标签:code hold csdn The 执行 原创文章 编写 功能 语法
首先看看委托的常见的使用情景:定义一个委托、使用刚定义的委托声明一个委托变量、根据需要将方法和该变量绑定,最后在合适的地方使用它。代码形式如下:
//定义委托 public delegate void SomeDelegate(); class SomeClass { public void InstanceFunction() { //Do something } public static void StaticFunction() { //Do something } } public class SomeUserClass { public void SomeAction() { //声明委托变量 SomeDelegate del; SomeClass someClass = new SomeClass(); //绑定到实例方法 del = someClass.InstanceFunction; //使用它 del(); //绑定到静态方法 del = SomeClass.StaticFunction; //再次使用它 del(); } }
先不谈委托的其他用途,通过上面的例子,可以将委托简单理解为一个“方法类型”。可将委托声明的变量和与委托签名相符的方法绑定,之后就可以像使用方法一样使用这个变量。
委托是安全封装方法的类型,类似于 C 和 C++ 中的函数指针。 与 C 函数指针不同的是,委托是面向对象的、类型安全的和可靠的。 委托的类型由委托的名称确定。——来自MSDN
上面的做法是将委托变量del分别与一个实例方法和一个静态方法绑定。这两种方式都被称作使用命名方法。
在 C# 1.0 中,通过使用在代码中其他位置定义的方法显式初始化委托来创建委托的实例。 C# 2.0 引入了匿名方法的概念,作为一种编写可在委托调用中执行的未命名内联语句块的方式。 C# 3.0 引入了 lambda 表达式,这种表达式与匿名方法的概念类似,但更具表现力并且更简练。 这两个功能统称为匿名函数。 通常,面向 .NET Framework 3.5 及更高版本的应用程序应使用 lambda 表达式。——来自MSDN
我个人是更加偏好于使用Lambda表达式,至于匿名方法,用法几乎与Lambda表达式一样。下文的示例代码中我都将用更加简洁的Lambda表达式来书写。Lambda表达式可以参考MSDN——Lambda表达式
使用Lambda表达式初始化委托
在这一节,先看看Func<TResult>,可以参考MSDN——Func 委托得到更多信息。
Func<TResult>实际上是.net封装好的一个委托,它不接受参数、返回一个TResult类型的值。
比如我们可以通过如下代码来声明一个Func<int>的变量、并为其绑定一个方法、然后使用它:
public class AnotherClass{ //声明委托变量 private Func<int> funcInt; private int info; //声明符合Func<int>签名的函数 private int FunctionReturnsInt() { return info; } private void SomeUserFunction() { //将方法绑定至委托变量 funcInt = FunctionReturnsInt; //通过变量调用方法 int result = funcInt(); //Do something } }
对于上面的代码,如果改用Lambda表达式,就会简洁很多,如下:
public class AnotherClass{ //声明委托变量 private Func<int> funcInt; private int info; private void SomeUserFunction() { //将Lambda表达式绑定至委托变量 funcInt = () => { return info; }; //通过变量调用方法 int result = funcInt(); //Do something } }
使用Lambda表达式省掉了书写命名方法的过程,代码看起来更加清新。然而,稍不注意,Lambda表达式就会“毁灭”你的代码。
在Lambda表达式“毁灭”你的代码前,先看看下面的代码会输出什么:
List<Func<int>> funcs = new List<Func<int>>(); for (int i = 0; i < 3; i++) { funcs.Add(() => { return i; }); } foreach(var item in funcs) { Console.WriteLine(item().ToString()); }
对于不理解闭包的人,第一反应自然是输出0、1、2。但事实上,它输出的是3、3、3。造成这种“出人意料”的结果的原因,就是闭包。
关于闭包,这里不作过多、过复杂的介绍,想要深入了解,可以查阅相关资料。
简单地讲,闭包是一个代码块(在C#中,指的是匿名方法或者Lambda表达式,也就是匿名函数),并且这个代码块使用到了代码块以外的变量,于是这个代码块和用到的代码块以外的变量(上下文)被“封闭地包在一起”。当使用此代码块时,该代码块里使用的外部变量的值,是使用该代码块时的值,并不一定是创建该代码块时的值。
一句话概括,闭包是一个包含了上下文环境的匿名函数。
有点拗口,不过暂且先根据这个解释,我们回去看看上面的代码。
代码中的Lambda表达式(代码块)() => { return i; },使用了for循环中的循环变量i。
在for循环中,我们通过Lambda表达式(代码块)创建了三个匿名函数、并添加进委托列表中;当for循环结束后,我们逐个调用与委托列表绑定的三个匿名函数。
在调用这三个匿名函数时,虽然for循环已经结束,其控制变量i也“看起来不存在了”,但事实是,变量i已经被加入到上面每一个匿名函数各自的上下文中,也就是说,上面的三个匿名函数,都“闭包”着变量i。
此时i的值已经等于3,于是这三个匿名函数都将返回3并交给Console去输出。
