标签:需要 一句话 lis ack 运算 delay google str 原来
上节回顾深度学习与人类语言处理-语音识别(part1),这节课我们将学习如何将seq2seq模型用在语音识别

那我们来看看LAS的Encoder,Attend,Decoder分别是什么
Listen是一个典型的Encoder结构,输入为声学特征\({x^1,x^2,...,x^T}\),输出和输入长度相同,是对声学特征的高阶表示,\({h^1,h^2,...,h^T}\).
我们希望Encoder可以做到以下两件事:
那Encoder怎么做呢?可以用RNN、CNN、self-attention
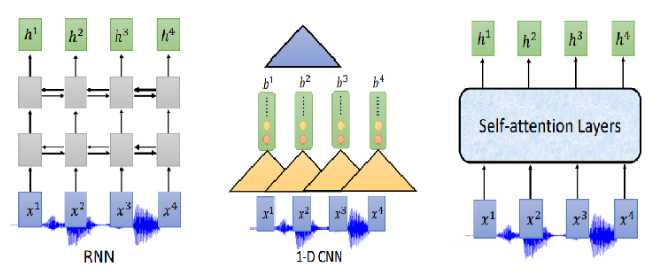
通常我们需要对声音信号进行下采样,为什么呢?当然是声音信号太长了,1s的声音信号就有100个向量(上节声学特征部分讲过),而且相邻的信号之间的差异不是特别大,下采样可以帮助我们有效的进行训练。下图是关于RNN的两个下采样方法
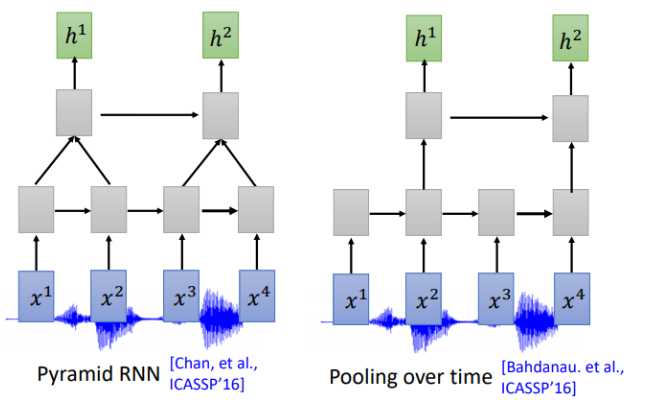
Pyramid RNN将下层每两个隐状态加起来作为下一层,实践证明这种方法还是很有效的。Pooling over time 和Pyramid RNN 很像,不同没有加起来,直接每两个隐状态取一次作为下层输入。
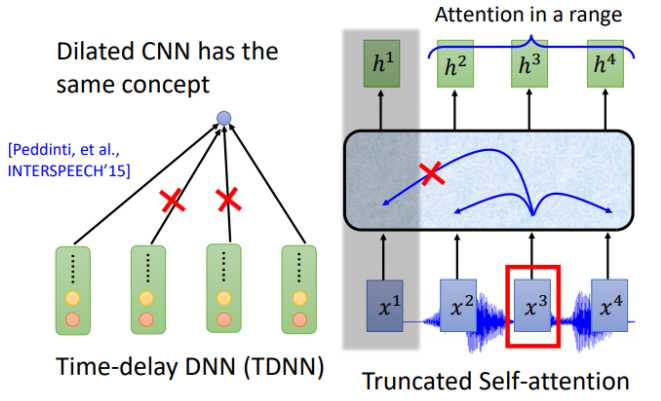
那CNN和self-attention是不是也可以用类似的下采样呢?答案是肯定的。对于CNN常用的变形是TDNN (Time-delay DNN),不同于传统的CNN做卷积操作时会考虑范围内所有的输入,TDNN相当于只让部分参与了运算,提高效率。
