标签:加速 插件 联网 集群架构 大型网站 net class 技术 ini
目录
=======================================================================
张贺,多年互联网行业工作经验,担任过网络工程师、系统集成工程师、LINUX系统运维工程师
笔者微信:zhanghe15069028807,现居济南历下区
=======================================================================
?# 基础概念
memcached是什么?有什么作用?
memcached是一个工作在内存的nosql的数据库,通常有两个作用,第一个作用是部署在real server集群的后端后做session server,存储用户的session信息,这样无论客户端调度到哪一台real server,都能够保持与客户端之前的会话。第二个作用是部署在关系型数据库的前端,做关系型数据库的缓存,其目的提升数据库的访问性能,加速网站集群动态应用服务的能力。
memcached服务在企业集群架构中应用场景
1.作为数据库的前端缓存应用
(1)做完整缓存,例如将商品分类,以及商品信息,可事先放到内存里面,然后再对外提供数据访问,这个被称之为预热。用户访问时可以只读取mecached缓存,不读取数据库了。
(2)做热点缓存,需要前端程序配合,只缓存热点的数据,即缓存经常被访问的数据。先预热基础数据,然后再动态更新,先读取缓存,如果缓存当中没有对应的数据,再去找数据库,然后把读到的数据放入缓存。
特殊说明:如果碰到电商秒杀等高并发的业务,一定要事先预热,或者其他思路实现,例如,秒杀只是获取资格,而不是瞬间秒杀到商品;如果数据更新,同时触发缓存更新,防止给用户过期数据;对于持久化缓存存储系统,例如redis,可以替代一部分数据库的存储,比如一些简单的数据业务,像是投票、统计,好友关注等。
2.作为集群的session会话共享存储。
memcache服务在不同企业业务应用场景中的工作流程。
读:当web程序需要访问后端数据库获取数据时会优先访问memcache的内存缓存,如果缓存中有效数据就直接获取返回给前端服务,如果没有命中,在由程序请求后端的数据库服务器,获取到对应的数据后,除了返回给前端服务及用户之外,还会把数据放到memcache中进行缓存,等待下次请求被访问,memcache内存始终是数据库的挡箭牌,从而大大的减轻数据库的访问压力,提高整个网站架构的响应速度,提升了用户体验。
写:当程序更新时,修改或删除数据库中已有的数据时,程序会同时发送请求通知memcache已经缓存过的同一个ID内容的旧数据失效,从而保证memcache中的数据和数据库的数据一致。如果是在高并发场合,除了通知memcache过程的缓存失效外,还会通过相关机制,使得在用户访问新数据前,通过程序预先把更新过的数据推送到memcache中缓存起来,这样可以减少数据库的访问压力,提升memcache中缓存的命中率。
更新:有一款数据库插件可以再写入更新数据之后,自动抛给memcache缓存起来,自身不cache,类似inotify。
memcache服务分布式集群如何实现?
特殊说明:memcached集群和web服务集群是不一样的,所有memcached的数据总和才是数据库的数据,每台memcache都是部分数据。
a:程序端实现
程序加载所有memcache的ip列表,可以对用户的cookie,id,ip、url做hash当key,做一致性hash算法决定将会话存到哪一台memcache之上,取亦是如此。
b:通过负载均衡器
通过key做一致性hash
Memcached服务特点及原理是什么?
a.C/s模式架构, C语言编写,总共2000多行代码。.
b.异步1O模型,使用libevent作为事件通知机制。
c.被缓存的数据以key/value键值形式存在的。
d.全部数据存放于内存中,无持久性存储的设计,重启服务器,内存里的数据丢失。当内存中缓存的数据容量达到启动时设定的内存值时,就自动使用LRU算法删除过期的缓存数据。..
f.可以对存储的数据设置过期时间,这样过期后数据自动酸清除,服务本身不会监控过期,而是在访问的时候查看key的时间戳判断是否过期。..
