标签:前言 源代码 学习 where ref 后退 article 思路 导入
? 经过多日有关深度学习的学习,已经对python和有关理论知识有着初步的掌握,但是在编写程序的时候还是存在着思路不清晰,码力不足的情况。根据我浅薄的学习经验,想要在最短的时间内扭转这种情况必须狠狠地吃透几个项目。对于一些程序需要一行代码一行代码地分析,反复看。这种方法虽然笨拙但是速度最快,效果最好,能够以惊人的速度吸收代码大神的编程营养。不仅要吃透,还要输出,所以我想开一个分类专门记录一个小白视角分析大神项目代码的板块,不仅输出了所学,掌握更牢固,而且以后还可以回溯。我把这个分类的名字叫little by little,一点点地吃透,稳扎稳打,绝不后退!
import numpy as np
import matplotlib.pyplot as plt
import operator
#1
def CreatDataset():
group = np.array(
[ [1.0,1.1],
[1.0,1.0],
[0.1,0],
[0,0.1]]
)
labels = ['A','A','B','B']
return (group,labels)
#3
def show_data(group,labels):
labels = np.array(labels)
index_a = np.where(labels == 'A')
# print(index_a)#取出符合条件的索引
index_b = np.where(labels == 'B')
for i in labels:
if i == 'A':
plt.scatter(group[index_a] [:,:1],group[index_a][:,1:],c='red')#c = color
elif i == 'B':
plt.scatter(group[index_b] [:, :1], group[index_b][:, 1:], c='green') # c = color
plt.show()
#2
def classify(Inx,DataSet,labels,k):
dataSetsize = DataSet.shape[0]#取0维的,输出其维度的长度,计算出原数据有多少个
DiffMat = np.tile(Inx,(dataSetsize,1)) - DataSet#得到原数据和原点对应的x和y的差值
#毕功于一役,一次比完.改变原点的形状
sqDiffMat = DiffMat**2
sqDistance = sqDiffMat.sum(axis=1) #括号内求和.#尽量不要想循环,尽量去找api
Distance = np.sqrt(sqDistance)
sortedDistanceIndex = Distance.argsort()#排序,排索引,用于分类.argsort按照参数来排序,返回索引值
#最终的投票结果
ClassCount = {}
for i in range(k):#比多少次
votelabel = labels[sortedDistanceIndex[i]]#取k次排序前三的索引
ClassCount[votelabel] = ClassCount.get(votelabel,0)+1 #get方法,返回key键的value值,如果没有返回default值.
print(ClassCount)
SortedClass = sorted(ClassCount.items(),key=lambda x:x[1],reverse=True)
return SortedClass[0][0]
#4
if __name__ == '__main__':
#导入数据
inX = [0.2,0.3]
Data_set,labels = CreatDataset()
classify(inX, Data_set,labels,3)
show_data(Data_set,labels)def CreatDataset():
group = np.array(
[ [1.0,1.1],
[1.0,1.0],
[0.1,0],
[0,0.1]]
)
labels = ['A','A','B','B']
return (group,labels)此处是创造一个数据组不多做赘述,labels代表每个数据对应的类别。
#2
def classify(Inx,DataSet,labels,k):
dataSetsize = DataSet.shape[0]#取0维的,输出其维度的长度,计算出原数据有多少个
DiffMat = np.tile(Inx,(dataSetsize,1)) - DataSet#得到原数据和原点对应的x和y的差值
#毕功于一役,一次比完.改变原点的形状
sqDiffMat = DiffMat**2
sqDistance = sqDiffMat.sum(axis=1) #括号内求和.#尽量不要想循环,尽量去找api
Distance = np.sqrt(sqDistance)
sortedDistanceIndex = Distance.argsort()#排序,排索引,用于分类.argsort按照参数来排序,返回索引值
#最终的投票结果
ClassCount = {}
for i in range(k):#比多少次
votelabel = labels[sortedDistanceIndex[i]]#取k次排序前三的索引
ClassCount[votelabel] = ClassCount.get(votelabel,0)+1 #get方法,返回key键的value值,如果没有返回default值.
print(ClassCount)
SortedClass = sorted(ClassCount.items(),key=lambda x:x[1],reverse=True)
return SortedClass[0][0]参数意义:
? Inx - 需要划分类别的点的坐标
? Dataset - 已经划分好类别的数据集
? labels - 标签,与Dataset必须一一对应
? k - KNN的k值指的是,当Inx最近k个点大多数是某一类的时候inx就是某一类
dataSetsize = DataSet.shape[0]取出dataset里面有多少个数据,以便后面广播使用
DiffMat = np.tile(Inx,(dataSetsize,1)) - DataSet 此处在计算inx和所有点的欧氏距离。按照正常思维,需要用for循环从从dataset里面取出数据一一和inx比对,但是大神直接将inx广播一下,和dataset相减就直接得到dataset里面全部点和inx的x,y值的差值。计算量大大减少,亮点! 关于np.tile()是一个广播函数