同样,对于self-attention,在机器翻译等任务中每一个位置的输入会看过序列中所有的输入,但是在语音识别中,序列实在太长了,Truncated Self-attention 就是让每一个位置的输入只看窗口范围内的其他输入,窗口大小是一个可以调节的参数,例如可以只看未来4个,看以前的30个。
LAS的attention和机器翻译中的attention并没有什么不同,文献中提到了两种attention计算方法,dot-product attention 和additive attention
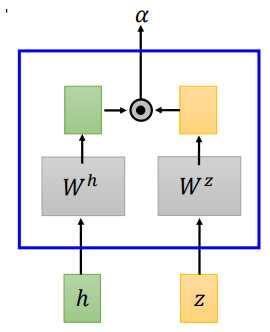
dot-product attention 将输入\(h\)和\(z\)经过矩阵\(W^h、W^z\)转换,将转换结果进行点积,得到\(\alpha\)
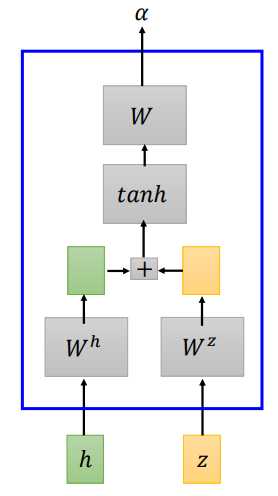
additive attention 将输入\(h\)和\(z\)经过矩阵\(W^h、W^z\)转换,将转换结果相加,经过一个线性变换得到\(\alpha\)
我们来看看LAS的attention具体怎么做的
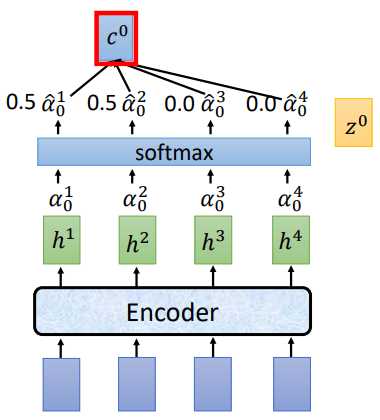
将\(z^0\)分别和\(h^1,h^2,h^3,h^4\)做attention运算得到\(\alpha ^1 _ 0,\alpha ^2 _ 0,\alpha ^3 _ 0,\alpha ^4 _ 0\),经过softmax归一化,再将归一化后的结果和\(h^i\)相乘求和得到 \(c^0\),将 \(c^0\)作为Decoder部分的输入
举个栗子:
讲过attention计算和softmax归一化后,得到的\(\hat{\alpha_0}\)为[0.5,0.5,0.0,0.0],\(c^0 = \sum\hat{\alpha}^i_0h^i=0.5h^1+0.5h^2\).
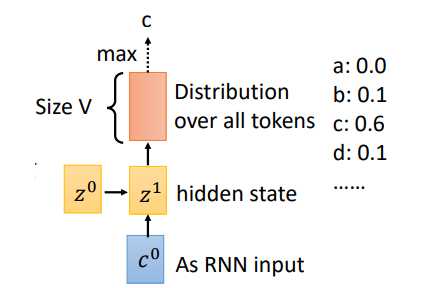
