标签:paper tst 配置 引擎 基本 forms 最小 延迟 控制
参考:
参考:
参考:
滑动窗口本质上是描述接受方的TCP数据报缓冲区大小的数据,发送方根据这个数据来计算自己最多能发送多长的数据。如果发送方收到接受方的窗口大小为0的TCP数据报,那么发送方将停止发送数据,等到接受方发送窗口大小不为0的数据报的到来。
关于滑动窗口协议,还有三个术语,分别是:
窗口合拢:当窗口从左边向右边靠近的时候,这种现象发生在数据被发送和确认的时候。
窗口张开:当窗口的右边沿向右边移动的时候,这种现象发生在接受端处理了数据以后。
窗口收缩:当窗口的右边沿向左边移动的时候,这种现象不常发生。
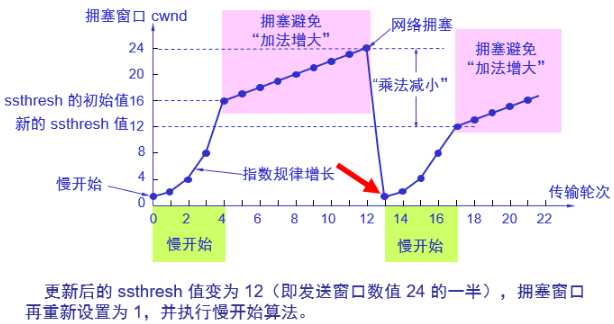
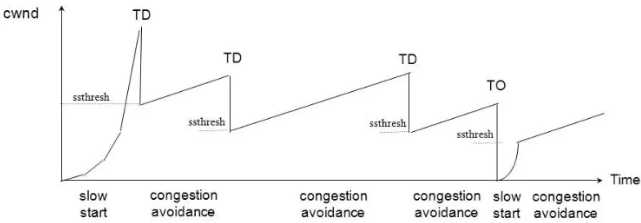
下面看下tahoe算法,reno算法(快速重传和快速恢复)和cubic算法的拥塞图,这三个算法在慢启动阶段相同,基于超时或重复确认来确认是否切换到拥塞避免阶段。不同点在拥塞避免阶段。tahos算法的描为(来自TCP-IP详解-卷1):
1) 对一个给定的连接,初始化cwnd为1个报文段, ssthresh为65535个字节。 2) TCP输出例程的输出不能超过cwnd和接收方通告窗口的大小。拥塞避免是发送方使用的流量控制,而通告窗口则是接收方进行的流量控制。前者是发送方感受到的网络拥塞的估计,而后者则与接收方在该连接上的可用缓存大小有关。 3) 当拥塞发生时(超时或收到重复确认),ssthresh被设置为当前窗口大小的一半(cwnd和接收方通告窗口大小的最小值,但最少为2个报文段)。此外,如果是超时引起了拥塞,则cwnd被设置为1个报文段(这就是慢启动)。 4) 当新的数据被对方确认时,就增加cwnd,但增加的方法依赖于我们是否正在进行慢启动或拥塞避免。如果cwnd小于或等于ssthresh,则正在进行慢启动,否则正在进行拥塞避免。慢启动一直持续到我们回到当拥塞发生时所处位置的半时候才停止(因为我们记录了在步骤2中给我们制造麻烦的窗口大小的一半),然后转为执行拥塞避免。慢启动算法初始设置cwnd为1个报文段,此后每收到一个确认就加1。这会使窗口按指数方式增长:发送1个报文段,然后是2个,接着是4个??。拥塞避免算法要求每次收到一个确认时将cwnd增加1 /cwnd。与慢启动的指数增加比起来,这是一种加性增长(additive increase)。我们希望在一个往返时间内最多为cwnd增加1个报文段(不管在这个RTT中收到了多少个ACK),然而慢启动将根据这个往返时间中所收到的确认的个数增加cwnd。
下图来自CSDN,可以看到tahoe算法在产生拥塞时会将cwnd设置为1,大大降低了传输效率
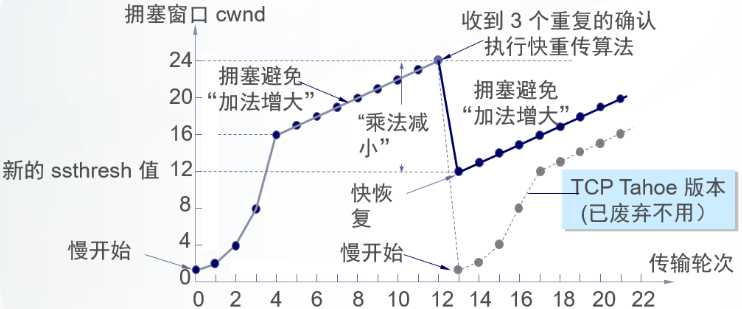
reno使用快速重传和快速恢复改进了tahoe算法:
快重传 快重传算法首先要求接收方每收到一个失序的报文段后就立即发出重复确认(为的是使发送方及早知道有报文段没有到达对方)而不要等到自己发送数据时才进行捎带确认。 接收方收到了M1和M2后都分别发出了确认。现在假定接收方没有收到M3但接着收到了M4。显然,接收方不能确认M4,因为M4是收到的失序报文段。根据可靠传输原理,接收方可以什么都不做,也可以在适当时机发送一次对M2的确认。但按照快重传算法的规定,接收方应及时发送对M2的重复确认,这样做可以让发送方及早知道报文段M3没有到达接收方。发送方接着发送了M5和M6。接收方收到这两个报文后,也还要再次发出对M2的重复确认。