为了看清楚后台究竟发生了什么,用Visual Studio自带的IL Disassembler打开编译出的exe文件,查看结果。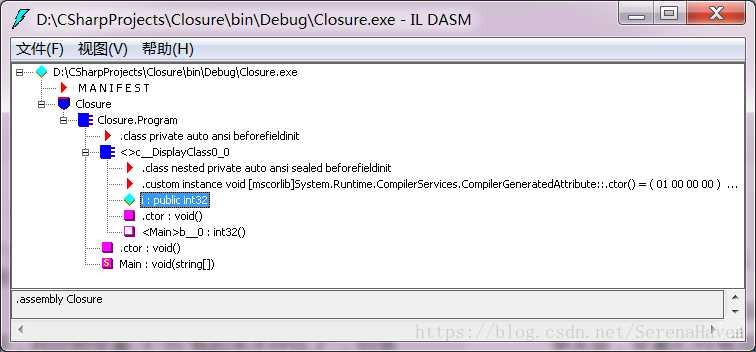
对于闭包,编译的结果是:编译器为闭包生成了一个类,i作为一个公共的字段存在于其中。
也就是说,虽然for循环已经结束,但是i仍然以一种“看不见”的方式活跃在内存中。所以当我们调用这三个匿名函数时,使用的都将是同一个i(指的是变量,而不是它具体的值)。
接下来修改代码如下:
List<Func<int>> funcs = new List<Func<int>>(); for (int i = 0; i < 3; i++) { int j = i; funcs.Add(() => { return j; }); } foreach(var item in funcs) { Console.WriteLine(item().ToString()); }
再次运行,输出结果为0、1、2。分析下原因。
在每一次循环时,我们都创建了一个新的变量j。为了区分每一次循环中的j,第一次循环时,我称它为j0,此时它从i中获得的值为0,并且本次循环中,创建了一个匿名函数并使用了j0,形成了一个闭包。在第二次循环时,将创建另一个变量j1,此时它从i中获得的值为1,此循环中的匿名函数将使用变量j1,形成另一个闭包;第三次循环类似。
一下子豁然开朗了。在这次的代码中,三个匿名函数使用的j并不是同一个变量,所以会有后面的结果。
还是先看一段代码:
List<int> values = new List<int>() {0,1,2 }; List<Func<int>> funcs = new List<Func<int>>(); foreach (var item in values) { funcs.Add(() => { return item; }); } foreach(var item in funcs) { Console.WriteLine(item().ToString()); }
这段代码的输出是0、1、2。看起来似乎与前面所讲的有矛盾。
在C# 5.0之前的版本,在foreach的循环中,将会共用一个item,这段代码的输出就是2、2、2;C# 5.0之后,foreach的实现方式作了修改,在每一次循环时,都会产生一个新的item用来存放枚举器当前值,所以此时的情形类似于上面for循环的第二种情形。
再看一段代码:
class Program { static void Main(string[] args) { Console.WriteLine("Program start"); ShowMemory(); Console.WriteLine("Create object"); SomeClass someClass = new SomeClass(); ShowMemory(); Console.WriteLine("Call function"); someClass.SomeFunction(); ShowMemory(); Console.WriteLine("Release delegate"); someClass.func = null; ShowMemory(); } private static void ShowMemory() { GC.Collect(); Console.WriteLine("Memory used : " + GC.GetTotalMemory(true)); Console.WriteLine("--------------------------------------------------"); Console.ReadKey(); } public class MemoryHolder { public byte[] data; public int info; public MemoryHolder() { data = new byte[10 * 1024 * 1024]; info = 100; Console.WriteLine("MemoryHolder created"); } ~MemoryHolder() { Console.WriteLine("MemoryHolder released"); } } public class SomeClass { public Func<int> func; public void SomeFunction() { MemoryHolder holder = new MemoryHolder(); func = () => { return holder.info; }; Console.WriteLine("Function exited"); } } }
看看运行结果:
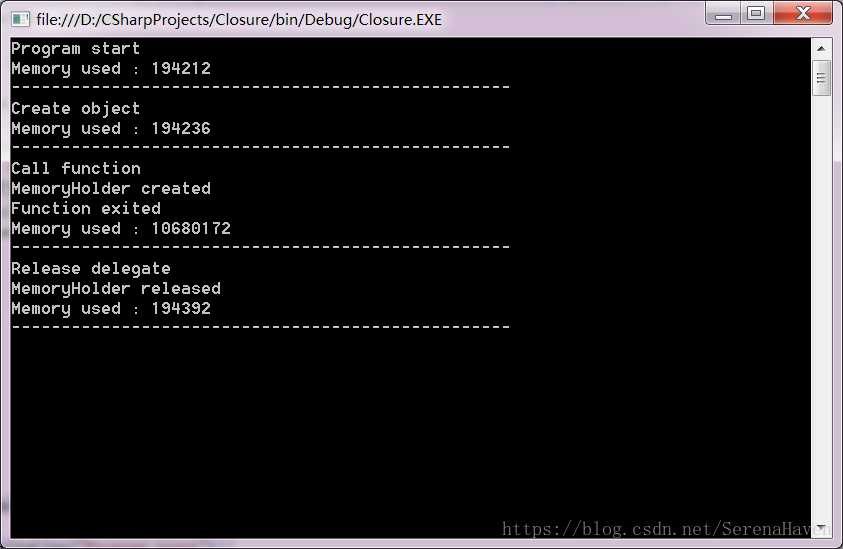
可以看出,原本在SomeFunction调用结束时就应该被释放的MemoryHolder对象,并没有被释放,而是在使用它的闭包被释放时,才真正被释放掉。也就是说,闭包会延长它使用的外部变量的生命周期,直到闭包本身被释放。
那么闭包会不会造成内存泄漏?
我认为只有不严谨的代码才会造成内存泄漏。正如上述代码中的someClass.func或者someClass对象、在不需要它(们)的时候没有被正确释放它(们),就会造成了本该被销毁的holder对象不会被正确地被销毁、自然也就造成了内存泄漏。但是不应该让闭包背这个锅。
1、匿名函数是个语法糖,很方便,但是也容易带来问题。
2、如果一定要使用闭包,那么切记做好内存的回收。
3、养成良好的代码习惯。
————————————————
版权声明:本文为CSDN博主「SerenaHaven」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/SerenaHaven/article/details/80047622
标签:code hold csdn The 执行 原创文章 编写 功能 语法
原文地址:https://www.cnblogs.com/gougou1981/p/12490534.html