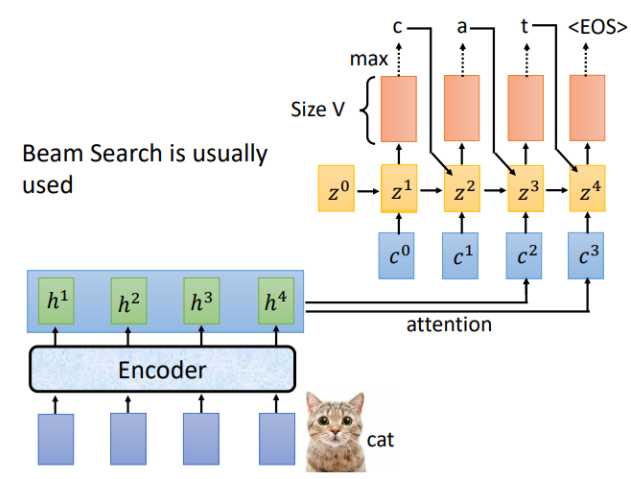
LAS的Listen对应Encoder,Spell对应的就是Decoder,假设Encoder的输入为“cat",Decoder的每一个时间步对应的输出就是词汇表中每个词的分布,通常会选概率最大的那个作为输出。
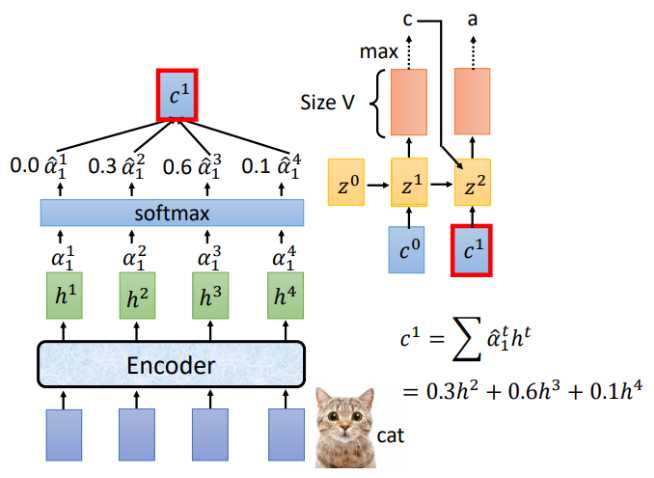
刚才是用\(z^0\)计算得到\(c^0\),现在我们用\(z^1\)进行运算,重复attention过程,就得到了\(c^1\),对应的结果如下
完整的Spell流程如下,通常输出结果会用束搜索(beam search),有关beam search 的内容可以自行了解。
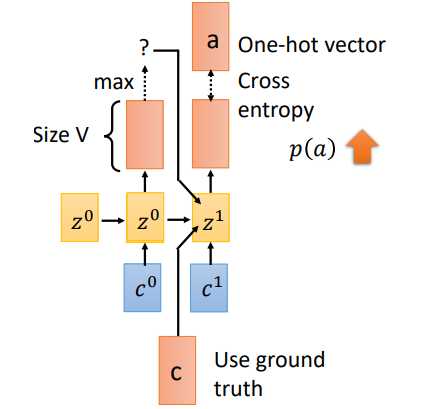
训练过程有一个重要的不同就是Teacher Forcing。刚才在Spell部分我们说到,一个时刻的输入其实有三个部分(\(c^1,z^0,o^0)\),当前位置的attention结果context向量,上一时刻的隐状态,以及上一时刻的预测输出。但是在training阶段,我们会将\(o^0\)换成真实的上一时刻的输出。假如\(t_0\)预测的输出为\(x\),实际应该输出\(c\),我们会将\(c\)作为下一时刻的输入。这就是Teacher Forcing
那为什么需要Teacher forcing呢?我们来看看如果使用上一时刻预测的输出作为输入会发生什么
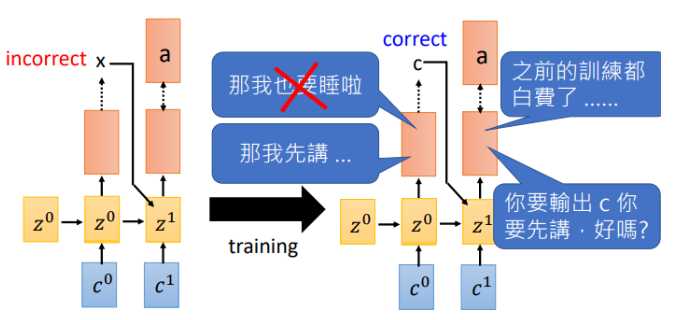
假如在\(t_0\)输出了\(x\),下一时刻机器就会学习在输入为\(x\)时我需要输出\(a\),然而等到训练的一定回合时,\(t_0\)可以做出正确的预测了,告诉机器输入\(c\)需要输出\(a\),此刻机器已经懵了,刚才不是说\(x\)对应\(a\)吗,那之前的训练就白费了。就开始互掐了。。。