sqDiffMat = DiffMat**2 算平方

sqDistance = sqDiffMat.sum(axis=1) 将sqdiffmat沿着1轴加和。

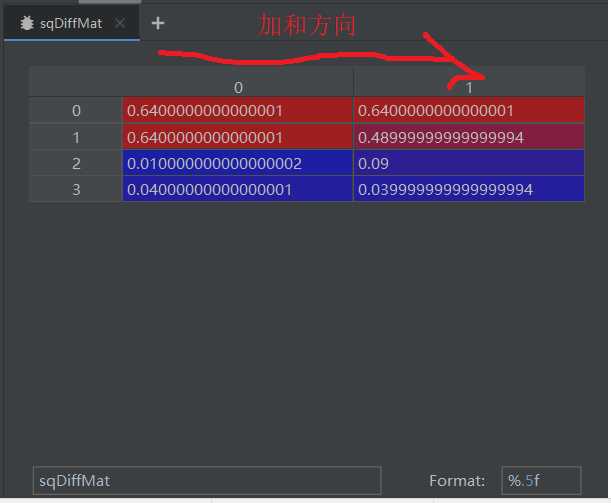
sortedDistanceIndex = Distance.argsort()#排序,排索引,用于分类返,回索引值


#最终的投票结果
ClassCount = {}
for i in range(k):#比多少次
votelabel = labels[sortedDistanceIndex[i]]#取k次排序前三的索引
ClassCount[votelabel] = ClassCount.get(votelabel,0)+1 #get方法:返回key键的value值,如果没有返回default值.? 一个取投票结果的循环,循环次数为k次(kNN的定义),labels[sortedDistanceIndex]为各个点离inx距离的排序索引,循环k次代表取前k位。
ClassCount[votelabel] = ClassCount.get(votelabel,0)+1 代表用classcount存储最后的投票结果,votelabel只有两个参数:‘a’ 或者 ‘b‘ ,当votelabel取到’a‘ 或 ’b’时,classcount相应的键值下的value也会加1用于计数。
SortedClass = sorted(ClassCount.items(),key=lambda x:x[1],reverse=True) 用于最后的排序详细见:sorted函数。
最后循环结束时候的相关变量的终值:


def show_data(group,labels):
labels = np.array(labels)
index_a = np.where(labels == 'A')
# print(index_a)#取出符合条件的索引
index_b = np.where(labels == 'B')
for i in labels:
if i == 'A':
plt.scatter(group[index_a] [:,:1],group[index_a][:,1:],c='red')#c = color
elif i == 'B':
plt.scatter(group[index_b] [:, :1], group[index_b][:, 1:], c='green') # c = color
plt.show()有关参数:
? group:传入的array,用于画图
? labels:传入的标签
? index_a = np.where(labels == ‘A‘) 返回labels 为 ‘A’的索引序列 详见np.where

for i in labels:
if i == 'A':
plt.scatter(group[index_a] [:,:1],group[index_a][:,1:],c='red')#c = color
elif i == 'B':
plt.scatter(group[index_b] [:, :1], group[index_b][:, 1:], c='green') # c = color

此处大神的 for i in labels:循环我觉得多此一举 ,实测有无这个循环画出来的图都是一样的,
group[index_a]是数组索引取出标签为A的点。详见:array以整形数组作为索引
简化写法:
# for i in labels:
# if i == 'A':
plt.scatter(group[index_a] [:,:1],group[index_a][:,1:],c='red')#c = color
# elif i == 'B':
plt.scatter(group[index_b] [:, :1], group[index_b][:, 1:], c='green') # c = color实测效果一样。
标签:前言 源代码 学习 where ref 后退 article 思路 导入
原文地址:https://www.cnblogs.com/negu/p/12544259.html