标签:脚本批量 网站 root intro cer 下载 哪个网站 name 做事
说实话,php能看懂,写的话就再需要熟悉一下语法。python建站需要从头开始。包括模板、cms、都没有php下的wordpress多。插件上也是wordpress有绝对的优势。自己一直写的python后台,前端页面放个一两年真是连个毛都不剩下了。仔细考虑了一些,还是决定使用wordpress搭建自己的小博客玩一玩。随便下载了一个wordpress,本地搭建起来后,分析了一下wordpress数据库表的关系。把几个主要的表格梳理了一下,以下是简单的记录。(非专业php,仅从后端角度简单分析,如有大师路过,勿喷)。
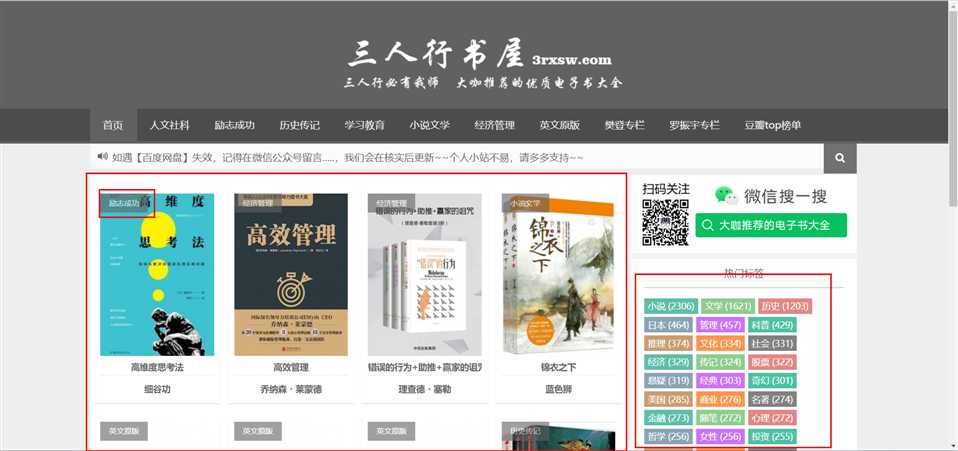
这个网站用插件分析了一下,用的是GIt主题。页面的主要分析点截图中标红框-文章目录、文章、文章标签。涉及的表有:wp_terms、wp_posts、wp_term_taxonomy、wp_term_ralationships.
这几个表的功能分别是:
wp_posts:文章存储表。主要字段:ID-自增ID。post_title-文章的标题。post_excerpt-文章简介
? wp_terms: 标签、目录的存储表。term_id-自增id。name-标签或目录的名称。slug-urlencode后的内容。
? wp_term_taxonmy: 目录、标签的描述信息,主要字段:term_taxonomy_id-该表的自增id,term_id-对应上面的wp_terms的term_id,taxonomy- 目录或者标签(category or post_tag),count:计数器,对应截图中的标签下的数字。
wp_term_relationships: wp_terms 和 wp_posts的关联表。也就是说,这张表决定了一篇文章就是是什么目录,有什么标签。主要字段:object_id - 对应的是wp_posts中的ID。term_taxonomy_id对应的是wp_term_taxonomy中的term_taxonomy_id。object_id、term_taxonomy_id 是多对多的关系。
文章分析是基于在wordpress中实际编辑文章及目录标签等,然后观察每个表格的变化,分析较为简单粗暴。但是基本上能够作为二次开发的基础使用了。
说是二次开发,其实并没有什么具体的目标,没想好建立什么网站。就当前期的热身活动,熟悉和验证结论是否正确。我还是使用我最熟悉的python作为开发语言。
具体哪个网站就不透露了。大多数网站这都有我们所需的元素。使用python简单编写了scrapy爬虫(简单点的直接用requests爬了),我们需要用到的素材均作单独字段存储。
我推荐比较好的做法是使用sqlalchemy对源数据表和wp数据表进行建模。然后根据wp各个表的关系做事务插入。即使用一个session对上面提到的几个表做完整性的数据插入。
这里推荐一个快速生成数据模型的工具,配合sqlalchemy使用事半功倍。sqlacodegen
具体操作方法:
1. pip install sqlacodegen
2. sqlacodegen --outfile=models.py mysql://root:guess@192.168.1.250:3306/test第二部操作是对整个库的建模,当然也可以选择对某张表进行建模。
sqlacodegen --outfile=models.py mysql://root:guess@192.168.1.250:3306/test --tables teacher,student我具体的处理逻辑,部分伪代码如下(写的太乱,只能拿出部分伪代码献丑了)
post = spider_session.query(SpiderData).filter(SpiderData.id == 1) # 从爬虫库中选出一条
...
# wordpress 数据库插入
wp_post = WpPost()
wp_post.post_title = post.article_name
wp_post.post_content = post.content
wp_post.post_excerpt = post.short_introduction
wp_post.post_status = "publish"
session_wp.add(wp_post)
session_wp.commit()
# 一下是wp_terms表,term表可以提前把标签和分类先做插入,这里只做查询
terms = spider_session.query(SpiderData).filter(SpiderData.id == 1).all()
# 插入wp_terms
for term in terms:
# 在wp_terms 中找到这个标签对应的id。前提是你已经插入。
term_id = session_wp.query(WpTerm).filter(WpTerm.name == term.name).first()
# 对wp_term_relationships进行处理
object_id = wp_post.ID
wp_relationship = WpTermRelationships()
wp_relationship.object_id = object_id
wp_relationship.term_id = term_id
session_wp.add(wp_relationship)
session_wp.commit()以上代码只是提供思路实际应用中注意异常处理等。
写这篇文章的时候距离完成我的小demo网站已经有一段时间了。方向是技术博客类型。
还能想起但是第一次接触wordpress时的一脸懵逼,沉下心研究一段时间你就会发现,原来很多事情在你全力做了之后就会变得很简单。
以上。
标签:脚本批量 网站 root intro cer 下载 哪个网站 name 做事
原文地址:https://www.cnblogs.com/zzcpy/p/12491348.html