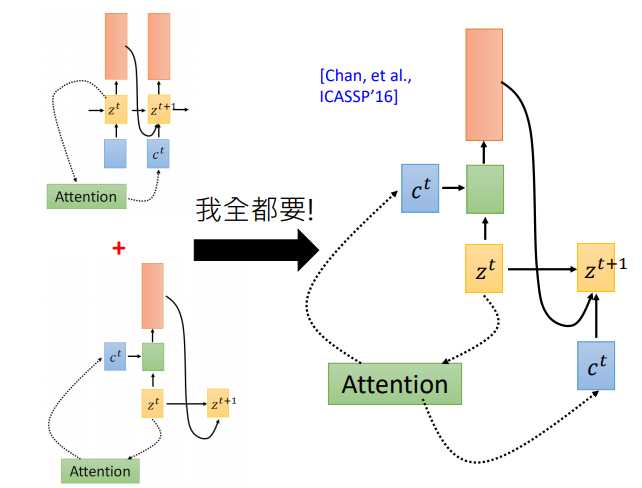
我们在回到之前的attention操作,attention计算得到的context被用于下一时刻的输入(左图),现在还有另一种attention架构,将context直接用于当前时刻的输入(右图)
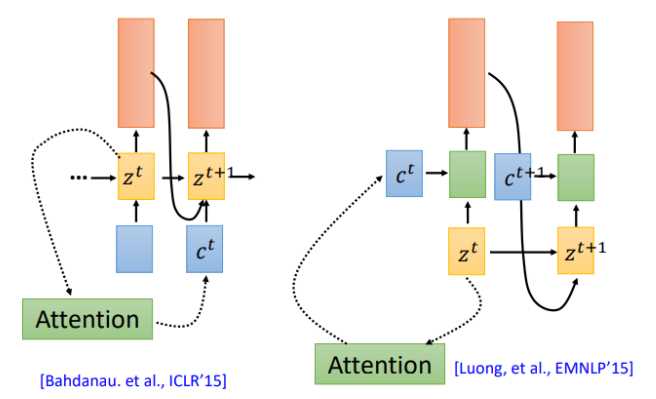
那么哪一种更有效呢?该用那个呢。第一篇使用seq2seq做语音识别的论文说:我全都要。context向量即作用于当前位置,也作用于下一位置
使用Attention作语音识别真的好吗?
有点杀鸡用牛刀的感觉!为好么呢,我们知道用attention的seq2seq模型首先用在机器翻译上,在翻译任务中,输入和输出没有一致的对应关系,需要attention自己寻找对应的那个词。但是对语音来说输入输出是对应的,有人提出了location-aware attention
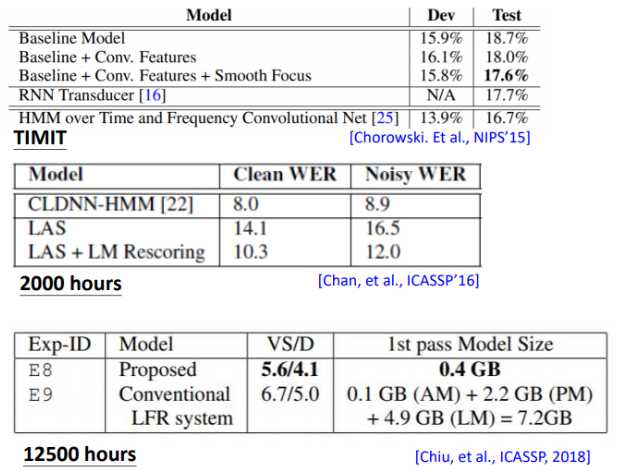
刚开始的时候LAS其实打不过传统模型,后来随着训练集的增加以及各种trick,LAS已经很厉害了。可以看到刚开始的时候,打不过传统模型,2018年google在12500小时的训练集上训练,最终打败了传统模型,并没有使用location-aware attention,而且最重要的是模型变小了,从原来的7.2G变成0.4G
那LAS还有什么问题呢?
LAS采用经典的Encoder和Decoder架构,也就是说,只有在完整的听完一句话之后模型才会输出,那如果我们希望机器在听到声音的同时就输出怎么做呢?我们下节课再讲。
标签:需要 一句话 lis ack 运算 delay google str 原来
原文地址:https://www.cnblogs.com/gongyanzh/p/12515971.html