g.memcache会对设定的内存进行分块,再把块分组,然后再提供服务。
varnish是属于一种代理式缓存,而memcached是一种旁挂式缓存。varnish通常部署在负载均衡和web集群的前端,当负载均衡向varnish发起请求时,如果varnish缓存里面没有,varnish要当作客户端去向后端web集群去取,取完之后又当服务器返回给负载均衡,即当爹又当妈,这其实和DNS的递归很相似,本地DNS代替客户端去查找域名对应的IP;而mecache这种旁挂式缓存是这样的,当客户端向自己发起查询时,如果memcache没有,memcache也不会帮助客户去查找,客户端一看指不上memcache,就自己去后端查找,查找完再放到memcache一份,实际上,应用程序可以提前根据hash判断出memcache到底有没有自己想要的数据。
防火墙的部署也是两种模式:串连和旁挂,varnish就是串连,memcache和redis就是旁挂。
memcahe的智能性,一半在客户端,一半在数据库。怎么理解呢?上面的这端段很好的解释了memcache的智能性一半在客户端,要缓存什么是客户端说了算(这里的客户端通常指的是程序),怎么理解memcache的智能性一半在数据库呢?像mysql或oracle这种关系型数据库,都有与memcache相关的插件,这种插件可以实现当数据库的数据有变化时可以自动通知memcache刷新数据。大部分应用都是程序上就实现了数据更新,不需要数据库参于。
memcache使用slab allocation(复用内存管理机制),有关于这种内存管理机制的如下:
在内存页的基础上将整个内存分割到大小相同的块(chunk),大小相同的块为一个组(class),比如2字节的块划分一些,4的字节的块也分配了一些,相同大小的块成一个组。数据来了之后,找一个与其最相近的块大小进行存储,当然不太可能是正正好好,缝隙是难免的。
为什么要在内存页的基础上进行重新分配chunk呢?直接用内存页不行吗?不太好,一个内存页是4K大小,存储一个2B的数据太浪费!所以在内存页上再划分,划分成一个又一个大小不同的chunk,每个chunk的大小由用户控制,回收的时候就直接回收这些chunk就可以了,这有点像宏杉存储的cell技术。这么做的好处很明显,当要缓存的数据来了之后不用临时切割了,因为提早就已经分配好了。
注意:在内存页的基础上进行分配chunk,一个内存页是4K,并不是说一个chunk大小不可能超过4k,一个chunk是可以使用多个内存页的,但是单个缓存数据不能超过1M。
malloc的全称是memory allocation,中文叫动态内存分配,当无法知道内存具体位置的时候,想要绑定真正的内存空间,就需要用到动态的分配内存。
早期的Memcached内存管理方式是通过malloc分配的内存,使用完后通过free来回收内存。这种方式容易产生内存碎片并降低操作系统对内存的管理效率。加重操作系统内存管理器的负担,最坏的情况下,会导致操作系统比memcached进程本身还慢,为了解决上述问题, Slab Allocation内存分配机制就诞生了。
现在的Memcached利用Slab Allocation机制来分配和管理内存
Slab Allocation机制原理是按照预先规定的大小,将分配给memcached的内存分割成特定长度的内存块(chunk) ,再把尺寸相同的内存块分成组( slab class),这些内存块不会释放,可以重复利用。

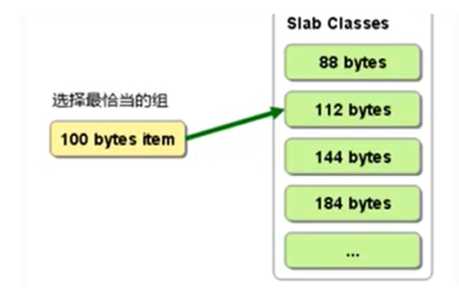
Memcached服务器端中保存着slab内空闲chunk的列表,根据该列表选择chunk,然后将数据缓存于其中。当有数据存入时, Memcached根据接收到的数据大小,选择最适合数据大小的slab (图2.2)分配一个能存下这个数据的最小内存块(chunk)。例如:有100字节的一个数据,就会被分配存入下面112字节的一个内存块中,这样会有12字节被浪费掉,这部分空间不能被使用了,这是Slab Allocation机制的一个缺点.
slab allocation还有重复使用已分配的内存的作用。也就是说,分配到的内存不会释放,而是重复利用。.
Slab Allocation的主要术语.
? Slab Allocation解决了当初的内存碎片问题,但新的机制也给memcached带来了新的问题。这个问题就是,由于分配的是特定长度的内存,因此无法有效利用分配的内存。例如,将100字节的数据缓存到128字节的chunk中,剩余的28字节就浪费了
? 避免浪费内存的办法是,预先计算出应用存入的数据大小,或把同一业务类型的数据存入一个Memcached服务器中,确保存入的数据大小相对均匀,这样就可以减少内存的浪费。还有一种办法是,在启动时指定"."参数,明确块的大小,能在某种程度上控制内存组之间的大小差异。在应用中使用Memcached时,通常可以不重新设置这个参数,使用默认值1.25进行部署。如果想优化Memcached对内存的使用,可以考虑重新计算数据的预期平均长度,调整这个参数来获得合适的设置值。
通过-f选项可以指定增长因子决定数据块的增长倍数,默认是1.25
那么chunk之间的跨度是多长为好呢?默认是1.25倍,如下96B是chund的大小,96的1.25倍是120,第二级就是120,第一行的最后的数字是chunk数量的多少,可见,chunk越小,class内部的chunk数量就越多
[root@client ~]# memcached -u memcached -vv
slab class 1: chunk size 96 perslab 10922#多少个
slab class 2: chunk size 120 perslab 8738
slab class 3: chunk size 152 perslab 6898
slab class 4: chunk size 192 perslab 5461
slab class 5: chunk size 240 perslab 4369//可指定增长因子是1.1倍,可自行根据业务调整
[root@client ~]# memcached -u memcached -vv -f 1.1如果想永久有有效就把选项写到配置文件的options选项,生效服务生效,如下所示:
[root@client ~]# cat /etc/sysconfig/memcached
PORT="11211"
USER="memcached"
MAXCONN="1024"
CACHESIZE="64"
OPTIONS="-f 1.1"memcached-tools命令可以查看memcached的状态
[root@client ~]# memcached-tool 127.0.0.1
# Item_Size Max_age Pages Count Full? Evicted Evict_Time OOM
1 96B 2053s 1 1 yes 0 0 0
#:slab class的编号 ,组的类别:第一类,而在memcached -u memcached -vv显示的第一类是96B,也就是说当前缓存的数据使用第一类就是可以存下了。
Item_Size:chunk的大小
max_age:已经生存了多少时间
pages:用了几个内存页,一个内存页是4k
count:组内的记录数
Full?:组内依然是否有空闲的chunk
? Memcached主要的cache机制是LRU(最近最少用)算法,加上过期失效。当您存数据到memcached中,可以指定该数据在缓存中可以呆多久。如果memcached的内存不够用了,过期的slabs会优先被替换,接着就轮到最老的未被使用的slabs。在某些情况下(完整缓存),如果不想使用LRU算法,那么可以通过"M"参数来启动Memcached,这样, Memcached在内存耗尽时,会返回一个报错信息,如下所示,不过我们最好还是使用默认的LRU算法。
? -M return error on memory exhausted (rather than removing items).
