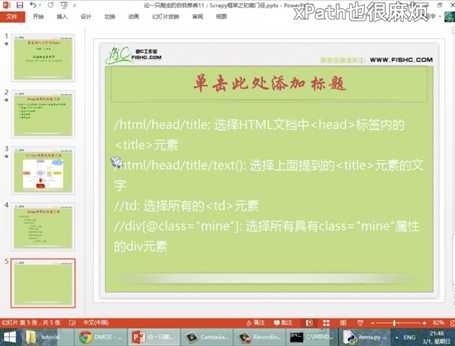
xpath方法介绍
6.extract()和text()
1 response.selector.xpath==response.xpath(所以用的时候直接用后者就好) 2 response.xpath(“//title”)返回title,是一个列表,一个网页只有一个 3 [<Selector xpath=‘//title‘ data=‘<title>DMOZ - Computers: Programming<...‘>] 4 response.xpath(“//title”).extract() 将title列表字符串化 5 [‘<title>DMOZ - Computers: Programming</title>‘] 6 response.xpath(“//title/text()”).extract()得到title列表字符串化后的文字,不要标签 7 [‘DMOZ - Computers: Programming‘]
7.获取所需内容的节点路径,在cmd中打印测试
1 From scrapy import Selector 2 sel=Selector(response) 3 sel.xpath(“//div/a”)打印所有标签为//div/a的网页 4 sel.xpath(“//div/a/text()”) 所有标签为//div/a的文字描述内容 5 sel.xpath("//div/a/text()").extract()所有标签为//div/a的文字描述内容字符串化 6 sel.xpath("//div/a/@href").extract()返回该标签下的所有网址链接 7 8 sites=sel.xpath(‘//*[@id="site-list-content"]‘)这里的xpath地址来自网页标签右键-copy xpath 9 for site in sites: 10 title=site.xpath(‘div/div[3]/a/div/text()‘).extract() 11 print(title)
8.形成最终的spider文件
9.执行生成json文件
若导出为中文,需修改setting和设置pipelines
为了启用一个Item Pipeline组件,你必须将它的类添加到 ITEM_PIPELINES 配置,就像下面这个例子: ITEM_PIPELINES = { ‘myproject.pipelines.PricePipeline‘: 300, ‘myproject.pipelines.JsonWriterPipeline‘: 800, >} 分配给每个类的整型值,确定了他们运行的顺序,item按数字从低到高的顺序,通过pipeline,通常将这些数字定义在0-1000范围内。 当Item在Spider中被收集之后,它将会被传递到Item Pipeline,一些组件会按照一定的顺序执行对Item的处理。 每个item pipeline组件(有时称之为“Item Pipeline”)是实现了简单方法的Python类。他们接收到Item并通过它执行一些行为,同时也决定此Item是否继续通过pipeline,或是被丢弃而不再进行处理。 以下是item pipeline的一些典型应用: 清理HTML数据 验证爬取的数据(检查item包含某些字段) 查重(并丢弃) 将爬取结果保存到数据库中
1 也就是说json.dump函数将获取到item转化成字符串中存入json文件,并且 将参数ensure_ascii设为False使得中文(UTF-8编码)不经过转义,也就不会乱码
1 # Configure item pipelines 2 # See http://scrapy.readthedocs.org/en/latest/topics/item-pipeline.html 3 # ITEM_PIPELINES = { 4 # ‘tutorial.pipelines.TutorialPipeline‘: 300, 5 6 7 8 改为(实际上就是把#去掉让它生效) 9 # Configure item pipelines 10 # See http://scrapy.readthedocs.org/en/latest/topics/item-pipeline.html 11 ITEM_PIPELINES = { 12 ‘tutorial.pipelines.TutorialPipeline‘: 300, 13 }
1 def *_item(self, item, spider): 2 3 with open(‘data_cn1.json‘, ‘a‘) as f: 4 json.dump(dict(item), f, ensure_ascii=False) 5 f.write(‘,\n‘) 6 return item
scrapy crawl dmoz -o(导出) items.json(文件名) -t(导出形式为-t)json
标签:www ade for idt chrome art ret 字段 继承
原文地址:https://www.cnblogs.com/lianghaiming/p/12488712.html