这样,发送方共收到了接收方的四个对M2的确认,其中后三个都是重复确认。快重传算法还规定,发送方只要一连收到三个重复确认就应当立即重传对方尚未收到的报文段M3,而不必继续等待M3设置的重传计时器到期。由于发送方尽早重传未被确认的报文段,因此采用快重传后可以使整个网络吞吐量提高约20%。 快恢复 与快重传配合使用的还有快恢复算法,其过程有以下两个要点: 当发送方连续收到三个重复确认,就执行“乘法减小”算法,把慢开始门限ssthresh减半。这是为了预防网络发生拥塞。请注意:接下去不执行慢开始算法。 由于发送方现在认为网络很可能没有发生拥塞,因此与慢开始不同之处是现在不执行慢开始算法(即拥塞窗口cwnd现在不设置为1),而是把cwnd值设置为慢开始门限ssthresh减半后的数值,然后开始执行拥塞避免算法(“加法增大”),使拥塞窗口缓慢地线性增大。
可以看到reno算法在发生拥塞避免时不会将cwnd变为1,这样提高了传输效率,快速重传和快速恢复机制也有利于更快探测到拥塞。
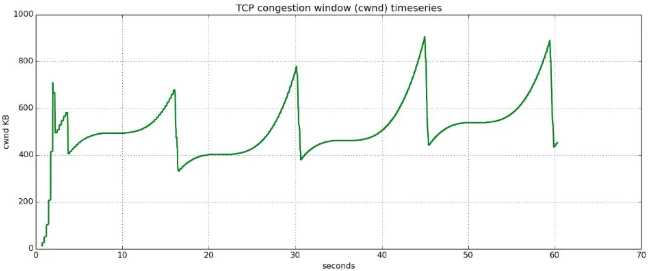
reno算法在拥塞避免阶段仍然是线性递增的,而cubic源于BIC算法,在拥塞避免阶段采用二分法查找最佳拥塞窗口,相比线性增加又增加了速率。下图来自该paper
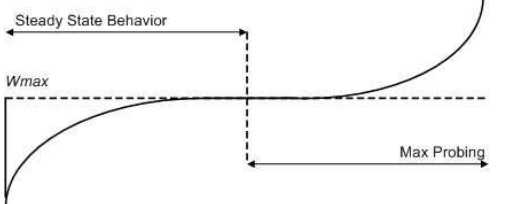
下面2张图,第一张为reno算法下的拥塞避免,第二张为cubic算法下的拥塞避免,可以看到cubic的拥塞窗口逼近速度更快
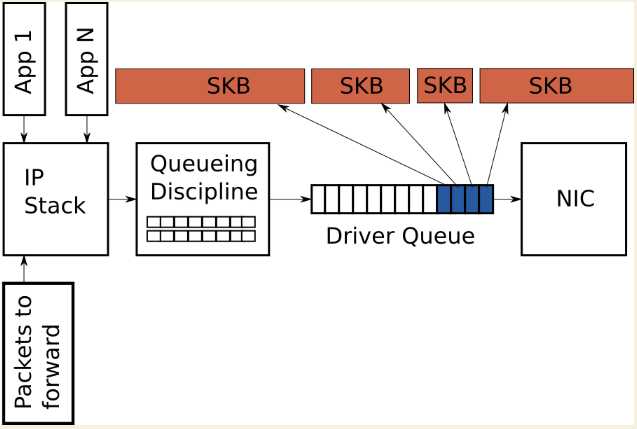
In order to avoid the overhead associated with a large number of packets on the transmit path, the Linux kernel implements several optimizations: TCP segmentation offload (TSO), UDP fragmentation offload (UFO) and generic segmentation offload (GSO). All of these optimizations allow the IP stack to create packets which are larger than the MTU of the outgoing NIC. For IPv4, packets as large as the IPv4 maximum of 65,536 bytes can be created and queued to the driver queue. In the case of TSO and UFO, the NIC hardware takes responsibility for breaking the single large packet into packets small enough to be transmitted on the physical interface. For NICs without hardware support, GSO performs the same operation in software immediately before queueing to the driver queue.
标签:paper tst 配置 引擎 基本 forms 最小 延迟 控制
原文地址:https://www.cnblogs.com/charlieroro/p/11436331.html