假如一个memcached实例不够用,需要再加mecached实例,那么用户的会话到底放到哪一个呢?取的时候从哪个取?hash之后除以memcache的数量之后取余(模),hash什么?至于hash什么就不是我们说了算,是开发说了算,可能是hash用户的cookie值,或许是hash用户的ID,hash之后会生成一串十六进制的字符,假设说当前有两个memcache,那么16进制的数除以2余数不是0就是1,如果余数是0就存放到第一台memcache,如果余数是1就存放到第二台memcache,取的时候亦是如此。假如是三个memcache实例,那余数就是0、1,2,原理与上文类似。
实际上,用的是hash算法的升级版:一致性hash算法,关于这个算法我会再专门写一篇博文。
分布式memcache集群实例上比较容易搞,多起几个进程侦听在多个不同的端口即可,就是这么简单,而且实例与实例之间是完全独立的,不用配置什么主从啥的,为什么?还是那句话,缓存服务器缓存什么,自己说了不算,程序说了算。那么如果挂了一台呢,数据不就丢了!那可以这样,让开发在写程序的时候,在两台主机都存一份不就行了!
优点:
memcached是内存缓存,在读写速度上会比普通files快很多。
可以解决多个服务器共用session的难题
缺点:
session数据都保存在memory当中,持久化方面有所欠缺,但对session数据来说不是问题。
也可以用其他持久化的系统存储sessions,如redis
高性能高并发场景,cookie的效率比session要好很多,因此,很多大型网站都会用cookies解决会话共享问题。
监控memcache需要监控哪些具体指标
-p 指定memched服务监听TCP端口号。默认为11211,换个端口再侦听就相当于多实例
-m 指定memched服务可以缓存数据的最大内存。默认为64MB
-u 运行Memcached的用户.
-d作为守护进程在后台运行。.
-c最大的并发连接数,默认是1024,按照服务器的并发访问量来设定。.-vv 以very vrebose模式启动,调试信息和错误输出到控制台。.
-P 设置保存Memcache的pid文件(Ss)
-l 指定监听的服务器IP地址。
其他选项,通过"memcached-h"命令可以显示所有可用选项,我们其实用不上这些选项,在memcache的配置文件都有这些内容,我们设置就好,设置好了之后重读配置文件就行了!如下所示:
[root@kk ~]# rpm -qc memcached
/etc/sysconfig/memcached
[root@kk ~]# cat /etc/sysconfig/memcached
PORT="11211"
USER="memcached"
MAXCONN="1024" #最大并发连接数
CACHESIZE="64" #默认memcahce会占用64M内存
OPTIONS="" #可以把-f指定调优因,写到这,不写就默认了格式:set 键 标识符 时长 长度
[root@client ~]# telnet 127.0.0.1 11211
set mykey 0 60 11
hello world
STORED
append mykey 0 60 1 #加一个字符
a
STORED
get mykey
VALUE mykey 0 12
hello worlda
END
prepend mykey 0 60 3
abc
delete mykey
stats #查看状态//计数增加、减少
set mykey 0 300 1
3
STORED
get mykey
VALUE mykey 0 1
3
END
incr mykey 2
5
get mykey
VALUE mykey 0 1
5
decr mykey 1
4flush_all #清理所有缓存
OK 最常见的就是php-fpm和tomcat这两个配置memcache实现session server
开始真正配置sesson会话保持修改配置文件,在php.ini中全局设置: .
web集群session共享存储设置:.
默认php.ini中session的类型和配置路径:
sessionsave_handiler -files
sessionsave_path =tmp".
修改成如下配置:.
session save_hanler = memcache
session.save bath -"tcp://0.0.0.18:11211.
提示:.
1) 10.0.0.18:11211为memcached数R库城存的IP及口.
2)上述适合LNMPLAMP环境
3) memcached服务器也可以是多台通过hashi度.
tomcat想要使用memcache需要安装几个插件,整体流程与php-fpm差不多。此处略过。
标签:加速 插件 联网 集群架构 大型网站 net class 技术 ini
原文地址:https://www.cnblogs.com/yizhangheka/p/12502868.html