标签:收入 几何 tab end 中位数 好处 学习 表达 分类
这一篇介绍一些描述性统计的基本情况。
数据处理是描述性统计的第一步,对于搜集的数据,首先应先排序,将其按照一定的顺序整理。操作完成后要进行分组,以被研究事物的本质属性进行分组,分组的标准要明确,不能出现数据的交叉和重叠。
一、次数分布概况
次数分布一般是初步整理好一组数据后,将同一组或同一类观测值的原始数据整理成频次分布表,表现数据在各个分组区间内的散布情况。
举例来说,搜集到一个班级60人的考试成绩,这是原始数据。
首先介绍简单次数分布,按照及格、良好、优秀三档这样的描述性文字分,把描述性文字转化为数学区间就可以很轻松的分出来了。
进一步可以分为分组次数分布表,将数据量分为若干分组区间,再将数据按数值大小划归相应的组别内,分别统计各组别内的数据个数。进行这一过程的步骤是:
(1)求全距,range,最大值与最小值做差。
(2)决定组距与组数。组数与组距的确定没有明确的先后关系,根据经验来进行。但是可以先确定组数,比如如果成绩呈正态分布的形式,就可以利用经验公式确定组数K=1.87*(N-1)^(2/3),这里就直接写python表达式了。组数的值是一个近似值,取整。得到组数后就能用全距除以组数得到组距。按照经验我们可以知道一个班级的考试成绩就是近似正态分布,所以可以采取这个近似表达式。
(3)列出分组区间,把每个区间的下限和上限都求出来,然后分别列出。
(4)计算每个组内的次数并列
再介绍累加次数分布。 一般的分组次数分布只标出了各组区间的数据次数,想知道某个数值以下的总次数就要用到累加次数。把各组的次数从上到下或者从下到上进行累加,最后一组的次数累加等于总次数。
其他统计图表暂时不说,等到我学会matplotlib库再去实现。
二、集中量数介绍
集中量数、差异量数是分别来描述统计学上次数分布的集中趋势和离中去世这两个基本数据特点的量度。集中量数包括平均数、中位数、众数等多种量度。
算术平均数是整个数据的支点,就像杠杆一样使左右两边的数据刚好处于平衡的位点。平均数的特点是,样本每个变量和平均数之差的总和为0,样本中每个数加或乘一个常数,平均数也相应加或乘一个常数。一般情况下由于各种偏差的我们不能得到总体的属性的真值,而算术平均数在大部分情况下是总体真值的最佳的估计值。
算术平均数的优缺点
|
优点 |
缺点 |
|
反应灵敏,对任何一个数的变化都能有所反应 |
容易受极端值影响,对于有偏度的样本平均值不能恰当描述分布的真实情况,所以有切尾平均值,去掉p个最低最高值再计算 |
|
计算严密,任何人拿到相同的数据算出来的都是相同结果。 |
若出现模糊结果则无法计算均值,所以python中要先处理数据去除空值 |
|
计算简单,这是针对后面的几何平均、调和平均说的 |
|
|
适合于进一步代数运算,计量推导回归公式的时候均值的很多性质都会用到 |
|
应用算术平均数有以下几个原则
同质性原则:一定要保证数据是同类的同性质的数据。讲个笑话,马云和我一起去吃饭,我们的平均收入上百亿,这种平均是没意义的,因为我作为一个穷逼收入都是靠自己出卖劳动力,跟我的出卖的时间成正比,这属于无产阶级收入,马云的收入是靠他的投资、靠他的钱生钱,这是大资产阶级的收入,我和马云收入的来源不一样所以性质完全不一样,所以这种平均就没意义。所以每年全国居民平均收入水平前几年就到了两万多,但扶贫任务还是一直做到现在,侧面反应不考虑同质性的统计数据是有很大问题的。
保证平均数和个体数值相结合参考的原则,还是跟上面一样,看到我国人均收入过了两万,但是也要看到有人年均五百个亿,有人年均吃低保。平均数反映了我国经济形式向好的趋势,但是个体间的差异不看到的话就不能看到贫富差距加大的事实。
集中量数和差异量数相结合,上面说的是看到各个样本个体间的差异,用方差和标准差来作为这种差异的度量,差异越大,平均数越没有代表性,差异越小,平均数代表性越强。
接着介绍其他平均数。
加权平均数一般用于所测数据单位权重不一致的情形。
几何平均数用于数据有偏度时,算术平均数不能很好地表示集中趋势的场合。几何平均数的公式是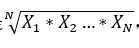 ,还可以用对数公式作为替代
,还可以用对数公式作为替代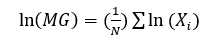 。当组间变异较大时,几乎是按照一定比例关系增长的时候,用几何平均数就可以计算比率。
。当组间变异较大时,几乎是按照一定比例关系增长的时候,用几何平均数就可以计算比率。
调和平均数先将各个数据取倒数平均,再取倒数的过程。调和平均数一般用于研究学习速度方面的问题,一个人前十五分钟学习三十个单词,后十分钟学习二十个单词,问其每分钟学多少个单词。用调和平均来算每分钟的情形。
众数和中位数就不再过多讲解。
下面介绍一下分组次数计算的python实现,前面复杂的for、if循环是我自己想的,后面三行代码处理是小师弟教我做放缩处理之后得到的。
import numpy as np import pandas as pd score_list=[76,77.5,82,90.5,81,85.5,71,80.5,92.5,77,88,81,76.5,67,83,84,84,62,79,72,89,78,78,80,78.5,76.5,75,79.5,86,81.5,75,84,90,80,86,84.5,68.5,71,86,81.5,79.5,80.5,73,93,83,72,68,71,87,78, 66,83,87,82.5,79.5,80,82,81,86.5,83.5, 71.5,83,91,96,75.5,89,87.5,69,74,70, 77.5,75,79,79,80.5,74.5,77,82.5,72.5,73.5, 73.5,76,88.5,85,89.5,78.5,76,74,98,73, 94,79,80,75.5,83.5,82,65,74.5,80,70.5,] score_data=pd.Series(score_list) #print(min(score_data),max(score_data)) bins=[min(score_data)-2,70,80,90,max(score_data)+2] labels_=[‘60-70‘,‘70-80‘,‘80-90‘,‘90-100‘] print(pd.cut(score_data,bins,right=True,labels=labels_)) #cut函数可以将series中每个数据贴上分组的标签 ‘‘‘a1=[] a2=[] a3=[] a4=[] for i in score_data: if 60<=i<70: a1.append(i) elif 70<=i<80: a2.append(i) elif 80<=i<90: a3.append(i) elif 90<=i<100: a4.append(i) #print(a1,a2,a3,a4) print(pd.Series([len(a1),len(a2),len(a3),len(a4)],index=labels_))‘‘‘ score_data=score_data/10 #放缩 score_data=np.floor(score_data) #取整,将同一区间的数据只保留整数部分相同的值 print(score_data.value_counts()) #分类函数,将相同的值的个数分离出来
标签:收入 几何 tab end 中位数 好处 学习 表达 分类
原文地址:https://www.cnblogs.com/zdl4/p/12530791.html