标签:nice des 开发 inf epo 这一 roc blank ESS
Github项目地址:https://github.com/shishukon/wc.exe/
wc.exe 是一个常见的工具,它能统计文本文件的字符数、单词数和行数。这个项目要求写一个命令行程序,模仿已有wc.exe 的功能,并加以扩充,给出某程序设计语言源文件的字符数、单词数和行数。
实现一个统计程序,它能正确统计程序文件中的字符数、单词数、行数,以及还具备其他扩展功能,并能够快速地处理多个文件。
具体功能要求:
程序处理用户需求的模式为:
wc.exe [parameter] [file_name]
基本功能列表:
wc.exe -c file.c //返回文件 file.c 的字符数
wc.exe -w file.c //返回文件 file.c 的词的数目
wc.exe -l file.c //返回文件 file.c 的行数
扩展功能:
-s 递归处理目录下符合条件的文件。
-a 返回更复杂的数据(代码行 / 空行 / 注释行)。
空行:本行全部是空格或格式控制字符,如果包括代码,则只有不超过一个可显示的字符,例如“{”。
代码行:本行包括多于一个字符的代码。
注释行:本行不是代码行,并且本行包括注释。一个有趣的例子是有些程序员会在单字符后面加注释:
} //注释
在这种情况下,这一行属于注释行。
[file_name]: 文件或目录名,可以处理一般通配符。
高级功能:
-x 参数。这个参数单独使用。如果命令行有这个参数,则程序会显示图形界面,用户可以通过界面选取单个文件,程序就会显示文件的字符数、行数等全部统计信息。
需求举例:
wc.exe -s -a *.c
返回当前目录及子目录中所有*.c 文件的代码行数、空行数、注释行数。
使用的编程语言:python;
使用工具及库:pycharm,os,re,tkinter;
使用的新知识:文件的读取,简单ui界面的编写,git base的使用;
思路:根据题目来看,涉及的问题主要有通过命令进行功能选择、文件的定位与读取、文本信息的提取、可视界面的设计,一个功能接着一个功能的完成完善。
根据我的思路,我先后完成的是命令识别、基础需求函数、拓展需求函数、GUI界面。
命令识别用的是最笨的字符串截取,例如指令-c test.txt,通过截取得到-c,test.txt, .txt三个部分,分别对应的是指令关键字,文件名,文件拓展名;接下来是函数的编写,函数的参数由四部分组成,文件路径path,文件名target,文件拓展名file_extension,模式model,model参数是为了识别-s参数。GUI界面通过python的tkinter实现,(最初设想的是gui也调用函数文件中的函数,但由于函数功能简单,直接在gui文件中重写了一遍,有投机取巧的嫌疑)。
1、实现功能选择
存在问题:由于语言知识掌握不够,只想到一种简单的思路。
print(‘输入进行操作的路径‘) path = input() print(‘输入命令:‘) str1 = input() point = str1.find(‘.‘) # 文件拓展名 file_extension = str1[point:] if str1[0:2] == ‘-s‘: # 文件名 target = str1[6:] # 指令名 order = str1[3:5] model = ‘-s‘ else: # 文件名 target = str1[3:] # 指令名 order = str1[0:2] model = ‘normal‘ if order == ‘-c‘: wf.c(path, target, file_extension, model) elif order == ‘-w‘: wf.w(path, target, file_extension, model) elif order == ‘-l‘: wf.l(path, target, file_extension, model) elif order == ‘-a‘: wf.a(path, target, file_extension, model) elif order == ‘-x‘: os.system("GUI.py") else: print(‘非法输入‘)
2、获取用户所查找的文件
# 获取目录下所有后缀为txt的文件和它的路径 def file_name(path, extension): l1 = [] l2 = [] for root, dirs, files in os.walk(path): for file in files: # 指定后缀的文件并将路径与文件名存入列表中 if os.path.splitext(file)[1] == extension: l1.append(file) l2.append(root) return l1, l2 # 找到用户所选择的文件并返回它的路径 def find_target(path, target, extension, model=‘‘): count = -1 filename, root = file_name(path, extension) for i in filename: count = count + 1 # 查找文件 if target == i: return os.path.join(root[count], filename[count]) # 返回文件绝对路径
3、基本功能的实现(包含拓展功能s)
存在问题:三个功能的主体基本无差别,可以整合为一个函数以节约资源,事先未考虑到,应该在设计之初更周全的考虑。
# 功能c def c(path, target, file_extension, model): # s模式 if model == ‘-s‘: # 获取目录下文件名以及其路径 filename, root = file_name(path, file_extension) # 对列表中的每一个文件进行操作 for i in range(len(filename)): file_path = os.path.join(root[i], filename[i]) file = open(file_path, encoding="UTF-8") list2 = file.read() print(filename[i], ‘:Char number->‘, len(list2.replace(‘\n‘, ‘‘))) # 普通模式 else: # 获取目录下文件名以及其路径 file_path = find_target(path, target, file_extension) file = open(file_path, encoding="UTF-8") list1 = file.read() print(‘Char number->‘, len(list1.replace(‘\n‘, ‘‘))) # 功能w def w(path, target, file_extension, model): # s模式 if model == ‘-s‘: # 获取目录下文件名以及其路径 filename, root = file_name(path, file_extension) # 对列表中的每一个文件进行操作 for i in range(len(filename)): file_path = os.path.join(root[i], filename[i]) file = open(file_path, encoding="UTF-8") print(filename[i], ‘:word number->‘, len(re.split(r‘[^a-zA-Z]+‘, file.read()))) # 普通模式 else: # 获取目录下文件名以及其路径 file_path = find_target(path, target, file_extension) file = open(file_path, encoding="UTF-8") print(‘word number->‘, (len(re.split(r‘[^a-zA-Z]+‘, file.read()))-1)) # 功能l def l(path, target, file_extension, model): # s模式 if model == ‘-s‘: filename, root = file_name(path, file_extension) for i in range(len(filename)): file_path = os.path.join(root[i], filename[i]) file = open(file_path, encoding="UTF-8") print(filename[i], ‘:line number->‘, (len(file.readlines()))) # 普通模式 else: file_path = find_target(path, target, file_extension) file = open(file_path, encoding="UTF-8") print(‘line number->‘, len(file.readlines()))
4、拓展功能a的实现
# 功能a def a(path, target, file_extension, model): code_line = 0 blank_line = 0 comment_line = 0 if model == ‘-s‘: filename, root = file_name(path, file_extension) for i in range(len(filename)): # 计数清零,进行下一轮统计 code_line = 0 blank_line = 0 comment_line = 0 file_path = os.path.join(root[i], filename[i]) file = open(file_path, encoding="UTF-8") for line in file.readlines(): line = line.strip() # 空行统计 if not len(line): blank_line += 1 # 注释统计 elif line.startswith(‘#‘): comment_line += 1 elif line.startswith(‘//‘): comment_line += 1 # 代码行统计 elif len(line) > 1: code_line += 1 print(filename[i], ‘blank_line->‘, blank_line, ‘, comment_line->‘, comment_line , ‘, code_line->‘, code_line) else: file_path = find_target(path, target, file_extension) file = open(file_path, encoding="UTF-8") for line in file.readlines(): # 去除空格 line = line.strip() # 空行统计 if not len(line): blank_line += 1 # 注释统计 elif line.startswith(‘#‘): comment_line += 1 elif line.startswith(‘//‘): comment_line += 1 # 代码行统计 elif len(line) > 1: code_line += 1 print(‘blank_line->‘, blank_line, ‘, comment_line->‘, comment_line , ‘, code_line->‘, code_line)
5、GUI功能实现
存在问题:第一次接触UI界面编写,没有深入学习,据同学了解tkinter这个库是比较不好用的,后续会学习更多的可视界面编写工具
def enterorder(): order = en.get() btn = Button(tiw, text="choose your file", command=choose_file(order)) btn.pack() # 选择文件 def choose_file(order): global tiw file_path = filedialog.askopenfilename() f(order, file_path) # 实现基本操作 def f(order, file_path): global tiw out_put = Listbox(tiw) if order == ‘-c‘: file = open(file_path, ‘r‘) list1 = file.read() str_out = (‘Char number->‘, len(list1.replace(‘\n‘, ‘‘))) elif order == ‘-w‘: file = open(file_path, ‘r‘) str_out = (‘word number->‘, len(re.split(r‘[^a-zA-Z]+‘, file.read()))) elif order == ‘-l‘: file = open(file_path, ‘r‘) str_out = (‘line number->‘, len(file.readlines())) out_put.insert(0, str_out) out_put.pack() tiw = Tk() tiw.title("wc.exe") tiw.geometry("400x300") en = Entry(tiw, show=None) en.pack() btn = Button(tiw, text="输入指令", command=enterorder).pack() la = Label(tiw).pack() tiw.mainloop()
测试用文件
路径:D:\Project\wc\
文件夹结构
#test #------test.c #-------test1 #-----------test1.c #-------test2 #-----------test2.c
# test_funtion_a
# ------ typical.c # -------1 # -----------typical1.c # -------2 # -----------typical2.c
文件内容
test.c:
hello,how are you?
uhh,not bad.
cool.
test1.c:
hey,nice to meet you.
me too.
test2.c:
hello,how old are you?
what?
1、基础功能测试
test1.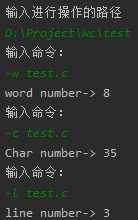 test2.
test2. test3.
test3.
