标签:min turn ack begin str 挖掘 first its 更新
k-means中文称为K均值聚类算法,在1967年就被提出 所谓聚类就是将物理或者抽象对象的集合分组成为由类似的对象组成的多个簇的过程
聚类生成的组成为簇 簇内部任意两个对象之间具有较高的相似度,不同簇的两个对象之间具有较高的相异度
相异度和相似度可以根据描述的对象的属性值来计算 对象间的距离是最常采用的相异度度量指标
常用的距离方法有

k-means是基于划分的方法 就是通过迭代将数据对象划分为k个组每个组为一个簇
每个分组至少包含一个对象
每个对象属于且仅属于某个分组
输入:簇的数目K和包含n个对象的数据集D
输出:K个簇的集合
方法:
1.从D中任意选择K个对象作为初始簇的质心;
2.计算每个对象与各簇质心的距离,并且将对象划分到距离其更近的簇
3.更新每个新簇的质心
4.重复2.3步骤,直到簇中的对象不再变化
对K-means算法的几点说明
1.簇的质心就是簇中所有对象在每一维属性的举止组合成的虚拟点 并非实际存在的数据点
2.对噪声和离群(孤立)点数据是敏感,因为它们的存在会对均值的计算产生极大的影响
3.对象到质心的距离通常使用欧式距离来计算
4.要求用户实现给出生成的数目,要求K值已直
5.算法收敛的速度和结果容易受初始质心的影响
来个例子:
数据集:
n = 8, k = 2;取1和3为初始点
|
序号 |
属性1 |
属性2 |
|
1 |
1 |
1 |
|
2 |
2 |
1 |
|
3 |
1 |
2 |
|
4 |
2 |
2 |
|
5 |
4 |
3 |
|
6 |
5 |
3 |
|
7 |
4 |
4 |
|
8 |
5 |
4 |
1 #include<bits/stdc++.h> 2 using namespace std; 3 struct Node 4 { 5 int id; 6 double a, b; 7 }node[100]; 8 vector<int>beginn[100],endd[100]; 9 int flag = 0; 10 double distance(pair<double,double>a, Node b){ 11 return (b.a - a.first) * (b.a - a.first) + (b.b - a.second) * (b.b - a.second); 12 } 13 bool check(int k ) 14 { 15 if(flag == 0) 16 { 17 flag = 1; 18 return false; 19 } 20 for(int i = 0 ; i < k ; i ++) 21 { 22 if(beginn[i].size() != endd[i].size()) 23 return false; 24 for(int j = 0 ; j < endd[i].size(); j++) 25 { 26 if(endd[i][j] != beginn[i][j]) 27 return false; 28 } 29 } 30 return true; 31 } 32 int main() 33 { 34 int n, k; 35 cin >> n >> k; 36 for(int i = 1; i <= n; i ++) 37 cin >> node[i].id >> node[i].a >> node[i].b; 38 vector<double>vec[100]; 39 vector< pair<double, double> > gg; 40 for(int i = 1; i <= k; i ++) 41 { 42 int x; 43 cin >> x; 44 gg.push_back(make_pair(node[x].a,node[x].b)); 45 }//只要把这些点当作是初始点就可以 与其他的点无关即可 46 while(true) 47 { 48 for(int i = 0 ; i < k; i++) 49 { 50 beginn[i].assign(endd[i].begin(), endd[i].end()); 51 endd[i].clear(); 52 } 53 for(int i = 0; i < k; i ++) //表示有k个堆 计算每个堆里面的值 54 { 55 vec[i].clear(); 56 for(int j = 1; j <= n ; j ++) 57 vec[i].push_back(distance(gg[i] , node[j]));//计算的是每个点到初始点的距离 58 } 59 for(int i = 0 ;i < n ; i ++) 60 { 61 double minn = 0x3f3f3f3f; 62 int u = -1; 63 for(int j = 0; j < k; j ++){ 64 if(vec[j][i] < minn){ 65 minn = vec[j][i]; 66 u = j;//表示的是哪个簇的 67 } 68 } 69 endd[u].push_back(i + 1); 70 } 71 cout<<"新计算得到的"<<endl; 72 for(int i = 0 ; i < k ; i ++) 73 { 74 for(int j = 0 ; j < endd[i].size(); j ++) 75 printf("%d ",endd[i][j]); 76 printf("\n"); 77 } 78 cout<<"原本的"<<endl; 79 for(int i = 0 ; i < k ; i ++) 80 { 81 for(int j = 0 ; j < beginn[i].size(); j ++) 82 printf("%d ",beginn[i][j]); 83 printf("\n"); 84 } 85 gg.clear(); 86 for(int i = 0 ; i < k ; i ++) 87 { 88 double sum1 = 0, sum2 = 0; 89 for(int j = 0 ; j < endd[i].size(); j ++) 90 { 91 sum1 += node[endd[i][j]].a; 92 sum2 += node[endd[i][j]].b; 93 } 94 sum1 = sum1 / endd[i].size(); 95 sum2 = sum2 / endd[i].size(); 96 gg.push_back(make_pair(sum1,sum2)); //得到的新的值 97 } 98 cout<<"新的平均值:"<<endl; 99 for(int i = 0 ; i < k ;i ++) 100 cout<<gg[i].first <<" " << gg[i].second<<endl; 101 cout<<endl; 102 if(check(k)) 103 return 0; 104 } 105 return 0; 106 }
结果可得
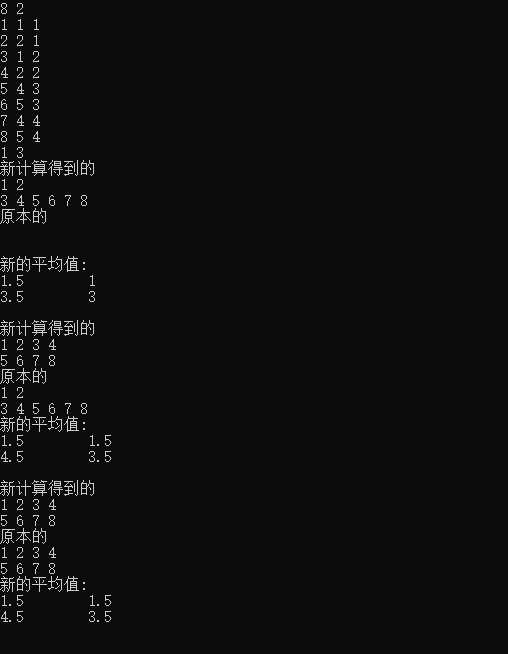
参考来自:
https://www.jianshu.com/p/4f032dccdcef
https://www.icourse163.org/course/CUG-1003556007?utm_campaign=share&utm_medium=androidShare&utm_source=
标签:min turn ack begin str 挖掘 first its 更新
原文地址:https://www.cnblogs.com/Galesaur-wcy/p/12529880.html