标签:字符串 inf nbsp 你好 unicode编码 span str 过程 encode
一、代码块
python程序的是由代码块构成的。一个代码块的文本作为python程序的执行单元。
1、在命令行中,每一行都是代码块
2、在py文件中,整个可执行内容为一个代码块
二、is 和 == 的区别
1、id()
通过id()我们可以查看到一个变量表示的值在内存中的地址
s = ‘alex‘
print(id(s)) # 4326667072
2、is 和 ==
==判断左右两端的值是否相等,是否一致
is判断左右两端内容的内存地址是否一致。如果返回True,那么可以确定这两个变量使用的是同一个对象
二、小数据池
定义:
一种缓存机制,也被称为驻留机制,也称为校正数缓存机制。各大编程语言中都有类似的东西。在网上搜索常量池,
小数据池值得都是同一个内容。
小数据池只针对:整数,字符串,布尔值。其他的数据类型不存在驻留机制。
前提条件:在不同一个代码块内
1、在python中对 -5到256之间的整数会被驻留在内存中。将一定规则的字符串缓存。在使用的时候直接从
小数据池取对象的内存引用,而不需要创建一个新的数据。这样会节省更多的内存区域。
优点:能够提高一些字符串,整数的处理速度。省略创建对象的过程
缺点:在"池"中创建或者插入新的内容会花费更多的时间
对于数字:-5 ~256 是会加到小数据池中的。每次使用都是同一个对象。
对于字符串:
a、如果字符串的长度是0或者1,都会默认进行缓存
b、字符串长度大于1,但是字符串中只包含数字,字母,下划线时才会被缓存
c、?乘法的到的字符串. ①. 乘数为1, 仅包含数字, 字?, 下划线时会被缓存. 如果
包含其他字符, ??度<=1 也会被驻存, ②. 乘数?于1 . 仅包含数字, 字?, 下划
线这个时候会被缓存. 但字符串?度不能?于20
d、指定驻留。我们可以通过sys模块中的 intern()函数来指定要驻留的内容
2、小数据池和代码块的关系
a、在comand命令窗口和python 文件中:
a = 1000
b = 1000
print(a is b)
注意:在py文件中,得到的结果是True,但是在command中是False
因为:在command窗口中每一行代码都是单独的代码块,会遵循小数据池的缓存机制--整数的范围为(-5-156)
在py文件中单纯的创建变量都是有缓存的,如若进行了*的操作,则是回到小数据池规定的范围;
三、编码
1、
ascii: 数字、字母、特殊字符
字节:8bit
gbk:国标码,16bit,2bytes
unicode:万国码, 32bit, 4bytes
utf-8:可变长度的unicode
英文:1byte ,8bit
欧洲文字:2byte ,16bit
中文:3byte , 24bit
注:各编码之间的二进制,是不能相互识别的,会产生乱码
文件的存储,传输不能是Unicode(只能是utf-8 utf-16 gbk gb2312 ascii等)
2、 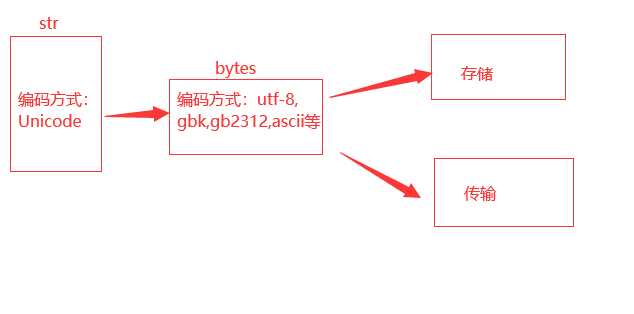
python3 内存中使用的是unicode
s = "你好啊"
python2 中使用的是 ascii
3、
字符串如果传输:将str--->bytes
encode(编码) :结果是bytes类型
接收bytes之后,需要解码
decode(编码)。结果是字符串
4、py3:
str 在内存中是用Unicode编码
bytes类型
对于英文:
str:表现形式: s = ‘alex‘
编码方式:010101010 Unicode
bytes:表现方式:s = b‘alex‘
编码方式:00101010 utf-8 gbk
对于中文:
str:表现形式: s = ‘alex‘
编码方式:010101010 Unicode
bytes:表现方式:s = b‘x\e91\e01\e21\e31\e32‘
编码方式:00101010 utf-8 gbk ....
标签:字符串 inf nbsp 你好 unicode编码 span str 过程 encode
原文地址:https://www.cnblogs.com/dandanouni/p/12534035.html