2、拓展功能测试
(1)功能s: 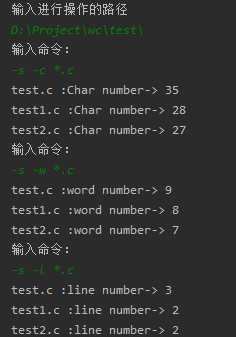
(2)功能a: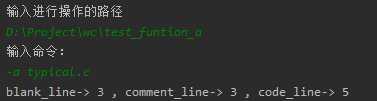
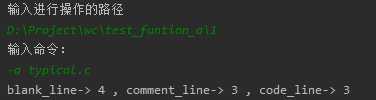
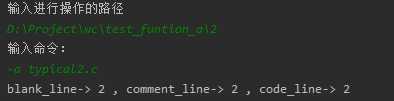
(3)功能a和s的组合: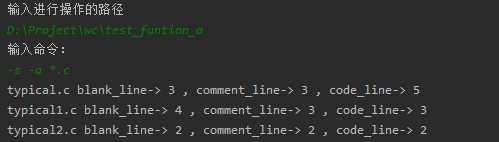
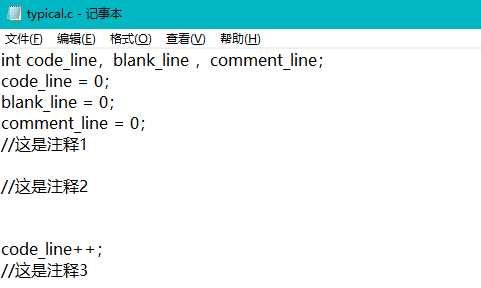
3、用于测试功能a的文件内容:


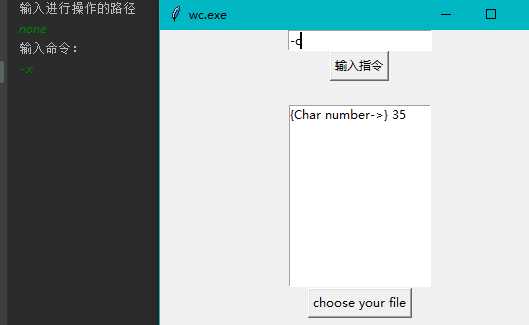
4、GUI界面
|
PSP2.1 |
Personal Software Process Stages |
预估耗时(分钟) |
实际耗时(分钟) |
|
Planning |
计划 |
|
|
|
· Estimate |
· 估计这个任务需要多少时间 |
20 |
20 |
|
Development |
开发 |
|
|
|
· Analysis |
· 需求分析 (包括学习新技术) |
150 |
200 |
|
· Design Spec |
· 生成设计文档 |
30 |
30 |
|
· Design Review |
· 设计复审 (和同事审核设计文档) |
20 |
20 |
|
· Coding Standard |
· 代码规范 (为目前的开发制定合适的规范) |
20 |
20 |
|
· Design |
· 具体设计 |
30 |
40 |
|
· Coding |
· 具体编码 |
550 |
700 |
|
· Code Review |
· 代码复审 |
60 |
120 |
|
· Test |
· 测试(自我测试,修改代码,提交修改) |
50 |
50 |
|
Reporting |
报告 |
|
|
|
· Test Report |
· 测试报告 |
60 |
80 |
|
· Size Measurement |
· 计算工作量 |
10 |
15 |
|
· Postmortem & Process Improvement Plan |
· 事后总结, 并提出过程改进计划 |
20 |
20 |
|
合计 |
|
1000 |
1295 |
1、遇到的问题:
(1)对语言的不熟练:需要不停的测试各种库函数,导致了很多时间的浪费,很多细节问题,像没注意到readline()函数和readlines()函数的细微区别、编码格式不同等,都浪费了不少时间来反复测试和修改;
(2)计划不够周详:因为急于上手没有事先定好完整框架,有了个大概就开始写,导致写到一半才想起有功能没有加,期间不断地更改函数的构造,带来的是一轮轮全新的凶猛的debug;
(3)git的初次接触:笨手笨脚覆盖掉了本地的代码,花了好长时间来恢复,对精神和身体的双重重击!
2、感想:
最大的感想是:计划很重要!计划很重要!计划很重要!!没有完整的计划会使得自己在开发途中不断碰壁,一会儿是需求加不上去,一会儿是功能不够全面,所以问题的解决都是伤筋动骨,事倍功半,一个完善的计划可以让开发顺利进行,减少不必要的卡顿和浪费,这是保护头发的重中之重。
标签:nice des 开发 inf epo 这一 roc blank ESS
原文地址:https://www.cnblogs.com/iggydog/p/12491827.html